
ML Case-study Interview Question: Real-Time Graph Embeddings for Detecting Interconnected Payment Fraud


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with designing a fraud detection system for an organization that processes millions of digital payments daily. Multiple parties involved (buyers, sellers, and various profile assets like IP, addresses, devices) must be evaluated in real-time to stop organized, repeat fraudsters. Historic fraud patterns show malicious users creating multiple accounts with overlapping profile assets, then quickly exploiting vulnerabilities for profit. How would you design and implement a real-time graph-based solution to detect and prevent repeat fraudsters?
Provide a full end-to-end architecture.
Propose how you would handle real-time updates and manage near-instant queries.
Describe your approach to generating graph-based features and embeddings, and how they would integrate into fraud detection models.
Assume sub-second query time requirements for high-volume traffic.
Detailed Solution
A real-time fraud detection system using graph technology involves three major components: a real-time graph database, an analytics stack for advanced graph algorithms, and a method to update and consume graph-derived features on the fly.
Real-time Graph Database
It stores accounts (buyers, sellers) and profile assets (email, IP, device, address) as interconnected nodes and edges. Each payment event updates the graph. Data must refresh in seconds. Horizontal scalability is critical because transaction volumes can reach millions of queries per second. A customized query engine can be built on top of a NoSQL data layer to achieve sub-second performance. This engine should expose a standard graph traversal interface such as Gremlin, internally optimized to fetch multi-hop relationships quickly.
Real-time Data Loading
Historic data populates initial nodes, edges, and properties in an offline batch step. Each event stream (such as new account creation or transaction) triggers near real-time updates to keep the graph current. This dual loading strategy ensures the system stays fresh and can be rebuilt from scratch if needed.
Graph Query for Detection
When a new payment occurs, the system queries related buyer or seller accounts, as well as the shared profile assets. It checks known negative connections to see if the new request is part of a fraud ring. A typical query might hop from a device node to all associated accounts, then to other linked assets.
Generating Embeddings
Patterns of connections among nodes can be transformed into embeddings for machine learning models. One approach is to train node embeddings based on multi-hop neighborhood structures. An objective function for a skip-gram style model with negative sampling is often used to capture neighborhood context in low-dimensional vectors.
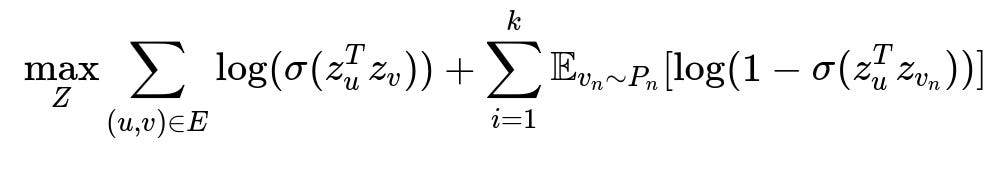
Here, z_u represents the embedding vector for node u, z_v represents the embedding vector for node v, E is the set of edges (connections), k is the number of negative samples per positive example, P_n is the noise distribution sampling those negative nodes, and sigma is the logistic sigmoid function. This objective function trains node embeddings by pushing connected nodes closer in vector space while pushing randomly chosen, unconnected nodes further away.
When generating embeddings, a mirror or auxiliary graph can precompute multi-hop neighbors so each training pass collects adjacency information in parallel. The resulting embeddings feed into fraud classifiers to help identify suspicious clusters or relationships.
Integration with Machine Learning
Embeddings and graph-based features (such as connectivity degrees, cluster memberships, or the distance to known bad actors) are fed into real-time scoring services. Models decide whether to block, allow, or flag a transaction. If an account is flagged as fraudulent, the corresponding node is updated with a risk label. Downstream transactions from linked nodes see that label in real-time.
Example of a Real-time Graph Query Engine
A Python-based service might expose a function check_connections(account_id) that runs a prebuilt Gremlin traversal. It could hop from account_id to connected profile assets, filter them by time window, then aggregate the number of previously restricted or suspicious accounts connected to those same assets. The service returns a numeric feature or a binary indicator. Downstream risk models or rules act on that result.
def check_connections(account_id):
# Example pseudo-code for real-time 2-hop traversal
# engine is a hypothetical wrapper around the Gremlin-based service
query = f"""
g.V('{account_id}').outE('links_to').inV().hasLabel('profile_asset')
.inE('links_to').outV().hasLabel('account')
.has('risk_label','bad').count()
"""
return engine.run(query)
This snippet counts how many bad accounts share a profile asset with the given account_id in two hops. Real implementations would include caching and concurrency management.
Follow-up Question 1
How would you address latency concerns when the graph grows very large, and how do you maintain sub-second query times?
Answer and Explanation
The graph storage layer should support horizontal sharding. Each shard can store a portion of the nodes and edges. An indexing layer can direct queries to the relevant shards, so queries traverse fewer partitions. An in-memory cache of hot data or repeated sub-graphs can serve frequent queries. Batch-based expansions of known negative nodes can also be cached in a distributed store to avoid repeated hops. If some queries become too large, the platform can enforce timeouts or partial responses. Finally, near real-time data ingestion uses asynchronous or streaming pipelines that do not block read queries.
Follow-up Question 2
How do you handle incremental data loading without losing data integrity when older historical data is updated or new fraud patterns emerge?
Answer and Explanation
A dual loading pipeline addresses full historical snapshots and incremental updates. If older records need re-ingestion, the offline batch pipeline reloads them while ensuring version consistency. A reference time or version tag can be stored so incremental updates only overwrite obsolete data. Validations check for mismatched node states before merging. Once the updated historical data is consistent, streaming events continue to insert new nodes and edges with no downtime.
Follow-up Question 3
Could you adapt the solution for new relationships and data fields, such as new types of assets or multi-dimensional features?
Answer and Explanation
A schema-agnostic storage approach is important. Each node and edge can have arbitrary property maps. The real-time graph system can dynamically add new node or edge labels (like “address_v2,” “device_fingerprint,” or “crypto_wallet”). The query service can interpret these new labels if the risk rules or machine learning models expect them. Backfill tasks incorporate legacy data for these new relationships. Embeddings can be retrained to account for additional edge types or node attributes, which might involve running the mirror graph process again to capture updated multi-hop neighborhoods.
Follow-up Question 4
How do you detect and handle dynamic fraud rings that repeatedly change their attributes or connections?
Answer and Explanation
Real-time updates keep the system aware of changing assets. If a malicious user creates new accounts after old ones are blocked, the new accounts quickly inherit known negative links when they reuse IP or device info. Graph analytics, such as connected components or clustering, can automatically spot ring-like structures. The repeated reappearance of the same embedded patterns or repeated negative associations triggers escalations for additional reviews. This adaptive strategy relies on continuous ingestion of event streams and ongoing re-evaluation of node connections in near real-time.
Follow-up Question 5
How can you integrate graph embeddings with advanced algorithms like Graph Neural Networks for deeper pattern analysis?
Answer and Explanation
The graph platform can export sub-graphs or adjacency lists into a specialized training environment. A Graph Neural Network architecture, such as GraphSAGE, processes node features and edges through iterative message-passing layers. The final layer outputs refined embeddings or classification logits. These embeddings contain richer structure-based context. The real-time pipeline can periodically refresh model parameters and push them to an inference endpoint, allowing each transaction check to incorporate updated GNN-based insights. Efficient batching, GPU usage, and partial graph sampling help scale these computations for large graphs.