
ML Case-study Interview Question: Virtual Assistant Intent Classification with Multi-Label Distilled Transformers


Browse all the ML Case-Studies here.
Case-Study question
An e-commerce retailer wants to build a Virtual Assistant to handle customer service requests. The Assistant must classify short text queries into multiple categories, such as delivery status or product returns. The Assistant should allow self-service for routine issues and reduce wait times. The team needs a system that can scale, handle changing data distributions, and maintain high accuracy with minimal latency. You are tasked with creating a solution architecture, choosing the right machine learning model, outlining the data pipeline, and explaining how to evaluate this system in production. Provide a full solution strategy.
Proposed Solution
Data Collection and Intent Taxonomy
Start by defining a comprehensive two-level intent taxonomy. Use historic chat logs to identify the broad categories (for example, “Returns,” “Damaged Orders,” “Delivery”) and then refine them into specific subcategories. Train a labeling team to annotate at least three times per chat sample to ensure strong consensus. Track labeler agreement to weigh confidence for each data point.
Model Architecture Choice
Fine-tune a transformer-based architecture to handle the variety and ambiguity of customer queries. Base models like BERT are pretrained on large corpora. For faster inference, use a smaller distilled transformer model.
Multi-Label Approach
Each utterance can have two labels (broad and specific intent). Treat this as a multi-label classification problem. Multiply the training data effectively by the number of labelers, but weight labels by inter-rater agreement.
Loss Function
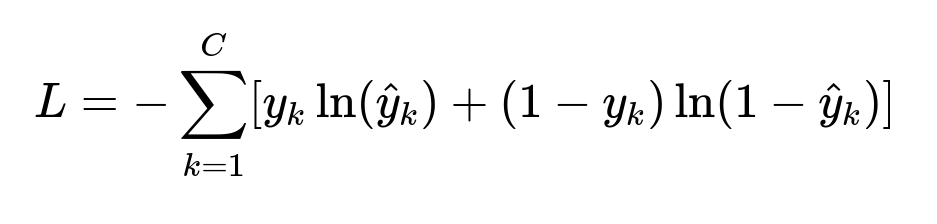
Here, C is the number of possible intent classes, y_{k} is 1 or 0 indicating if the sample belongs to class k, and hat{y}_{k} is the model’s predicted probability for class k. This formula is the binary cross-entropy applied across each class output.
Training Details
Use an optimizer like Adam with weight decay. Keep a fully connected output layer on top of the distilled transformer model. Set thresholds per class to maximize F1 score. Check speed requirements by testing inference times on typical hardware. If inference is too slow, transition to a smaller variant or quantize the model.
Production Infrastructure
Build a microservices-based platform that manages stateful conversations, calling the model for intent classification, then routing the predicted intent to a resolution workflow. Store logs of predicted intent and user success metrics in a central database for monitoring and continuous improvement.
A/B Testing
Release the Assistant to a subset of traffic. Evaluate real-time accuracy and measure how customers engage with it. Compare predicted intents to actual outcomes. Observe distribution shifts in user queries. Track latency metrics (for example, keep inference below 100 ms) to ensure conversation flow.
Adaptation to Distribution Shifts
If the Virtual Assistant is introduced in new page types or user contexts, gather fresh utterances. Monitor new or underrepresented intents. Retrain or fine-tune the model on recent data if the performance drops. Keep track of average utterance length changes because that can affect prediction accuracy.
Example Code Snippet
import torch
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased",
num_labels=NUM_INTENT_CLASSES)
utterance = "I need to set up a return for a damaged table."
inputs = tokenizer(utterance, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
probs = torch.sigmoid(logits)
predicted_intents = (probs > 0.5).nonzero(as_tuple=True)[1].tolist()
print(predicted_intents)
Model inference on new text uses a threshold to decide which intents to assign. For multi-label classification, interpret multiple positive predictions if probabilities exceed the chosen threshold.
Possible Follow-Up Questions
How do you choose an optimal threshold per intent class?
Threshold tuning is guided by F1 score maximization on a validation set. Evaluate different threshold values for each class. For high-volume classes, track precision and recall to ensure you don’t over-predict or under-predict. Example approach: for each class, sweep threshold from 0 to 1 in small increments and record F1. Pick the threshold that yields the highest F1.
Why not train separate models for each intent category?
Maintaining many single-task models complicates deployment and version control. A single multi-label model can learn shared representations across similar classes, which often improves performance. It also simplifies serving infrastructure. Separate models might help if data distributions differ drastically or if certain categories require specialized architectures. But that adds operational overhead.
How would you address cases where very short utterances degrade accuracy?
Consider building a fallback if text length is below a threshold. Prompt the user for more context or run a secondary clarifying flow. Another approach is to incorporate user context (for example, what page they were on). Fine-tune on specifically curated short utterance data. Incorporate subword tokenization that handles minimal text input.
How do you detect new intents that were not in your training set?
Deploy an out-of-distribution (OOD) detector. If the model’s confidence is uniformly low or all classes remain below a threshold, predict an “unrecognized” class. Log these to investigate emerging intents. This helps refine the taxonomy over time. Periodically review these logs and add new classes once they appear frequently.
Why might inference speed be slow and how do you optimize it?
Transformer models involve many parameters. On large architectures, high parameter count leads to slower GPU or CPU inference. Optimize by using smaller distilled variants or by quantizing weights to lower-precision formats (for example, int8). Cache repeated operations like tokenization or partial embeddings if requests share similar text. Profile hardware usage and consider batch processing if latency constraints allow.
How do you measure success beyond classification accuracy?
Track resolution rate, average handling time, and customer satisfaction metrics. Study if the Virtual Assistant resolves routine requests autonomously and how often customers escalate to a human agent. Monitor user feedback through post-chat surveys. Low classification error alone won’t guarantee a better user experience if the resolution flow is suboptimal.