
ML Case-study Interview Question: LLM-Powered Automated Column Tagging for Sensitive Data Governance


Browse all the ML Case-Studies here.
Case-Study question
A tech platform processes massive datasets generated from diverse services, each containing large numbers of data entities such as database tables and streaming schemas. They must classify columns that may contain sensitive user or partner information (for example, personal identifiers, contact data, or business metrics) to enforce fine-grained data access controls. Manual classification is too slow and prone to errors. They built an orchestration service to automate tagging each column of a data entity with specific labels (for example, <Personal.ID> or <None>). They used a Large Language Model (LLM) to generate these tags by prompting it to interpret column names and table names. Data owners verify these tags. The objective is to reduce manual tagging effort while maintaining high accuracy. How would you design such a system, manage its scalability, ensure reliable classification, handle user-verification workflows, and refine the process for better performance?
Detailed Solution
Overview of the Objective
They needed a system that automatically tags data entities with metadata reflecting content sensitivity. The tags inform enforcement layers for data access policies. The solution involves an LLM to interpret textual signals from table names and column names, then assign the most suitable tags. The workflow must be scalable, cost-effective, and accurate enough to minimize human review.
System Architecture
An orchestration service receives classification requests from data platforms. The service batches these requests, applies rate limits, calls one or more classification engines (including the LLM), and publishes the resulting tags for verification. Verified tags are stored as metadata in downstream platforms.
Prompt Engineering for LLM
They used carefully designed prompts to guide the LLM to return structured JSON. The LLM is asked to interpret each column name in the context of a table name and assign a tag from a predefined library of data labels (for instance, <Personal.Contact_Info> or <None>). The prompt includes:
You are a database column tag classifier, your job is to assign the most appropriate tag based on table name and column name.
Assign one tag per column. If it is unclear or does not match any known tag, assign <None>.
Output Format:
[{
"column_name": "",
"assigned_tag": ""
}]
This prompt ensures the LLM output can be parsed by downstream workflows. The few-shot technique helps by providing sample input-output pairs, clarifying the correct response format.
Core Classification Principle
They want to identify the tag y from a finite set Y, given an input x. The classification principle can be expressed as:
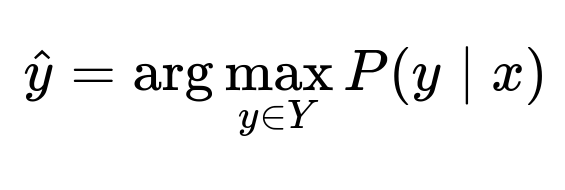
Here:
x is the textual information (for example, table name, column name).
y is a possible tag label (for example,
<Personal.ID>,<None>).P(y | x) is the probability that label y is correct given x.
The LLM approximates P(y | x) by using its language understanding of domain-specific text. The tag with the highest confidence is output.
Data Verification and Iteration
Users are prompted to review the tags assigned by the LLM. This feedback loop identifies incorrect assignments. The orchestration service tracks modifications and flags common misclassifications to improve the prompt or adjust instructions. Over time, the reliance on human verification may decrease if confidence scores are introduced.
Scalability Considerations
The system handles thousands of data entities daily. It batches classification jobs to prevent hitting LLM input or token limits. A rate limiter ensures service calls do not exceed cloud provider quotas. If input text is too large, the system trims less important columns or splits the request into multiple chunks.
Cost Management
Costs depend on the volume of tokens processed by the LLM. They found the cost-per-entity to be acceptable for large-scale usage. If usage grows, they can optimize the prompt, reduce token usage, or selectively route only high-risk entities to the LLM.
Practical Implementation Steps
Platforms trigger classification requests.
Orchestration service aggregates columns from multiple data entities into mini-batches.
LLM processes each batch under carefully engineered prompts.
LLM returns structured tags. The system writes them to a queue.
Data owners review the tags in a weekly or on-demand cadence.
Confirmed tags are used downstream for enforcing data policies.
Example Code Snippet
A simplified version of calling the LLM in Python might look like:
import requests
def classify_columns(data_entity):
prompt = f"""
You are a database column tag classifier...
...
"""
response = requests.post(
"https://api.cloudprovider.com/v1/llm",
headers={"Authorization": "Bearer <YOUR-API-KEY>"},
json={"prompt": prompt, "max_tokens": 500}
)
return response.json()
This outlines how the classification logic sends the prompt to a cloud LLM endpoint, waits for a response, and returns parsed labels.
Potential Follow-Up Questions
How do you ensure high accuracy of classification?
Frequent user feedback is important. Whenever data owners fix tags, that feedback is tracked to see if the prompt or rules need refinement. Including examples and edge cases in the prompt clarifies ambiguous situations. Introducing a confidence threshold from the LLM can filter uncertain tags for extra review. Over time, prompt improvements and a curated knowledge base of domain-specific phrases reduce false positives or false negatives.
How would you handle edge cases such as very long schema descriptions or special characters?
Splitting large schemas into smaller batches prevents token overflow. Each batch includes only enough columns to stay within context limits. For special characters or domain-specific tokens, instructions in the prompt clarify they should be treated the same as normal text. If the LLM fails to parse them, fallback rules or smaller chunks help. User feedback is especially crucial for these atypical fields.
Why use an LLM instead of a traditional regex or classical machine learning approach?
Regex patterns may result in many false positives. Classical machine learning requires lengthy model training and labeled data. LLMs can interpret domain text contextually, reducing the need for large labeled datasets. Data governance teams can quickly revise text-based rules by editing prompts. This agility outperforms rigid methods when schema naming conventions change or new field types appear.
How do you handle extremely sensitive data like national IDs or financial identifiers?
They define specialized tags for critical identifiers. The LLM receives instructions to be cautious with these tags and only assign them if the column name strongly indicates that information. Business logic can incorporate stricter verification steps for tags that imply highly sensitive data. The combination of user verification and strict tagging guidelines adds additional safeguards.
If the classification mistakes appear repeatedly in a certain domain, how do you improve?
They analyze misclassifications and enhance the prompt to address repeated issues. If the mistakes relate to domain-specific naming, more real examples or clarifications are added. If that is insufficient, a lightweight feedback mechanism can store known mappings (for instance, certain column names always map to <Personal.Contact_Info>). Ongoing iteration integrates these fixes into the prompt or fallback rules.
Could this approach extend to classifying entire tables or streams beyond just columns?
Yes. The same LLM approach can classify higher-level entities by passing table metadata, sample column names, or sample data if needed. They can also combine column-level tags to assign aggregated tags at the table or stream level. This helps manage data sensitivity or discover broader data patterns.
How would you measure success in this project?
They track two key metrics:
User adoption: Data teams rely on the system instead of manually tagging.
Accuracy: Fewer user-initiated corrections over time, demonstrating the LLM’s improved reliability. They also watch time savings—the reduced hours spent on manual governance tasks.
What if the LLM’s version changes or is deprecated?
Maintaining prompt versioning is critical. They store which prompt version was used for each classification batch, along with the system outputs. If an LLM upgrade changes how it interprets text, a controlled rollout strategy can compare accuracy before fully migrating. This mitigates sudden performance regressions.