
ML Case-study Interview Question: Personalizing Business Traveler Hotel Search with Random Forest Ranking


Browse all the ML Case-Studies here.
Case-Study question
A multinational travel technology company serves business travelers. They want to personalize hotel search results to help users find their preferred properties faster and increase booking efficiency. They have historical data (bookings, user preferences, user profiles, hotel attributes), and they plan to build a machine learning ranking system to predict which hotels a given user is most likely to book. How would you design and implement a ranking model that uses personalization and historical data to improve top-ranked booking relevance? How would you measure success?
Detailed In-Depth Solution
Problem Understanding
Users frequently rebook the same hotels or hotels with similar attributes (price, amenities, brand loyalty, distance). Corporate travelers often look for specific amenities or negotiated rates, so searching becomes time-consuming if relevant hotels are buried under irrelevant options.
Data Sources and Features
They aggregate data from multiple sources:
Historical bookings to capture personal and coworker preferences.
Company-negotiated rates and loyalty programs.
Hotel data: amenities, star ratings, and average user ratings.
Search context: distance from a specific address, airport code, or point of interest.
They process tens of millions of records spanning up to three years to capture both recent patterns and pre-pandemic preferences. They retrieve data from distributed systems like Amazon Web Services Redshift, Amazon Simple Storage Service, Snowflake data lake, and store or process them using Amazon Elastic MapReduce Spark clusters.
Model Formulation
They treat it as a supervised learning problem to classify whether a user will book a specific hotel or not. The hotel list is then sorted by the predicted booking probability. Gradient Boosting Trees and Random Forest models are tested.
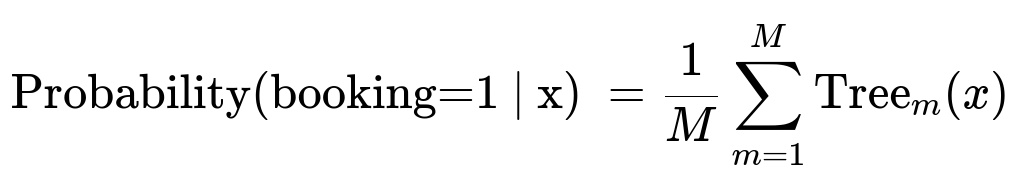
Above, M is the total number of decision trees. Each Tree_{m}(x) outputs a probability for booking. They average these probabilities to get the final score.
Model Training
They split the data into training and validation sets, ensuring that they preserve temporal order where possible. For each user–hotel pair, they label it as booked or not-booked. They feed user, hotel, and search context features into the model. They train the Random Forest using Amazon Elastic MapReduce Spark clusters. They evaluate using metrics like area under the ROC curve and top-k ranking performance.
Deployment
They package the trained model as an artifact using the MLeap library. They deploy it to production environments running on Kubernetes, ensuring the system can pull fresh features daily. The model score is computed in real time for each hotel retrieved during a user’s search.
Performance and Metrics
They measure:
How often the final booking lies in the top ranks (top 1, top 3, and top 10).
Search-to-booking conversion rate.
Time to complete a booking. They run online A/B experiments, comparing the personalized ranker to a legacy non-personalized approach. They see a measurable improvement in top-ranked selections and a shorter booking time.
Model Interpretability
They examine feature importance in the tree-based model. The top features typically include:
User’s personal booking history at that specific hotel.
Company-wide booking frequency at that hotel.
Distance from the search location.
Negotiated rate indicators.
Overall popularity of that hotel.
Model Monitoring
They track metrics daily. A data pipeline summarizes how many users are booking within top positions. They also track potential shifts in travel patterns. When they notice abrupt changes in booking distribution, they investigate for data pipeline or model drift issues.
Follow-Up Questions and Detailed Answers
What strategies handle cold-start travelers or new hotels that lack historical bookings?
Use hotel similarity or content-based features. Factor in star category, amenity attributes, location, and brand affiliation. Combine with aggregated behavior of similar users or coworkers. Create a fallback strategy that uses general popularity and distance-based relevance.
Why did they prefer a Random Forest model over Gradient Boosting Trees or more advanced ranking approaches?
Random Forest performed well in online A/B tests and delivered consistent gains in ranking quality. Also, it was straightforward to deploy. Learning-to-rank or collaborative filtering approaches might improve performance further, but the team found Random Forest sufficient at that time. They continue to test advanced approaches.
How do you handle potential bias when a user repeatedly sees the same top hotels and never explores other options?
Inject subtle diversity into the ranking. Use a re-ranking step to place relevant but less frequently viewed hotels slightly higher. This is often done by calibrating final scores or imposing a small penalty for overexposed properties.
How do you update the model when booking patterns change abruptly (for instance, pandemic-related disruptions)?
Shorten the training window to emphasize more recent data. Retrain or fine-tune frequently to capture shifts. Include data from older periods if it remains relevant, but weight it less. Monitor performance metrics daily or weekly to detect anomalies.
What would you do if the model puts too much emphasis on distance, ignoring other features?
Perform feature selection or regularization. Investigate partial dependence plots to see how the model interacts with the distance feature. If needed, adjust hyperparameters or re-balance training data. Evaluate performance trade-offs in A/B tests.
When ranking is personalized, how do you measure fairness across different users or hotels?
Design fairness criteria or constraints. Track distribution of exposures across hotels. Evaluate whether certain types of hotels are systematically under-ranked. If fairness issues arise, add constraints in the ranking or incorporate fairness metrics into the optimization.
Explain the daily feature refresh and how it ensures new bookings or negotiations are reflected.
They store aggregated historical counts and preferences in a feature table. A daily batch job updates these counts for each user and hotel. The model scoring service reads from this updated store. This ensures new bookings or updated negotiated rates appear in features quickly.
Why do they specifically measure top-1, top-3, and top-10 booking ratios?
Frequent corporate users often select hotels from the first few results. They rarely scroll far. Tracking the fraction of bookings happening in the top 1, 3, or 10 positions shows how effectively the model elevates relevant hotels.
If a property is out-of-policy for a user, does the model still rank it highly?
It can, if historical behavior shows the user still books that property despite policy. Some companies override out-of-policy for cost or convenience reasons. The final display might mark it as out-of-policy, but high personal preference can still lift its rank. The system also respects strict hard-policy rules if mandated by the company.
How do you handle real-time performance concerns when computing scores for hundreds of hotels per query?
Keep feature data cached in memory or fast lookups. Use a containerized service that loads the model and feature store once, then responds quickly to queries. Parallelize scoring across multiple hotels. Random Forest is efficient if properly optimized.
How do you prevent overfitting, especially when travelers might have repeated preferences?
Perform cross-validation that preserves user splits or time splits. Limit the maximum depth of trees. Prune features that rarely generalize. Examine performance on users who differ from the training set. Regularly monitor key metrics for signs of overfitting.
Could combining classification probability with a re-ranking step based on user-specific constraints improve results?
Yes. After the model outputs a booking probability for each hotel, a second pass can incorporate policy constraints, minimum star ratings, or brand loyalty constraints, then re-score and rank. This yields a final ordering better aligned with business rules while keeping personalization.
Do you need continuous retraining, and how do you automate that?
Yes. The team often retrains periodically, such as weekly or monthly. They automate the pipeline that pulls fresh data, performs validation, and tests metrics. If metrics fall below a threshold, they investigate for data or model issues. On success, the new model is released to production.
Would an alternative approach like matrix factorization for implicit feedback (booked vs. not-booked) help?
Yes. Collaborative filtering can capture latent user-hotel factors. It is an option if you have sufficient user-hotel interactions. Hybrid methods that merge collaborative filtering with contextual features might improve personalization. They plan to test these in the future.
If the model shows improved ranking but no net gain in bookings, is that acceptable?
It might still be acceptable because user experience is improved (faster bookings). Faster user journey can reduce support costs and improve user satisfaction. If the company wants higher revenue, they may need to incorporate upselling or cross-selling signals as well.
(end)