
ML Case-study Interview Question: Personalized On-Device TTS: Fine-Tuning Pretrained Models with Noisy, Limited User Data


Case-Study question
You are asked to design a text-to-speech (TTS) system that enables a user at risk of losing their ability to speak to generate a synthesized voice that sounds like their own. The system must work with only 150 recorded sentences from the user, handle background noise in real-life recording environments, and run directly on a device without server-side processing. Propose a plan to build such a personalized TTS system. Detail your model architecture choices, pretraining strategy, on-device fine-tuning approach, data augmentation steps, and quality assurance methods.
Detailed Solution
A practical solution requires multiple stages: a personalized TTS pipeline, pretrained models for both acoustic and vocoder modules, an on-device fine-tuning procedure, and a speech enhancement process to handle noisy input recordings.
Personalized TTS Pipeline
A TTS pipeline has three main blocks: text processing, acoustic modeling, and vocoder. Text processing turns text into phonemes or other linguistic units. Acoustic modeling predicts Mel-spectrogram features from phonemes. The vocoder converts these spectrogram features into raw speech waveforms. Personalizing the pipeline means adapting both the acoustic model and the vocoder to the target speaker’s voice.
Model Architecture Choices
Researchers often use FastSpeech2-style acoustic models. It predicts duration, pitch, and energy for each phoneme and converts phoneme embeddings into Mel-spectrogram frames. A WaveRNN-style vocoder then synthesizes the time-domain waveform. Both models can be pretrained on a large multi-speaker dataset, then fine-tuned to the new speaker.
Pretraining and Loss Function
During pretraining, the model learns universal speech patterns by training on many speakers. That helps the system generalize to new voices with limited fine-tuning data. The acoustic model typically minimizes L1 or mean-squared error between predicted and ground-truth Mel-spectrogram frames.
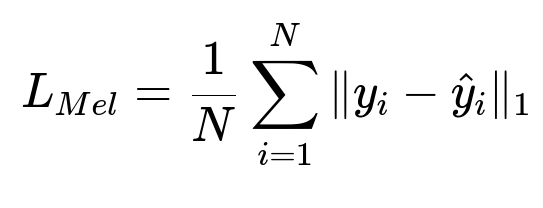
Here y_{i} represents the reference Mel-spectrogram frame, and \hat{y}_{i} represents the predicted Mel-spectrogram frame. N is the total number of frames.
The vocoder often uses a separate loss, such as a combination of reconstruction loss and adversarial objectives. Once the system is pretrained with many speakers, it is ready for on-device adaptation.
On-Device Fine-Tuning
Users record 150 sentences, producing roughly 10 minutes of speech. That data is used to fine-tune the acoustic model’s decoder and variance predictors, and to adapt the vocoder. This stage runs overnight while the device is locked and on Wi-Fi. By next morning, the user has a personalized TTS model that can generate speech with their vocal characteristics.
Handling Noisy Recordings
Real-world recordings can include background noise like traffic or other people’s voices. This noise can hurt model quality. A speech enhancement pipeline can be applied to filter or remove noise before fine-tuning:
Screen out extremely noisy samples by measuring signal-to-noise ratio.
Use a voice isolation method to remove background sounds.
Enhance Mel-spectrogram frames with a trained U-Net model to remove remaining noise.
Recover the final audio with a specialized waveform generator (for example, a Chunked Autoregressive GAN).
These augmentation steps improve clarity in the synthesized voice.
Final Results
Such a system achieves near-real-time speech generation and maintains speaker similarity scores high enough that listeners perceive the synthesized voice as the user’s own. Mean opinion scores typically remain close to the user’s original vocal quality. On-device training preserves privacy because audio data never leaves the device.
Follow-Up Question: How do you ensure the personalized TTS system remains robust if a user can only record data in noisy environments?
A robust speech enhancement module is essential. High noise recordings go through voice isolation or noise gating and additional filtering. If any recording is too degraded, it is discarded by measuring the signal-to-noise ratio. The U-Net-based Mel-spectrogram enhancement model helps refine features further. The vocoder then recovers cleaner waveforms. These steps produce clearer input features for the fine-tuning stage, making the final model more resilient to noise.
Follow-Up Question: What optimizations are needed to fine-tune both the acoustic model and vocoder on a mobile device without excessive computational cost?
Training smaller architectures and using efficient layers (dilated convolutions instead of large transformers) reduces memory requirements. Mixed-precision training (for example, bfloat16 with fp32 accumulation) lowers memory load and speeds up backpropagation. Batching short audio segments also helps ensure faster iteration times. Pruning or knowledge distillation can further reduce model size. Once training completes, the final adapted model can run in real time on device hardware.
Follow-Up Question: How do you measure the similarity between the synthesized voice and the target speaker’s voice?
A standard way is a subjective listening test with a voice similarity (VS) score. Listeners compare pairs of utterances: one from the target speaker’s real voice, one from the synthesized voice. They rate similarity on a numerical scale (for example, 1 to 5, where 1 means definitely different and 5 means definitely the same). Mean Opinion Score (MOS) can also be measured for perceived audio quality. Automated speaker verification methods offer objective metrics by checking if the synthesized voice matches the user’s speaker embedding.
Follow-Up Question: How would you handle user privacy concerns?
All training happens on device. Recorded audio never leaves local storage, so sensitive voice data is not uploaded to external servers. Model weights are updated in local memory and remain encrypted on the device. This approach addresses privacy by design: the entire personalization process is self-contained.
Follow-Up Question: Why is it important to fine-tune the vocoder as well as the acoustic model?
Fine-tuning only the acoustic model with a universal vocoder can degrade quality. Unusual prosody, audio artifacts, and glitchy waveforms may appear. A dedicated vocoder fine-tuned to the user’s acoustic features captures subtle prosodic and timbral patterns. This ensures more natural and speaker-specific waveforms.
Follow-Up Question: Could you adapt this solution if the user speaks a language not included in your pretraining dataset?
Yes, but additional multilingual or language-specific data would be needed during pretraining. The acoustic model can incorporate language-dependent phoneme representations. If the new language is drastically different, additional domain adaptation steps might be required, such as refining the text-processing module for correct phoneme output. The same approach of on-device fine-tuning still applies, but the initial model would need relevant linguistic knowledge.
Follow-Up Question: What if the user requires faster-than-real-time synthesis?
Fast generation is aided by parallel acoustic models like FastSpeech2, which predict Mel-spectrogram frames without autoregressive decoding. Vocoders such as WaveRNN can also be optimized with smaller hidden dimensions or pruning. Hardware acceleration (like GPU or specialized Neural Engine units) can further boost throughput, allowing sub-real-time TTS.
Follow-Up Question: How do you deal with potential accent or dialect variations during pretraining?
Pretraining on a dataset with diverse speakers, accents, and dialects prepares the model to handle varied pronunciations. Embedding speaker IDs as part of the acoustic model’s training helps the network learn generalized accent representations. Fine-tuning on the user’s data further aligns the output with their unique accent.
Follow-Up Question: Could this approach scale to other modalities like singing or emotional prosody?
Yes. A similar pipeline can be extended by collecting training samples that showcase emotional or musical ranges. The acoustic model would learn pitch and timbral variations corresponding to singing or expressive speech. Vocoder training would then adapt to more complex dynamics and timbre patterns.
Follow-Up Question: How do you measure success in an interview setting when asked about such a system?
Clear, methodical explanations of each TTS pipeline component, the reasoning behind on-device fine-tuning, and how to handle data constraints are key. Demonstrating understanding of speaker-adaptive modeling, privacy considerations, and noise reduction indicates strong familiarity with real-world TTS challenges. Exhibiting knowledge of relevant architectures (FastSpeech2, WaveRNN, U-Net for spectral enhancement, CarGAN for waveform recovery) and explaining how to optimize them for mobile devices shows depth of expertise.