
ML Case-study Interview Question: Scalable Cross-Service Fraud Detection Using Relational Graph Networks (RGCNs).


Browse all the ML Case-Studies here.
Case-Study question
A large multi-service platform is expanding into various new products. Fraudsters exploit shared devices and other common connections to commit new types of fraudulent activity as each new service is introduced. You need to design a fraud detection solution that generalizes well across diverse business lines without needing to rebuild models whenever a new fraud pattern emerges. You must ensure the system scales to millions of entities and provides robust detection for both known and unknown fraud. Propose a complete approach, including data representation, algorithms, infrastructure, and real-time considerations.
Detailed Solution
A general-purpose fraud detection solution must capture correlations between entities from multiple businesses. A graph structure links accounts, devices, addresses, and any other shared nodes, giving a powerful way to spot organized networks of bad actors. Fraudsters often share physical items or IDs. This means they tend to form dense clusters, and those strong connections help detect both known and unknown fraud patterns.
Graph Modeling
Represent each entity (users, devices, merchants, addresses) as nodes. Add edges to link any shared attributes (for example, the same phone device or IP address). Store relevant node features (like historical behaviors and domain-specific signals). Store edge information if it matters (like frequency of usage or transaction counts).
Semi-Supervised Graph Learning
Use a Relational Graph Convolutional Network (RGCN). This architecture processes multi-relational data (different edge types) to produce embeddings for every node. It propagates node features along edges, so interconnected fraudulent nodes reinforce each other’s suspicion scores, and isolated genuine nodes stand out. Even with few labels, the structural correlation on the graph boosts performance.
Below is the key RGCN update formula in big font:
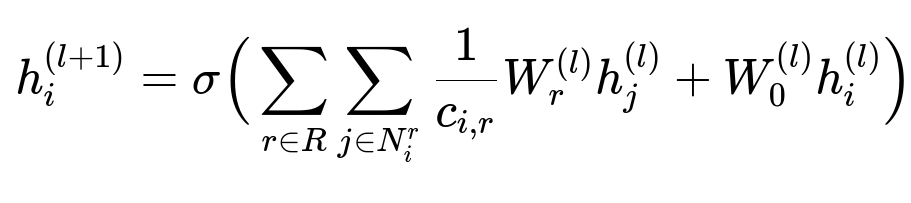
Where:
h_i^{(l)} is the embedding of node i at layer l.
R is the set of relation types (for example, device-sharing or address-sharing).
N_i^r is the set of neighbors of node i under relation r.
c_{i,r} is a normalization factor (like the out-degree for the specific relation).
W_r^{(l)} and W_0^{(l)} are trainable weight matrices for relation r and the self-connection.
sigma(.) is a nonlinear activation function.
At each layer, the model aggregates neighbor embeddings. Repeated application of this update step enriches node representations with local neighborhood information.
Training Procedure
Collect a labeled subset of fraudulent and genuine entities. Split them into training and validation. Train the RGCN by minimizing a suitable loss function (for instance, cross-entropy) on the labeled portion. Unlabeled nodes still contribute their structural context, guiding the learned embeddings. This semi-supervised scheme works well when few labeled examples exist and unknown fraud patterns need discovery.
Practical Guidance
Use fewer than three graph convolution layers to avoid over-smoothing. Incorporate domain knowledge through node features: device risk scores, past transaction patterns, or aggregated stats. These features merge with the structural signals in the RGCN, enhancing precision.
Explaining Results
Graph visualizations clarify why certain clusters have high fraud scores. Fraud rings share many edges, while genuine users have sparse connections. Investigators see suspicious subgraphs that stand out as device-sharing webs.
Example Code Snippet
Below is a simplified approach in Python (using a generic graph library). The code shows how you might set up a multi-relational graph and apply a graph convolution layer. Explanations follow inline.
import torch
import torch.nn.functional as F
from torch_geometric.nn import RGCNConv
class RGCNModel(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels, num_relations):
super().__init__()
self.conv1 = RGCNConv(in_channels, hidden_channels, num_relations)
self.conv2 = RGCNConv(hidden_channels, out_channels, num_relations)
def forward(self, x, edge_index, edge_type):
x = self.conv1(x, edge_index, edge_type)
x = F.relu(x)
x = self.conv2(x, edge_index, edge_type)
return x
# x: node feature matrix
# edge_index: list of edges
# edge_type: relation type for each edge
# out: final embeddings or classification logits
The first RGCNConv layer aggregates neighbor features by relation type and transforms them into a hidden representation. The second layer refines these embeddings or produces classification logits (fraud vs. genuine).
Real-Time Inference
Real-time graph updates can be resource-intensive. Accumulate recent transactions in mini-batches and update node features or add edges in intervals. Cache partial embeddings to reduce latency. A typical compromise is near real-time predictions based on the latest known graph state, then refresh embeddings periodically.
Potential Follow-Up Questions
How do you handle unseen fraud patterns with minimal labeled data?
Semi-supervised graph learning propagates labels across connected components. A few known fraud labels help the RGCN assign high suspicion scores to nearby unknown entities. Structural features, such as device sharing or repeated network paths, expose new fraud rings even if they were not in the initial training set. Feature engineering (like frequency-based attributes) adds signals that help the graph model group unknown fraudsters.
How can you reduce noise from unreliable connections like public IP addresses?
Incorporate metadata about edge reliability. For example, a public IP address is often used by many legitimate users. Introduce an attention or weighting mechanism in the graph convolution step that lowers the importance of suspicious edges and amplifies more trustworthy edges. Track the historical ratio of fraud to genuine behavior on each edge type. High-noise edges get lower weights during message passing.
How do you make the model explainable to investigators?
Visualize the final embeddings or cluster assignments. Show dense subgraphs of accounts that share devices or addresses. Provide a short text-based explanation: “Node X has strong links to known fraud ring members.” Investigators can click through an interface showing which neighbors triggered the node’s high fraud probability. These insights are more direct than opaque black-box scores.
How do you manage large-scale graphs and keep training efficient?
Partition the graph into manageable subgraphs and apply minibatch training. Tools like PyTorch Geometric or DGL offer sampling approaches (GraphSAGE-style neighborhood sampling) that speed up training. Distribute the computation over multiple machines if necessary. Use time-slicing to refresh sub-partitions of the graph so that each portion is updated while the rest remains accessible for inference.
How do you improve feature initialization for nodes lacking semantic signals?
Rely on self-supervised pre-training. Create proxy tasks (like predicting if two nodes share many mutual neighbors) to generate embeddings without labeled data. Store these pretrained embeddings as initial features. Then fine-tune the RGCN on your main fraud detection objective.
How do you measure the effectiveness of this approach?
Monitor both label-based metrics (Area Under the Receiver Operating Characteristic, precision-recall) and business metrics (loss avoided, false positives flagged). Compare the performance against simpler baselines like rule-based filters or decision trees. Keep track of how many new fraud cases are caught by structural detection that would not have been caught by older methods.
How do you address class imbalance in fraud data?
Oversample minority fraud examples or undersample major class examples to balance training. Alternatively, experiment with focal loss or weighted cross-entropy to assign higher cost to misclassifying minority fraud labels. Graph-based approaches also help because suspicious clusters amplify each other’s risk, partially offsetting label scarcity.
How would you handle merging data from multiple business lines with unique attributes?
Standardize node and edge schemas. Treat each business line’s entities as a distinct node type with custom features. Map cross-business relationships into edges. For example, a user node might have an edge to a merchant node in one business line and to a driver node in another. The RGCN can process multi-relation data, so it naturally extends across multiple verticals.
How do you maintain performance if fraudsters adapt or try to appear legitimate?
Continually retrain with new data. Encourage continuous labeling from risk teams to capture emerging behaviors. Periodically run cluster detection algorithms to spot suspicious subgraphs. Fraud rings sharing a device or an address eventually reveal themselves in transaction logs or complaint data, and that new evidence seeds further RGCN training cycles.
Final Thoughts on Deployment
Graph-based fraud detection scales to unknown fraud patterns by leveraging shared connections and structural features. Semi-supervised RGCN models preserve accuracy even when labels are sparse. Attention-based mechanisms, dynamic graph updates, and thorough feature engineering ensure it remains robust, explainable, and adaptable against evolving threats.