
ML Case-study Interview Question: ML-Driven Dynamic Order Release: Balancing Driver Wait Times and Food Freshness


Browse all the ML Case-Studies here.
Case-Study question
You are responsible for designing a system at a large-scale food delivery platform to reduce the time that delivery drivers (Dashers) spend waiting at restaurants. There is also a need to ensure that food does not sit too long and lose quality. Restaurants can either start preparing orders as soon as they receive them or wait until the Dasher is close by. Historically, some restaurants waited until the Dasher arrived, causing longer Dasher wait times, but protected the freshness of the food. A new flow, known as Auto Order Release (AOR), was introduced where restaurants hold an order until the Dasher is within a certain distance. This distance was hard-coded on a store-by-store basis.
Your goal: design an approach that dynamically decides whether to release an order to the kitchen immediately or hold it until the Dasher is near, optimizing Dasher wait times without letting the food sit too long. Describe the system design, data inputs, modeling approach, and the steps you would take to implement and measure this solution. Outline how you would go from a simple heuristic-based method to a Machine Learning model that can scale, while ensuring minimal disruption to merchant operations and preserving food quality.
Detailed Solution
Overview
A good starting point is to define the core metrics. The main ones are Dasher wait time and food wait time. Reducing Dasher wait time requires releasing orders early enough so Dashers are not idling at restaurants. Avoiding too much food wait time ensures food stays fresh. A careful balance is needed.
Key Mathematical Formulas
We can formalize these wait times as follows:
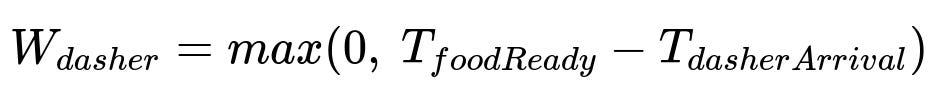
Dasher wait time (W_dasher) is the amount of time the Dasher waits at the restaurant if the food is not yet ready. T_foodReady is the restaurant’s actual completion time. T_dasherArrival is the Dasher’s arrival time at the restaurant.
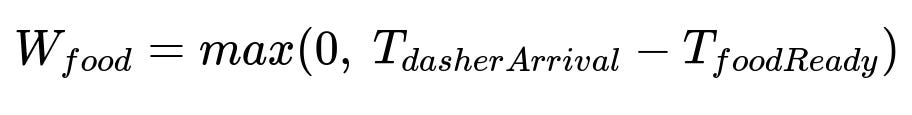
Food wait time (W_food) is the amount of time the prepared food waits on the counter if the Dasher is not yet there to pick it up.
Both times are in minutes or seconds. T_foodReady and T_dasherArrival are predictions coming from models or heuristics.
Step-by-Step Methodology
Business Analysis and Problem Definition Focus on which merchants have chronic Dasher wait issues. Determine when restaurants typically start food preparation. Some do so immediately, others wait for the Dasher’s arrival. Investigate how these patterns affect overall customer experience.
Initial Heuristic Approach (Minimum Viable Product) Build a simple rules-based logic:
If the order is large or arrives during peak times, release it to the kitchen immediately.
Otherwise, hold the order until the Dasher is within a fixed distance. This approach needs an architecture that can dynamically switch between immediate release or delayed release per order. Set up data pipelines to log outcomes, including differences in Dasher wait time and any changes in food wait time.
Experimentation and Early Insights Deploy the heuristic in a controlled experiment to confirm whether it reduces average Dasher wait time without causing food to sit too long. Gather metrics on:
Actual Dasher wait time
Overall delivery time
Food wait time Positive early results can provide stakeholder buy-in and justification for a more sophisticated predictive model.
Machine Learning Model Integration Replace or augment the heuristic with an ML model:
Use a model that predicts restaurant prep time more accurately under this new flow. Train on features such as order size, restaurant capacity, historical prep times, time of day, and more.
Combine it with an existing model for Dasher arrival times. Or build a specialized arrival-time model if necessary.
A popular choice is a gradient boosting model. A LightGBM model can handle large feature sets efficiently.
Architecture for Real-Time Decisions Connect the ML service to the order flow:
When an order is placed, call the ML model to estimate T_foodReady and T_dasherArrival.
Use these predictions to decide if an immediate or delayed release strategy is optimal.
If delayed, the system also decides the distance-based geofence for releasing the order to the kitchen.
Iterative Model Improvement Gather real-time feedback on discrepancies between predicted times and actual times. Retrain frequently. Tune the model’s loss function to emphasize business priorities such as reducing Dasher wait times more than a small increase in food wait time.
Monitoring and Maintenance Continue monitoring key metrics. Set alerts to catch adverse shifts in model predictions or user behavior. Maintain operational tooling for merchant onboarding, debugging, and quick feature toggles when new restaurant data emerges.
Sample Code Snippet (LightGBM Training)
Below is an illustrative Python snippet that trains a LightGBM model for the prep time prediction:
import lightgbm as lgb
import pandas as pd
import numpy as np
# Example dataset
data = pd.read_csv("restaurant_orders.csv")
features = ["order_size", "time_of_day", "historical_prep_time", "restaurant_capacity"]
X = data[features]
y = data["actual_prep_time"]
# Split into train/test
train_ratio = 0.8
train_index = int(len(X) * train_ratio)
X_train, X_test = X[:train_index], X[train_index:]
y_train, y_test = y[:train_index], y[train_index:]
# LightGBM Dataset
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test)
# Hyperparameters
params = {
"objective": "regression",
"metric": "rmse",
"learning_rate": 0.1,
"num_leaves": 31,
"boosting_type": "gbdt"
}
# Train
model = lgb.train(
params,
train_data,
num_boost_round=1000,
valid_sets=[train_data, test_data],
early_stopping_rounds=50
)
# Prediction
predictions = model.predict(X_test)
Explain in a simple paragraph format: this code loads data with features relevant to prep time, trains a LightGBM model, and then makes predictions on unseen examples to estimate how long it will take a particular restaurant to prepare an order.
Follow-Up Question 1
How would you handle potential biases in prep time estimates that come from restaurants of different sizes or different cuisines?
Answer Explanation Include restaurant or cuisine category as a categorical feature. Adjust or train separate models for different restaurant clusters. Ensure sufficient data coverage for each cluster. Implement continuous monitoring of mean errors per cuisine or restaurant group and reweight the training data if certain segments deviate from the general population.
Follow-Up Question 2
How do you decide the loss function for the LightGBM model, given your core business goal is to reduce Dasher wait times while avoiding a big increase in food wait times?
Answer Explanation Use a custom loss function that penalizes large underestimates of food prep time more than small overestimates. This prevents systematic underestimation that causes excessive Dasher wait. Perform experiments to see how different bias settings affect the final metrics. Calibrate the final choice by measuring the real-world trade-off between Dasher wait time and food wait time.
Follow-Up Question 3
What is the strategy if a new merchant joins the platform and there is limited historical data for their prep time?
Answer Explanation Use a cold-start approach. Share a global model trained on the general population. As data accumulates, refine estimates or start a domain adaptation process if that merchant exhibits unique patterns. Possibly apply conservative estimates until actual performance is observed to avoid large Dasher wait times.
Follow-Up Question 4
How do you scale this feature across thousands of merchants with minimal manual intervention?
Answer Explanation Build automated pipelines that collect and process merchant data daily. Deploy self-serve tools for merchants to onboard themselves into the delayed release flow. Use real-time dashboards for anomaly detection so that any unusually high wait times or food quality concerns can be quickly diagnosed. Maintain an automated model retraining pipeline with rolling updates in production.
Follow-Up Question 5
If the model starts introducing longer delivery times overall, how would you identify and fix the underlying issue?
Answer Explanation Track daily and weekly changes in main metrics like total delivery time. Drill down to restaurant-level errors. Compare predicted vs. actual prep times. Investigate potential feature shifts (e.g., changes in average order size or new restaurant categories). Retrain the model or adjust your decision thresholds. Possibly revert to heuristics or an older stable model version until the new issue is resolved.
Follow-Up Question 6
What would you do to ensure that your final solution is robust to outliers in time estimates or abnormal events (peak seasonal demand, weather disruptions, etc.)?
Answer Explanation Use robust features such as aggregated historical data that includes weather or seasonal signals. Introduce fallback mechanisms that switch to a safer heuristic if predicted wait times deviate too far from normal ranges. Perform stress tests and scenario-based simulations. Maintain frequent retraining schedules with fresh data that includes those outliers to let the model learn from them.
Follow-Up Question 7
How do you confirm that this solution is profitable or has a solid return on investment?
Answer Explanation Quantify improvements in Dasher efficiency: average time saved per delivery, total additional deliveries a Dasher can complete in a day, and cost savings from fewer canceled orders. Track changes in merchant satisfaction and reorder rates. Convert these metrics to monetary values (like time saved per Dasher shift multiplied by labor or operational costs) to measure return on investment.
Follow-Up Question 8
What operational or engineering bottlenecks might you face when rolling out an ML-based approach in real-time decision-making?
Answer Explanation Real-time inference latency constraints can limit heavy computational models. Systems need to handle large volumes of incoming orders. Build a highly available prediction service with caching strategies and horizontally scalable infrastructure. Keep strict service level agreements for model inference requests. Implement thorough observability for each step of the pipeline to handle outages or delays quickly.