
ML Case-study Interview Question: Real-Time Multi-Action Predictions using Multi-Task DNNs and Utility Blending


Browse all the ML Case-Studies here.
Case-Study question
You oversee a critical recommendation feed where user engagement volume is highest. The feed shows content recommendations whenever a user zooms in on a specific item. You want a multi-task modeling approach to predict different types of user actions (like saves, detail views, and clicks). You also want to serve these model predictions into a real-time blending algorithm that balances multiple objectives (organics vs. conversions). Describe how to design, train, and deploy such a system. Focus on data pipeline, multi-task DNN, teacher-student regularization, user behavior signals, and utility-based blending.
Proposed Solution
Multi-task DNN Architecture
Use a deep neural network that predicts multiple actions concurrently. Include separate heads for each action. Apply a mixture-of-experts module to share representation among tasks while preserving the unique signals of each action. Feed user features, item features, and context features into the network. Use a transformer encoder to capture the user’s most recent actions.
In training, define a loss that sums binary cross-entropy for each task. Consider balanced sampling or weighting to manage label imbalance.
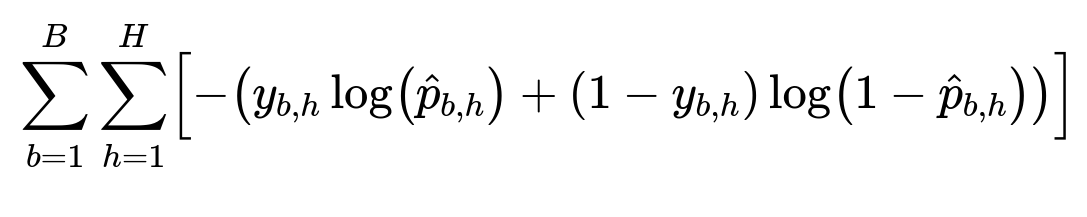
Here, B is batch size, H is the number of tasks, y_{b,h} is the ground truth for task h on example b, and hat{p}_{b,h} is the predicted probability for task h on example b.
Teacher-Student Score Regularization
Distill knowledge from an existing production model to stabilize predictions. During each training iteration, use teacher model outputs to guide the student model.
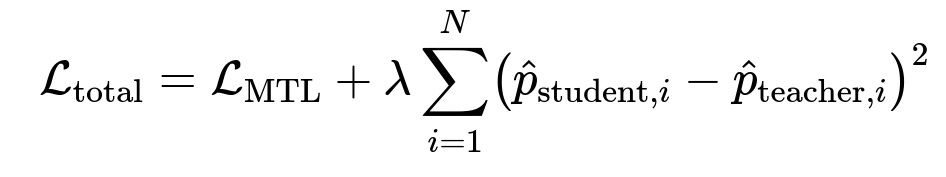
Here, L_{MTL} is the multi-task loss, hat{p}{student, i} is the student’s predicted score for example i, hat{p}{teacher, i} is the teacher’s output for example i, lambda is a hyperparameter controlling regularization strength, and N is the number of training samples.
Real-time User Signals
Capture recent user activity. Encode the last hundred interactions with a transformer-based module. Concatenate or mix these embeddings with static attributes (user demographics, item embeddings). This helps identify short-term preferences.
Utility-based Blending
Use an additional model to infer personalized blending weights. Randomize the blending parameters for a small percentage of users during data collection. Learn a mapping from user context and item context to reward. At inference, generate the predicted weights that maximize expected reward. Insert them into the final scoring function.
This approach avoids frequent hand-tuning. It simplifies balancing different objectives (organics vs. conversions).
Implementation Outline
Collect training data with multi-task labels. Split data into training and validation. Preprocess user sequences with a transformer encoder. Feed numeric and categorical features into embedding layers. Concatenate features and pass them into mixture-of-experts. Output multiple task heads with separate final layers. Train with combined losses and teacher-student regularization. Use an offline experiment to refine hyperparameters. Deploy the trained model behind a high-throughput serving system. Integrate the real-time blending model for final ranking.
Example Python-Style Pseudocode
import torch
import torch.nn as nn
import torch.optim as optim
class MultiTaskModel(nn.Module):
def __init__(self, input_dim, num_experts, expert_hidden_size, num_tasks):
super().__init__()
self.experts = nn.ModuleList([nn.Sequential(
nn.Linear(input_dim, expert_hidden_size),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(expert_hidden_size, expert_hidden_size),
nn.ReLU()
) for _ in range(num_experts)])
self.gates = nn.ModuleList([nn.Linear(input_dim, num_experts) for _ in range(num_tasks)])
self.task_towers = nn.ModuleList([nn.Linear(input_dim + expert_hidden_size, 1) for _ in range(num_tasks)])
def forward(self, x):
expert_outputs = [expert(x) for expert in self.experts]
final_outputs = []
for i in range(len(self.gates)):
gate_scores = torch.softmax(self.gates[i](x), dim=-1)
mixture = sum(gate_scores[j] * expert_outputs[j] for j in range(len(self.experts)))
# skip connection
combined = torch.cat([x, mixture], dim=-1)
final_outputs.append(torch.sigmoid(self.task_towers[i](combined)))
return final_outputs
model = MultiTaskModel(input_dim=512, num_experts=8, expert_hidden_size=256, num_tasks=4)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
In actual production, embed real-time user sequences, apply a teacher model output, and add a teacher-student loss term during backprop.
Follow-up Question 1
How do you tune hyperparameters for the multi-task model?
Use offline experiments. Hold out a validation set with representative data. Vary the number of experts, expert width, dropout rate, and batch size. Track key metrics like AUC or ranking quality for each task. Select the configuration that yields consistent gains for all tasks. Check inference latency constraints.
Follow-up Question 2
How do you decide on teacher-student regularization strength?
Run a grid search over lambda. Compare the stability of the predictions against the teacher’s distribution. Use an A/B test to see if different lambda settings harm new patterns. Pick the largest lambda that preserves model flexibility while reducing excessive rank permutations.
Follow-up Question 3
What if user preferences drift too fast for your blending layer?
Incorporate more real-time context signals. Retrain or periodically update the blending model using recent data. Introduce incremental or streaming training pipelines that update learned parameters. If feasible, shorten the logging-to-serving time gap.
Follow-up Question 4
What is the reasoning behind using a transformer for user sequences?
A transformer can learn dependencies among sequential actions. This captures user intent shifts and interactions between older and newer actions. Compared to simpler RNNs, transformers parallelize computation and model contextual relationships better. This is helpful for generating richer user embeddings.
Follow-up Question 5
Explain trade-offs of randomizing blending weights for data collection.
Randomization helps you observe user response to many weight configurations. This yields good coverage to train a supervised model. But it can degrade short-term relevance for those randomized users. A small randomization slice balances exploration and overall user experience.
Follow-up Question 6
How would you handle new tasks in multi-task learning?
Train with shared experts plus separate heads for the new tasks. Check if existing experts can handle features or if you need specialized experts. Initialize the new heads carefully (like small random initial weights). Possibly retrain from prior checkpoints or partially freeze old tasks.
Follow-up Question 7
How can you ensure your system scales for high traffic?
Use GPU or specialized hardware for serving large models. Optimize embedding lookups and transformer operations. Reduce parameter sizes if inference cost is too high. Employ batching to process multiple requests in a single forward pass. Use asynchronous data fetching for real-time user signals.