
ML Case-study Interview Question: LightGBM for E-commerce Truck Slot Prediction: Optimizing Fulfillment Center Dock Usage


Browse all the ML Case-Studies here.
Case-Study question
An e-commerce platform seeks to optimize how many delivery trucks vendors should send to fulfillment centers. Each center has a fixed number of docks, and each dock can process only one truck (slot) for a specific time. Underprediction (too few slots) causes inbound delays, while overprediction (too many slots) wastes resources. Design a system to predict the needed slots using historical logistics data. Propose how you would build, train, and deploy a machine learning model. Address feature selection, algorithm choice, hyperparameter optimization, trade-offs between under/overprediction, and how to integrate the model into the existing reservation system. Explain your approach and reasoning in detail.
Detailed Solution
Understanding the Problem
Vendors send goods to fulfillment centers, which have limited docks. One truck uses one dock (slot) for a time. Predicting fewer slots than needed leads to queues and delays. Predicting too many wastes dock time. A correct forecast reduces over/underprediction. The system must automatically provide a recommended slot count when a vendor requests a reservation.
Data Gathering and Feature Engineering
Historical logistics data is key. Each inbound request contains vendor ID, product type, requested shipment date, historical inbound volume, and other signals. Combining domain expertise with exploratory data analysis can reveal which features influence truck usage. For example, product category, vendor location, shipping frequency, and seasonality can affect the slot count.
Model Selection
A tree-based boosting model (LightGBM) can handle large datasets and categorical features. Leaf-wise tree growth accelerates training. LightGBM does not require one-hot encoding for categorical data. This leads to speed and better performance.
Core Model Objective
LightGBM fits a gradient-boosted ensemble of decision trees. A robust way to fine-tune hyperparameters is Bayesian optimization. We define a function f(x) representing model performance for hyperparameter x. We then seek x* that maximizes f(x).
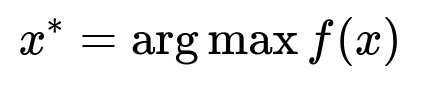
x represents hyperparameters like learning rate, number of leaves, and regularization parameters. f(x) is typically the model’s validation performance metric. Bayesian optimization iteratively refines its search, converging to the best x* within fewer trials than grid or random searches.
Deployment Workflow
A service endpoint hosts the trained model. When the vendor reserves a slot, the reservation system sends relevant features to the model endpoint. The model returns an integer slot prediction. The reservation system displays this number for the vendor. The code can run on a managed platform like AWS SageMaker or an equivalent. For example:
import boto3
# Create a SageMaker runtime client
sagemaker_runtime = boto3.client('sagemaker-runtime')
# Invoke the model endpoint
response = sagemaker_runtime.invoke_endpoint(
EndpointName='YourModelEndpointName',
Body='{"features": [feature_values]}',
ContentType='application/json'
)
# Parse prediction
result = response['Body'].read().decode('utf-8')
predicted_slots = int(result)
print("Predicted slot count:", predicted_slots)
Managing Underprediction vs. Overprediction
Overprediction wastes resources. Underprediction delays inbound. The model can be biased toward slightly higher estimates to reduce underprediction, or vice versa. Balancing these outcomes is crucial. Adjusting the model’s loss function or post-processing the prediction (e.g., ceiling vs. floor logic) can manage this trade-off. Domain stakeholders must determine acceptable underprediction or overprediction margins.
Results and Maintenance
A robust pipeline continuously updates the model with fresh data. New vendor behavior or new product categories require periodic retraining. Monitoring real-world performance helps fine-tune thresholds. Sustained improvement is seen in resource usage and fewer last-minute dock adjustments.
Possible Follow-Up Questions
How would you handle cold-start scenarios for new vendors?
New vendors have little historical data. A solution is to create vendor similarity features based on product type or vendor profile. The system can use average or median estimates from similar vendors. Another approach is to build a secondary model that handles cold-start predictions, possibly using cluster-based methods or carefully selected default values.
How would you evaluate the model’s success beyond standard metrics?
Examining real operational metrics like average daily dock utilization, inbound completion time, and vendor satisfaction reveals true performance. A possible approach is measuring how many vendors were forced to reschedule due to underpredicted slots or how many slots sat idle.
How would you handle extreme outliers in truck usage?
Feature engineering should include outlier mitigation. For instance, weighting or capping certain historical truck usages that happen due to rare promotions or special events. A common approach is to detect abnormal peaks or troughs and treat them separately, possibly with segmented models for peak times.
How do you handle concept drift as the business grows?
The model must be retrained regularly. Automating training pipelines on weekly or monthly intervals helps. Monitoring the distribution of input features and errors over time can alert when the model no longer generalizes well. That triggers a retraining event.
Why is LightGBM chosen over other boosted tree algorithms?
Leaf-wise tree growth results in faster training and better splits for many data distributions. LightGBM supports built-in categorical feature handling via a special split method. Other boosting algorithms often require manual one-hot encoding. LightGBM’s performance and speed fit large-scale logistics data well.
How would you ensure interpretability?
Feature importance from LightGBM clarifies which features matter most. Shapley values can be generated for individual predictions. This helps explain to logistics managers why the model predicted a certain number of trucks and which factors played the largest roles.
How do you mitigate potential vendor dissatisfaction if the model underpredicts?
Maintaining a buffer that keeps underprediction within an acceptable range can help. An internal threshold can ensure the system never recommends fewer trucks than a safe minimum for each product category. Vendors can also override the prediction within reason and submit requests for manual review.
How would you incorporate a real-time feedback loop?
Collect final actual truck usage data after each inbound. Compare that to the predicted value. Store the result in a feedback repository. Incorporate this data in the next training cycle or a near-real-time model update system. This keeps predictions aligned with recent trends.
How would you handle multi-day inbound events?
Some vendors split shipments over multiple days. Summarize total inbound volume across the days and distribute it proportionally. Use features capturing multi-day shipments. The model can then allocate slots in a rolling fashion. Building a time-series forecasting component before the truck prediction model is another option.
How would you scale the solution internationally?
Different countries have different carrier capacities, shipping regulations, and peak shopping seasons. The same approach can be extended by training localized models. Data pipelines must handle local logistic nuances, which might require separate hyperparameter tuning or special features for each region.