
ML Case-study Interview Question: Personalized Sizzle Reels: Real-Time Video Stitching Based on Viewer Rankings


Browse all the ML Case-Studies here.
Case-Study question
You are a Senior Data Scientist at a large streaming platform that showcases many titles across various genres. The marketing teams want a more efficient way to assemble short promotional montages known as “Sizzle Reels” that highlight multiple titles in a single video compilation. They previously created these reels manually, which was time-consuming and lacked personalization for different viewers. They now want to automate the creation of these reels and personalize them in real time for each viewer to drive better engagement.
They plan to build a “Dynamic Sizzle” system. They will create one large “Mega Asset” containing many pre-edited video clips for different titles. When a viewer requests a promo reel, the system must determine which clips to include, how long each clip runs, in what sequence they appear, and how to weave an audio track behind them. The arrangement of clips should be based on a ranking function that personalizes the montage for each viewer’s tastes. The system must then construct and play this personalized reel seamlessly, with minimal buffering or loading times.
Describe how you would design the solution from a data science perspective. Propose a workflow for creating and storing the Mega Asset, generating personalized rankings of titles, determining the required time segments, assembling the final reel on-the-fly, and ensuring smooth video streaming. Explain the challenges in data handling and personalization. Provide a technical implementation plan with enough detail to demonstrate your familiarity with real-time video stitching, large-scale data systems, and personalization techniques. Also outline key metrics for success, potential pitfalls, and optimization strategies.
Detailed Solution
Overall Data Flow
Data ingestion pipelines collect viewer activity, content metadata, and editorial clip data for the Mega Asset. Editors compile multiple clips per title in a single large Mega Asset. Each title’s clips appear in a predictable order, which helps identify their time offsets quickly. A personalization algorithm ranks titles per viewer. The system references these rankings, looks up the correct time offsets from the Mega Asset, and stitches a reel in real time according to a predefined cadence.
Mega Asset Creation
Human editors select and refine video clips. An editing plug-in automates timecode labeling. Each segment’s start and stop times are stored in a data store that can be queried quickly. This avoids manual tracking of each frame boundary. The single Mega Asset is ingested and validated against the indexing metadata.
Ranking Logic
Machine Learning models assign a score to each title. Titles are then sorted by descending score. A higher score means stronger affinity for that title. Titles with higher scores appear earlier and might be allocated longer clip durations.
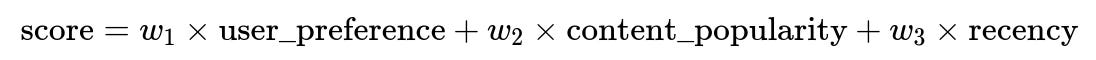
user_preference measures how strongly the viewer generally likes a title based on past interactions. content_popularity measures the overall popularity across viewers. recency captures whether a title is newly released or recently launched. w1, w2, and w3 are weights set using offline experimentation or hyperparameter tuning.
Timecode Lookup
Each clip in the Mega Asset has an identifier. The system uses that identifier to compute the exact time offsets for a requested title and clip length. This lookup is done through a fast index store. Once the order of titles and corresponding clip types are known, the system retrieves a sequence of time ranges to build the final montage.
Sizzle Reels Assembly
The final reel is built by stitching the requested time segments from the Mega Asset. The streaming player requests data segments in the correct order. One short segment finishes, the next starts immediately. Background audio is handled similarly by referencing the needed audio portions in the Mega Asset. This approach relies on robust streaming that supports shorter, discontiguous segments. The system must ensure minimal rebuffering when transitioning between segments.
Example Python Snippet for Timecode Retrieval
def get_timecode(title_id, clip_type, index_store):
# index_store is a dictionary mapping (title_id, clip_type) to (start, end)
start_end = index_store.get((title_id, clip_type), None)
if start_end:
return start_end
else:
return None
# Suppose the system wants to build a reel with the top 3 titles A, B, C
# with clip types 80-frame, 40-frame, 80-frame in that order:
index_store = {
("A","80"): (1000, 1080),
("A","40"): (1080, 1120),
("B","80"): (1120, 1200),
("B","40"): (1200, 1240),
("C","80"): (1240, 1320)
}
sequence = [
("A","80"),
("B","40"),
("C","80")
]
time_segments = []
for item in sequence:
tc = get_timecode(item[0], item[1], index_store)
time_segments.append(tc)
print(time_segments)
# e.g. [(1000,1080), (1200,1240), (1240,1320)]
The time segments are then passed to a service that assembles them back-to-back into a single personalized reel.
Key Success Metrics
Sizzle reel watch completion rate is one metric. If many users stop watching early, the personalization may be off. Another is click-through or engagement with promoted titles after watching. Video streaming quality metrics, such as buffering frequency, measure how well the real-time stitching works.
Potential Pitfalls
Sparse data might cause inaccurate personalization for new or infrequent viewers. Insufficiently precise clip boundaries or indexing errors lead to jarring cuts. Large-scale lookups may cause latency. Enhanced caching or prefetching is often needed if the user’s device or network is slow.
Optimization Strategies
Add caching layers for popular segments to reduce retrieval times. Tune ML model features around the viewer’s temporal preferences. Fine-tune the cadence to vary how frequently the top-ranked titles appear. Deploy A/B tests to find the best arrangement of clips.
What are the challenges in real-time personalization?
Quickly retrieving user profiles and producing a rank-ordered list of titles requires low-latency. Large-scale vector databases or real-time caching help. Scoring models must be fast enough for immediate requests. Retraining the model to keep pace with changing user tastes demands a frequent update pipeline. Engineers must design a service that handles bursts of requests from millions of concurrent devices. Monitoring systems track performance in production to ensure sub-second response times.
How can the system manage frequent changes in editorial content?
Editors often modify clip lengths, add new content, or reorder the Mega Asset timeline. The indexing data store must be updated every time the Mega Asset changes. Versioning the Mega Asset helps. Storing multiple Mega Assets in parallel can be done, where a request references the latest stable version while a new version is being prepared. Automated verification ensures correct offsets after each edit. This pipeline approach prevents partial or inconsistent states.
How would you debug issues where time offsets do not align with the actual video clip?
Pull the raw Mega Asset and compare the stored offsets with actual frame timestamps. A tool might measure the difference between the expected cut point and the actual rendered frame. Logs must capture the offset retrieval steps. For each segment, confirm the correct tuple of (title_id, clip_type) was retrieved. If mismatches occur, re-check the editorial plug-in that tags clips. Automated checks can compare the final stitched result with reference segments to validate alignment before release.
How can we ensure minimal buffering or re-buffering in the final reel?
Break down the reel into segments that the player can prefetch. Implement adaptive bitrate strategies to handle different network conditions. Confirm the streaming pipeline is optimized for many small segments instead of a single large file. Short segments pose overhead in manifest requests, so the system’s manifest and segment request logic must handle them efficiently. Additional caching at the edge reduces round-trip latencies. Continuous performance tests watch for spikes in buffering events during reel transitions.
How might you incorporate user feedback to refine these personalized reels over time?
Collect metrics on watch duration, skip events, and whether a user plays a recommended title afterward. Match segments that led to further engagement with the titles they highlighted. Integrate a feedback loop that updates the ranking model’s parameters. If viewers frequently skip the second clip, investigate the choice of that title or its clip length. If certain segments drive high follow-up engagement, weigh those titles more heavily. Over time, this iterative approach aligns the reel content more closely with user preferences.