
ML Case-study Interview Question: AI-Driven Promo Optimization Using ML Segmentation & Hyperparameter Tuning


Browse all the ML Case-Studies here.
Case-Study question
A large online platform for food delivery and other on-demand services wants to improve how merchants run promotional campaigns. They have an existing system that lets merchants set up blanket discounts for all customers, but they notice inefficient promo spending and low returns on sales uplift. They want to build an AI-driven approach that can suggest optimal promos for different user segments, predict user redemption behaviors, and handle hyper-parameter tuning to meet specific business goals. As a Senior Data Scientist, outline how you would design and implement a system that uses customer segmentation, automated promo design, and machine learning models to assign the right promos to the right users. Describe how you would handle large-scale data processing, model training, and hyper-parameter optimization. Propose your recommended architecture and show how you would evaluate the impact of your solution.
Detailed Solution
Merchants face the challenge of assigning the right promos to the right customers. They also lack a simple interface that offers targeted promo suggestions without requiring deep data science knowledge. The solution must handle large volumes of user data, merchant data, and promo design options. The approach should capture the following ideas:
System Architecture
The system has a user interface (UI) and a backend service. The operations team inputs merchant campaign details in the UI. The backend calls an internal job that processes data, runs predictive models, and returns suggested promos. The data pipeline uses a distributed environment for big data processing. For example, a Spark job ingests user attributes, merchant historical data, and potential promo settings. After predictions, the system assigns the most suitable promos.
User Segmentation
The system categorizes customers as new, churned, or active. New users might benefit from strong acquisition offers. Churned users might need reactivation deals. Active users might be nudged to increase order frequency or basket size. This segmentation process runs on historical orders per merchant or per merchant brand.
Promo Designer
The system automatically designs multiple offer variations (for example, different discount percentages, voucher values, or minimum spending thresholds). It references the merchant’s usage history to pick ranges of discount or voucher amounts that have historically produced the best returns. The output is a list of candidate promos for each segment.
Customer Response Model
This model predicts redemption rates, average order values, and user uptake if the user is offered a specific promo. It captures user attributes such as cuisine preferences, order frequency, brand loyalty, and discount sensitivity. Then it estimates the likelihood of redemption and expected basket size. A logistic regression or gradient-boosted trees approach is common for modeling redemption probability. A separate regression model might predict spend amount given redemption.
Core Formula for Predicted Revenue
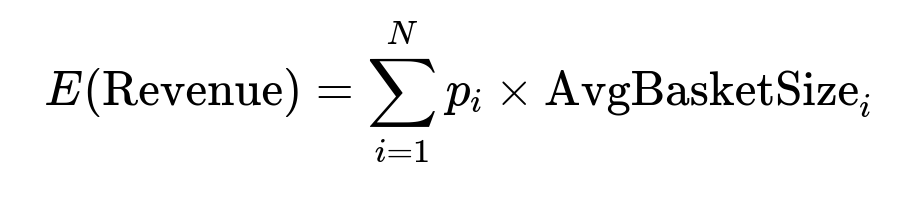
Where p_i is the predicted redemption probability for user i, and AvgBasketSize_i is that user’s forecasted basket size if they redeem. This aggregation happens across N users eligible for the campaign. The system can also compute total promo cost as the sum of redemption probability times the discount. Then it chooses promos that balance predicted revenue uplift against the merchant’s cost constraints.
Campaign Impact Simulator
This simulator uses the predicted redemption probabilities and expected spending amounts to forecast metrics like revenue uplift, sales volume, and promo cost. The simulator compares the outcomes for different promo sets or parameter configurations. It then produces the best combination under constraints (for example, cost per sale not exceeding a threshold, or total promo spending not going beyond a fixed budget).
Hyper-parameter Tuning
There are multiple goals, such as maximizing revenue while keeping cost per sale within a limit. The system tunes parameters that control how it weighs each objective. Hyper-parameters might include discount range, budget ceilings, or priority weights for cost vs revenue. An optimizer (like Bayesian search) searches for configurations that meet these objectives.
Model Training and Iteration
Regular model retraining accommodates changing user behaviors, new merchant offerings, and updated cost goals. The system tracks performance after each campaign to see if actual redemption rates match predictions. It uses these metrics to refine features, re-calibrate the models, or test new architectures (for example, neural networks vs gradient boosting).
Example Python Snippet for Model Training
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
df = pd.read_csv("campaign_data.csv")
X = df[["user_tenure","num_orders","avg_basket_size","discount_sensitivity"]]
y = df["expected_spend"] # continuous target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=5)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
This example shows how you might train a model to predict user spending based on features. A separate classifier or combined modeling approach can predict redemption probabilities.
Measuring Impact
The system measures impact by comparing the actual orders and promo redemptions against predictions. Key success metrics include revenue uplift, cost per sale, and incremental orders. Merchants see if the AI-based approach outperforms static discount strategies. Ongoing metrics tracking drives further refinement and helps adapt to changes in customer and merchant behaviors.
Follow-up question 1: How would you handle cold-start users who do not have historical orders?
For cold-start users, the system uses broad assumptions or population-level averages for redemption behavior. One approach is to assign these users to a “new user” segment. The model can use sparse user features (like sign-up channel or location) and rely on general trends for predicted redemption. As new orders come in, the system updates the user’s profile and places them in a more precise segment in the next campaign cycle.
Follow-up question 2: How would you balance merchant budgets with the risk of overspending on promos?
The system’s simulator factors in a maximum total budget. If the simulator sees that a particular promo design might exceed the budget due to high redemption probabilities, it rejects or re-scales that design. The hyper-parameter tuning includes a cost constraint. If predicted cost per sale rises above a certain threshold, the model explores other parameter settings. The final assignments only include promos that satisfy cost limitations.
Follow-up question 3: How do you ensure the model remains robust against shifting user behavior?
You schedule frequent retraining and continuous monitoring of key metrics like redemption rate, average basket size, and actual cost. If metrics drift significantly from model predictions, you trigger re-training or refresh features. You also maintain a validation or hold-out set from recent data to catch changes in user behavior. If the system sees a consistent discrepancy between predicted and actual outcomes, it logs an alert and triggers further checks or model updates.
Follow-up question 4: How do you handle potential bias or unintended targeting issues?
You add fairness checks and carefully examine whether certain user groups are consistently over-targeted or under-targeted. You can monitor how different segments are being assigned offers, then compare the distribution with policy or fairness guidelines. If the system shows skew, you can add regularization terms that encourage equitable distribution of promo assignments. You can also introduce rules that ensure each segment receives at least some minimal marketing coverage unless a business policy overrides it.
Follow-up question 5: How can you scale the data pipeline for millions of users?
You design the pipeline on a cluster-based framework that processes data in parallel. Spark or similar distributed computing systems read the data from storage (such as a data lake), run transformations, and generate features. This approach ensures training and inference can handle large data volumes. You keep an eye on partition strategies and concurrency settings so that the data is distributed uniformly and the job can complete within the required timeline. If the job volume grows, you scale the cluster horizontally or tune cluster resources.
Follow-up question 6: How would you integrate reinforcement learning or online assignment?
You implement a system that can dynamically update promos based on real-time events. As users show a higher or lower redemption probability, the model adjusts. With reinforcement learning, you collect immediate feedback (did the user redeem?), feed it back into a policy-based model, and refine the policy parameters. This requires stable online infrastructure to process streaming data, an automated model versioning system, and a robust real-time scoring API.
Follow-up question 7: How do you approach multi-objective optimization beyond just revenue and cost?
You introduce a weighted scoring function that includes additional objectives (for example, brand visibility or user retention). You define relative weights for each objective. The system runs a search over these weights to find the best trade-off. If brand visibility is important, you might allocate more of the budget to a certain subset of categories. If cost efficiency is paramount, you lower the weight for brand exposure and raise the weight for cost constraints.
Follow-up question 8: How do you ensure the reliability of the system when it faces a large spike in campaign requests?
You implement load-balancing strategies at the service layer. You store input parameters in a queue or a message broker if calls spike. The distributed computing backend scales horizontally, adding more worker nodes if needed. The system performs asynchronous calls for large campaigns. If the requests are too large for near-real-time responses, you send partial results progressively. Robust monitoring ensures no single bottleneck.
Follow-up question 9: How do you track final campaign performance and calibrate the model?
You measure actual redemptions, average order sizes, and cost after the campaign concludes. You compare them to the predictions from the simulation. If significant discrepancies appear, you analyze which segments or promos underperformed. You adjust hyper-parameters or model weights in the next iteration. Over time, this feedback loop converges the model to more accurate predictions. You also keep an archive of historical campaign performances to see trends or outliers.
Follow-up question 10: How would you deal with data privacy and compliance in such a system?
You remove sensitive user details and avoid storing personally identifiable information in raw format. You assign user IDs that do not directly trace back to real identities. You also include user-level opt-out mechanisms for promotions. If a user revokes data usage, you exclude them from further targeting. You secure the data pipeline with encryption and proper access controls. You log all data access to ensure compliance with legal and regulatory frameworks in each region.