
ML Case-study Interview Question: Extracting Keyphrases & Entities from Dense Text using NER & Knowledge Base Linking


Case-Study question
A major technology enterprise has user-uploaded documents containing dense text and varied topics. The data science team must extract key topics and significant named entities to enable discovery and recommendation. The raw documents frequently exceed thousands of words and include diverse styles, making it hard to identify important content. The team wants a robust approach to extract keyphrases and entities, normalize duplicates or aliases, disambiguate them with a knowledge base, and produce a compressed yet rich representation of each document to power downstream recommendation pipelines. Propose a detailed solution covering all aspects of keyphrase extraction, entity extraction, alias normalization, knowledge base linking, and subsequent usage in recommendation or search. Provide both conceptual approaches and potential implementation details. Suggest methods to handle ambiguous aliases (e.g. overlapping names or references). Outline how to measure success. Justify the trade-offs made in your approach.
Detailed Solution
Keyphrase Extraction
A good approach uses unsupervised methods for scalability and minimal data-labeling needs. Filtering out stopwords and extracting n-grams creates initial candidates. Restricting to one fixed n can cause fragmentation, so an agglomeration step merges shorter n-grams into longer phrases if their occurrence frequency meets a threshold relative to the shorter candidate.
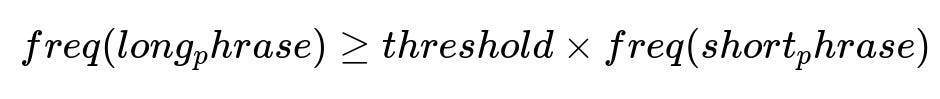
freq(long_phrase) is the total occurrence count of the longer phrase in the document. threshold is a predefined fraction of freq(short_phrase). This condition ensures merging only if the longer phrase is consistently present with the shorter candidate. The result is a set of more cohesive keyphrases. For weighting, rely on how often a phrase appears, since frequent keyphrases typically align with central themes of lengthy documents.
Entity Extraction
Identifying named entities enriches the representation beyond simple topics. Parsing the document with a Named Entity Recognition (NER) model surfaces persons, places, organizations, etc. Counting occurrences is not straightforward because entities may appear through multiple aliases or partial references (e.g. “John Stuart Mill” vs. “Mill”). Normalizing them helps reveal the true frequency.
A practical technique is to adopt a longest-alias-first approach and group shorter aliases if they match certain heuristics. For example, if “John Stuart Mill” and “Stuart Mill” share major tokens, the system infers they refer to the same individual. Replacing these forms with a canonical alias resolves duplication and amplifies the entity’s true importance.
Entity Linking to a Knowledge Base
Referencing a knowledge base, such as a public resource of notable entities, helps disambiguate aliases. Embedding the text and potential entities in a shared vector space makes it easier to match context. If the system finds that “Washington” more likely refers to “George Washington” rather than “Washington State,” it links to that entity’s unique identifier. This step refines the canonical alias assignment and allows using knowledge base metadata in further processes.
When no plausible knowledge base entry is found for an alias, fallback logic assigns that alias to the nearest recognizable entity if the heuristics suggest they are the same. Otherwise, keep it as an unlinked entity with a local canonical alias. This ensures coverage even for obscure or novel entities absent from external sources.
Implementation Example
A Python pipeline could process documents as follows. First, tokenize and label part-of-speech. Then extract potential n-grams using a frequency threshold. Expand partial n-grams to longer keyphrases where the above frequency condition holds. Use a NER model to detect entity boundaries. For each entity mention, check if it matches an existing alias group or create a new group. Look up candidate entities in the knowledge base by textual similarity or pretrained embeddings. Assign the best match if confidence is high. Persist the entity ID or fallback to the normalized alias if not found.
import spacy
nlp = spacy.load("en_core_web_sm")
def extract_entities_and_phrases(text):
doc = nlp(text)
# Extract potential noun-based n-grams or multi-word expressions
# Then group them using the frequency condition
# Next, identify named entities and handle canonical alias resolution
# Then link to a knowledge base if appropriate
# Return final sets of keyphrases and entity groups
return keyphrases, entities
Usage in Recommendation or Search
Keyphrases provide a compact set of topics. Entities capture specific references. Combining both yields a richly annotated representation that powers document similarity and recommendation. Storing each document’s annotated content in a graph-like structure (documents and concept nodes linked by edges) allows flexible exploration. Adding embeddings computed from entity IDs or from the textual contexts improves clustering of related documents. Queries that combine textual searches and semantic expansions find relevant content beyond surface-level matches.
Measuring Success
Evaluate coverage and accuracy by checking whether key extracted phrases and linked entities match annotated ground truth. For large-scale data, sample or run A/B tests to see if recommendations based on these features improve user engagement. Record how frequently extracted terms or entities lead to meaningful document clusters or retrievals.
Follow-up Question 1: How would you optimize performance for large batches of documents?
Parallelizing the keyphrase and entity extraction workflows handles large datasets. Splitting documents across multiple workers that run identical pipelines is common. Caching frequent lookups in memory (like recurring aliases or repeated named entities) reduces repeated knowledge base queries. Summarizing partial results and merging at the end avoids reprocessing the same text segments. Profiling each pipeline stage helps detect bottlenecks, such as repeated network calls to the knowledge base.
Follow-up Question 2: How would you handle edge cases where partial aliases match multiple entities?
Context is key. Checking local context embedding around ambiguous mentions clarifies which entity is intended. Building a small classification model that uses local tokens (before and after the mention) plus the candidate entity’s embedding can refine the match. If scores are tied, fallback to a safe default or keep the mention unresolved. Continuous improvement comes from collecting feedback signals whenever the system incorrectly merges or disambiguates an entity.
Follow-up Question 3: How do you integrate domain-specific language (medical, legal, etc.)?
Loading domain-specific NER models or augmenting training data with specialized text sets can improve detection of advanced domain entities. For keyphrases, adding custom dictionaries helps filter out domain-stopwords (e.g. standard disclaimers) that are not important. Updating the knowledge base to include specialized sources (like MeSH for medical terms) further improves accuracy. Testing on domain-specific corpora ensures robust coverage of unique terminology.
Follow-up Question 4: Why is unsupervised keyphrase extraction chosen over supervised approaches?
Large coverage of topics and user-driven content complicate label generation for supervised models. Gathering annotated data at scale is expensive and might not generalize to new or niche categories. Unsupervised extraction with frequency-based importance handles unseen data well and avoids overfitting. When labeled data is limited, or topics are unpredictable, unsupervised methods are typically more flexible and faster to deploy.
Follow-up Question 5: How do you validate entity linking?
Randomly sample linked aliases and manually verify correctness. Inspect confusion metrics for entities with multiple plausible references. Compare system outputs against known references in well-studied corpora or established benchmarks. Track link-precision and link-recall over time. If the organization has partial ground truth or user-labeled data, measure alignment to these references. Incrementally refine heuristics or embedding techniques when systematic errors recur.
Follow-up Question 6: How would you extend this approach to short user-generated text?
Short texts lack repeated patterns, so frequency-based keyphrase extraction is less reliable. Rely more on knowledge base lookups, direct dictionary matches, or contextual embeddings. Use a language model that accounts for word co-occurrence and semantic similarity. Increase confidence thresholds for entity linking because fewer contextual clues exist. In some cases, expand to a user’s broader content history to gather enough references for disambiguation.
Follow-up Question 7: Could you detect new entities not in the knowledge base?
Yes. Mark them as unknown entities with a local alias, and store them in a staging database for possible validation or insertion into the knowledge base later. If the system repeatedly sees a new entity or if user feedback indicates significance, escalate it for a curated review. Over time, a pipeline can learn to trust new entries if stable references accumulate. This ensures coverage for novel or emergent entities.
Follow-up Question 8: How do you tune the threshold in n-gram agglomeration?
Try different threshold values and measure the coherence of agglomerated phrases. If the threshold is too high, the model under-merges and misses longer phrases. If it is too low, the model merges phrases that are not consistent. Cross-validate by measuring how well extracted phrases match a known set of key topics. Use statistical metrics like token precision or overlap with reference keyphrases. If possible, iterate with feedback from domain experts to refine the threshold.
Follow-up Question 9: How do you handle memory limits with extremely large documents?
Stream the text in chunks. Update partial frequency dictionaries or partial NER recognition results incrementally. Merge results at the chunk boundary. If the pipeline loads the entire document at once, consider chunk-level processing that accumulates counts for keyphrases and entities. Cache intermediate states to disk if memory is constrained. Track duplication or overlap across chunks when normalizing aliases.
Follow-up Question 10: How do you integrate these features into a recommendation engine?
Append keyphrases and entity IDs to a vector-based representation. Concatenate or average embeddings for each phrase or entity. Use a graph-based similarity measure to find related items. If items share many key entities, rank them higher. For deep learning models, embed text, keyphrases, and linked entity vectors as input features. During retrieval, measure dot products between embeddings or feed them into a specialized ranking model. A/B test to confirm improved click-through or engagement.
Follow-up Question 11: How do you maintain and evolve this system over time?
Retrain or re-initialize parts of the pipeline if model performance declines. Update the knowledge base regularly for new entities or aliases. Monitor logs for repeated error patterns or unusual spikes in unknown mentions. Add domain-specific expansions if user content shifts to new themes. Continually measure success metrics, gather user signals, and refine thresholds or embeddings. Store historical extraction results so that you can quickly revert or reprocess if an updated pipeline outperforms previous versions.