
ML Case-study Interview Question: Hierarchical Color Clustering for Accurate E-commerce Product Image Tagging


Browse all the ML Case-Studies here.
Case-Study question
A large online retailer sells millions of products where color is a key attribute for customer search and filtering. The retailer’s existing system fails to accurately tag product colors, leading to poor search results (for example, showing navy furniture under black). Design a robust approach to:
Build a hierarchy of related colors that captures near-synonyms and different shades.
Assign descriptive color names to each layer of this hierarchy.
Tag products with appropriate color labels from high-level (e.g. “blue”) to more specific (e.g. “navy”).
Evaluate and improve the system’s accuracy, especially given limited ground truth data. Explain the full pipeline design for color extraction, hierarchical color taxonomy construction, color naming, and method of deployment at scale.
Detailed In-Depth Solution
Color Hierarchy Construction
Cluster Red-Green-Blue values into multiple levels of granularity. A human eye perceives color differences in a specific way, so define a distance metric that aligns with human perception. Use:
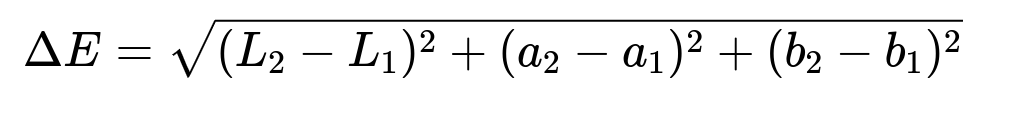
Delta E measures perceived visual distance. L, a, and b are values in a color space (often CIELAB) that approximates how the eye distinguishes color. If delta E is under a small threshold, colors appear almost identical. If it is above a larger threshold, they look different.
Start with a bottom-up approach:
Run clustering (for example, K-Means) on extracted product Red-Green-Blue values to form the most granular color clusters. Each cluster has a centroid representing a distinct hue.
Assign initial names by comparing each centroid with a known set of labeled Red-Green-Blue values from public data sources. If the distance between a centroid and a known color is below a threshold, inherit that color name.
Merge visually similar clusters using a technique such as Birch clustering at an intermediate level of granularity.
Group the narrower clusters into broader color families using a graph-based or clique-finding algorithm. Allow overlap, so certain clusters (like teal) can be associated with both blue and green families.
Use a small set of basic colors (red, green, blue, yellow, purple, pink, black, white, orange, brown, gray, plus any relevant additions) at the top level. Tie these basic colors to the broader clusters by searching for the nearest neighbors in color space.
Color Tagging for Products
Crop or isolate the region of interest in product images. Cluster pixels (for instance, mini-batch K-Means) to find up to five dominant colors. For each extracted color, match it to the closest centroid in the hierarchy’s finest level using a high-performance similarity search library (like Faiss). Roll up or roll down through the hierarchy to obtain names at multiple levels.
If a product has multiple colors, store up to five color tags with associated volumes or proportions. Provide the final color names both at the granular and more general levels, ensuring users can filter by “blue,” or get more specific as “teal,” “navy,” etc.
Handling Accuracy and Human Review
Ground-truth tags can be incomplete or noisy. Treat supplier tags as a weak source of truth only for cases where the product is a single color at a basic level. For disagreement between the system’s predictions and supplier tags, rely on human review. Keep track of the acceptance rate, where a prediction is deemed correct if it is visually judged acceptable even if it differs from the supplier’s label.
Use additional sources of information if image shadows or lighting cause errors. Text descriptions or digital swatches can fill gaps. If the model consistently misclassifies whites as grays, add specialized logic or more robust features (color histogram, hue-saturation-value transforms) to handle shadows.
Implementation Example (Python Snippet)
import numpy as np
from sklearn.cluster import MiniBatchKMeans
import faiss
# Suppose 'pixels' is an array of shape (N, 3) for the bounding box
k = 5
clusterer = MiniBatchKMeans(n_clusters=k, random_state=42)
clusterer.fit(pixels)
dominant_colors = clusterer.cluster_centers_
# Suppose 'level4_centroids' is a NumPy array of shape (M, 3) for your color taxonomy
index = faiss.IndexFlatL2(3)
index.add(level4_centroids.astype(np.float32))
D, I = index.search(dominant_colors.astype(np.float32), 1)
# 'I' holds indices of the nearest color centroid in the taxonomy
# Map these to color names and roll up or down the hierarchy as needed
Operational Concerns
Store the hierarchy in a stable format (database or specialized search index) that can scale. Retrain or refresh the clusters when new products introduce new color varieties. Maintain a pipeline where images flow in, bounding boxes are parsed, colors are extracted, and nearest-centroid searches are done in near real-time. Track acceptance metrics for continuous quality checks.
Possible Follow-Up Question 1
How would you handle color synonyms such as “turquoise,” “teal,” and “aquamarine,” which can belong to more than one parent color?
Answer: Map each cluster centroid to multiple parents if the distances are below a certain threshold. Use a graph structure that captures overlaps. The final labeling step can display one or more color families. For instance, if the color centroid is near both blue and green, link it to each parent. During search or filtering, the product will appear for queries of both color families.
Possible Follow-Up Question 2
How would you incorporate text data (like supplier descriptions) to refine color predictions?
Answer: Extract color words from textual descriptions (for example, “navy upholstery”) and match them to the color taxonomy. If the text indicates a strong color label that conflicts with the image-based label, recheck the extracted Red-Green-Blue clusters for any shadows, overexposure, or partial coverage. Combine text-based signals as features in a model that re-ranks final color tags.
Possible Follow-Up Question 3
How would you handle continuous intake of new product images that might include unfamiliar colors?
Answer: Implement a monitoring system that detects when a new product’s centroid is above a high threshold of distance from all existing centroids. Queue these colors for manual labeling and decide whether to introduce a new cluster or merge them with an existing cluster. Update the hierarchy periodically so it remains representative of all products.
Possible Follow-Up Question 4
How would you ensure the pipeline remains efficient as the catalog grows to billions of images?
Answer: Use approximate similarity search libraries such as Faiss or Annoy for scale. Partition the images and parallelize the color extraction and clustering steps. Store centroids in a GPU-accelerated index so lookups can be done rapidly. Periodically retrain or incrementally update clusters to manage memory usage. Cache repeated color lookups for commonly encountered hues.