
ML Case-study Interview Question: Adaptive Conversational Music Recommendations Powered by Offline Reinforcement Learning.


Case-Study question
You are the Senior Data Scientist at a popular music streaming company. The team wants to build a conversational music recommender on their voice-enabled assistant. The recommender needs to discover a listener’s current mood, ask clarifying questions, and then suggest tracks or playlists. Traditional rule-based approaches led to rigid question-and-answer flows and mixed user satisfaction. The company now plans to use a machine learning approach that leverages offline reinforcement learning, user history data, and random exploration during live interactions to refine the dialogue strategy and converge on more successful recommendations.
Construct a solution strategy for designing, implementing, and evaluating this conversational music recommender. Provide details on data collection methods, how the model learns effective prompts and suggestions, and how you will measure success. Include how you would handle conversation flow, reduce conversation length when appropriate, and keep users engaged if they want a longer experience. Describe how you would incorporate user sentiment and historical preferences into your solution. Outline the potential challenges and how you will address them.
Explain your reasoning, show examples or code snippets if necessary, and propose ways you would iterate on the model to improve performance. Finally, discuss how you would ensure this system remains robust even when you do not have direct online exploration of every conversational path, and how you would test new dialogue policies offline without subjecting large user groups to unpredictable experiences.
In-depth solution
A robust conversational recommender system should collect contextual clues through a dialogue and then map those clues to relevant suggestions. Traditional rule-based systems can offer structured flow but miss out on adapting to a user's unique preferences in real time. Machine learning, especially an approach based on reinforcement learning, addresses that gap.
System overview
Use a pipeline that starts with voice input. Convert speech to text, parse semantic slots like user’s indicated mood or genre, then invoke your dialogue management module. That module decides whether to ask follow-up questions, provide a suggested snippet, or finalize a recommendation. Engage an offline reinforcement learning mechanism that continuously improves the policy for asking relevant questions and proposing suggestions.
Data collection
Gather anonymized conversations from a small fraction of real user sessions, where your system occasionally introduces random question prompts or sample suggestions. This provides the “exploration” necessary to estimate how well these alternate prompts and suggestions perform. Store each conversation turn, the associated user feedback (accept, reject, or neutral response), and relevant user context such as music history.
Core reinforcement learning logic
Use a value-based or policy-based offline RL algorithm. The Q-learning formulation is common, estimating the expected return of each state-action pair. A typical Q-learning update is:
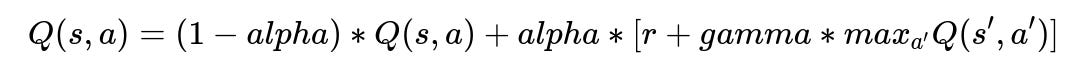
Where:
s is the current dialogue state, representing the user's known preferences, past answers, and mood.
a is an action, such as presenting a question prompt or playing a snippet.
r is the immediate reward (did the user accept the music selection or abandon the session?).
alpha is the learning rate that balances new observations with prior knowledge.
gamma is the discount factor that weighs future rewards relative to immediate ones.
s' is the next dialogue state after taking action a.
a' indicates all possible actions in the new state s'.
Apply offline RL on stored conversation logs. You evaluate possible “what-if” scenarios (counterfactuals) where the system might have asked a different question. The random exploration data helps measure potential outcomes of these alternative prompts and states.
Conversation flow management
Keep an internal measure of how many turns have occurred and how often the user shows positive or negative responses. If the user shows strong positive signals quickly, finalize a suggestion. If the user is uncertain, propose a short new question or snippet. If the user seems to enjoy exploring, keep a flexible structure to allow more turns. Sentiment analysis can refine how quickly you transition to final recommendations.
Personalization using user history
Include user music genres, favorite artists, or past skip/like behavior in the system state. If a user often accepts tracks tagged as “mellow indie,” the algorithm learns to offer that genre earlier in the conversation.
Handling repeated sessions
Implement a system that learns over time to shorten or lengthen conversations based on the user’s acceptance patterns. If a returning user consistently picks “energetic EDM” at certain times of day, the system can front-load that option.
Potential challenges
Data sparsity arises when new question prompts or new genres do not have sufficient coverage in historical logs. Use randomization to gather enough exploration. Another challenge is ensuring the system does not become stuck offering only the same, highly popular tracks. Encourage exploration by awarding small positive rewards for trying lesser-known but relevant tracks that the user might like.
Testing offline vs. online
Use counterfactual evaluation. Build a simulator of conversation turns from existing data. Test new dialogue policies in that simulator before exposing them to real users. Deploy the most promising version to a small subset of user sessions, confirm improved success metrics, then scale up.
Example Python snippet
Below is a minimalistic example showing how you might structure an offline Q-learning approach in Python. This snippet assumes you have a dataset of (state, action, reward, next_state) transitions.
import random
# Example state and action spaces (placeholder)
state_space = ["stateA", "stateB", "stateC"]
action_space = ["prompt_mood", "prompt_genre", "play_snippet"]
# Initialize Q-table
Q = {}
for s in state_space:
Q[s] = {}
for a in action_space:
Q[s][a] = 0.0
alpha = 0.1
gamma = 0.9
def q_learning_offline(experience_data):
for (s, a, r, s_next) in experience_data:
current_q = Q[s][a]
max_next_q = max(Q[s_next].values()) if s_next in Q else 0.0
new_q = (1 - alpha) * current_q + alpha * (r + gamma * max_next_q)
Q[s][a] = new_q
# Example usage
offline_dataset = [
("stateA", "prompt_mood", 1.0, "stateB"),
("stateB", "play_snippet", 0.0, "stateC"),
# ...
]
q_learning_offline(offline_dataset)
Explain to interviewers how you would scale this logic to large state and action spaces, possibly using function approximators like neural networks.
Measuring success
Track conversation success rate, average conversation length, user satisfaction metrics, and re-engagement with the system. Keep a close watch on how often the system successfully identifies user intent and leads them to an accepted recommendation. Monitor fallback rates where the system fails to propose any selection users want.
Iteration
Improve question prompts, vary the system’s voice responses, refine the RL reward function to incorporate user sentiment signals, and keep logs to measure any shift in user preferences. Aim for shorter conversations when the user’s intent is clear, yet remain flexible if the user wants to continue exploring.
Build incremental model improvements:
Gather new random exploration data with safe bounding so that random prompts do not degrade the user experience drastically.
Run offline policy evaluation.
Roll out a small-scale A/B test with a fraction of users.
Compare success metrics.
If improved, deploy widely.
Consistency and reliability are paramount. You want to ensure each policy update makes user experience better or, at worst, does no harm.
What-if follow-up questions
How would you handle ambiguous user queries?
Ambiguous queries might be vague phrases like “I want something fun.” Start with broad follow-up questions or examples of different interpretations. Let the system ask whether the user means “upbeat pop,” “light alternative,” or “dance hits.” The RL policy can keep the conversation short if the user responds with clarity (like naming a specific artist) or expand if they remain unsure. Offline learning helps identify which clarifying questions are most likely to lead to a positive outcome for that ambiguity class.
How do you tune hyperparameters for offline RL?
Offline RL hyperparameters include alpha, gamma, and any neural net parameters if function approximation is used. First, do grid searches on historical data or offline simulators to find stable parameter ranges. Then proceed with smaller real-world tests. Evaluate conversation metrics like the acceptance rate and user retention. If metrics stall or degrade, adjust alpha to incorporate new user feedback more or less aggressively, or alter gamma to weigh near-term successes differently from long-term user loyalty.
How do you incorporate user sentiment?
Record user utterances with an appropriate sentiment score. If they respond positively to a snippet, treat that as a partial reward boost. If they respond neutrally or negatively, treat that as a reduced or zero reward. For example, a strong positive phrase can add a small bonus to your standard reward. This shapes the Q-values or policy parameters to favor conversation paths that yield enthusiastic responses. With each iteration, the system emphasizes prompts that historically led to better sentiment.
How do you mitigate the risk of repetitive suggestions?
When your system learns that a certain genre or artist yields frequent successes, it might converge on offering that too often. Mitigate this by assigning diminishing returns if the same suggestion is repeated to the same user. Another approach is to add a small exploration bonus for suggesting new but somewhat similar tracks. This keeps recommendations fresh while preserving personalized accuracy.
How would you validate domain transfer?
Suppose you expand the system to new languages or new music subgenres. Prepare a parallel offline dataset with user dialogues in that domain. Test your existing policy in a simulator environment that approximates the new domain. Identify which conversation states or actions differ. Retrain or fine-tune the policy with partial random exploration that collects data from real interactions in the new domain. Evaluate carefully to ensure the system still maintains a high success rate.
How to ensure data privacy and compliance?
Store user interaction data in anonymized form. Maintain clear data retention policies and securely handle any personally identifiable information. Provide users with transparent options to opt out of data collection. In your offline RL approach, avoid storing raw voice snippets after transcription unless necessary. All logs should be stripped of user IDs or sensitive content, focusing only on relevant context like general mood or acceptance signals. This reduces risk and aligns with privacy regulations.
Always keep user trust at the forefront. The final solution must be user-friendly, adapt to diverse tastes, and safeguard personal data.