
ML Case-study Interview Question: Multi-Branch Deep Neural Networks for Scalable, Accurate Payment Fraud Detection


Browse all the ML Case-Studies here.
Case-Study question
A growing online payment platform needs to stop fraudulent transactions accurately, quickly, and at large scale. Fraud attempts happen in about 1 out of every 1,000 transactions and evolve constantly. The platform has billions of transactions each year, and relies on machine learning to detect risky payments. Over time, the platform has evolved from logistic regression to an ensemble approach with XGBoost plus a deep neural network (DNN). They recently abandoned XGBoost to move to a DNN-only architecture. Their primary challenge was balancing the “memorization” power of XGBoost with the “generalization” power of deep nets. They also needed to incorporate new features and handle more training data without slowing training. They want to maintain minimal false positives because each blocked legitimate payment hurts both the business and users. They also want transparency, offering clear explanations when a legitimate transaction gets flagged or when fraud slips through.
How would you design the machine learning system from the ground up to reduce false positives while catching as much fraud as possible? Include details of your model architecture, training data strategy, feature engineering, and explainability methods.
Detailed solution
The system needs to recognize rare fraudulent transactions (about 0.1% to 0.2% of the data) and differentiate them from legitimate transactions. Frequent model retraining is key because fraud patterns shift.
Model architecture
The previous pipeline combined a gradient-boosted tree (XGBoost) with a DNN. Maintaining two separate modeling approaches introduced complexity and limited scaling. Dropping the XGBoost component but preserving memorization was possible by increasing the DNN’s width and depth, then enhancing it further with a multi-branch design inspired by ResNeXt. This approach splits the network into parallel branches that individually process feature subsets, then aggregates them to produce richer representations. It keeps training time fast and improves generalization.
Increasing the size of the network boosts capacity for learning complex interactions, but a very deep network risks overfitting. Careful regularization, dropout layers, and hyperparameter tuning will ensure it generalizes across diverse merchant and customer profiles.
Core logistic regression for classification has a probability output that can be used inside more complex neural nets:
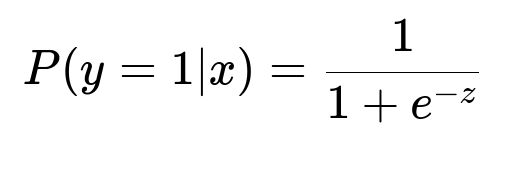
Here, y=1 means a transaction is flagged as fraudulent, x is the feature vector (transaction data), and z = w*x + b is the linear combination of weights and features that the network’s final layers produce. This forms the final classification probability in many DNN-based systems.
Data scaling
Training time must remain manageable even if the data set grows by 10x or 100x. A purely DNN-based system, when parallelized, can handle large training sets faster than XGBoost. Clustering computation across multiple machines or GPUs can reduce training time further. Efficient input pipelines, streaming mini-batches, and early stopping also help maintain performance while continuously retraining the model.
Feature engineering
Analyzing fraud attempts highlights important signals, such as suspicious payment velocities, mismatched geolocations, or repeated email-card pairs. Observing repeated patterns (like the same IP address used across many new accounts) can reveal organized fraud rings. Tracking every significant fraud ring leads to new features, such as counters of repeated suspicious behaviors.
Some new features might provide minimal improvements if the network already captures that pattern. Continuous experimentation and offline A/B testing help confirm the benefit of each newly introduced feature. Large DNNs often extract subtle relationships on their own, but well-crafted features speed training convergence and highlight anomalies.
Explainability
A DNN’s hidden layers can feel opaque to users, so internal “risk insights” views are essential. Surfacing which signals contributed most to a flagged transaction helps businesses trust the system. Mapping addresses, IP geolocations, and shipping addresses clarifies suspicious patterns. Internally, monitoring how final layers weigh certain features explains decisions for support investigations. Exposing this logic to external users can help them adjust data inputs or set custom rules if certain patterns are falsely triggering blocks.
Example code snippet for model training
import tensorflow as tf
def build_model(input_dim):
inputs = tf.keras.Input(shape=(input_dim,))
# Branch 1
x1 = tf.keras.layers.Dense(128, activation='relu')(inputs)
x1 = tf.keras.layers.Dense(64, activation='relu')(x1)
# Branch 2
x2 = tf.keras.layers.Dense(128, activation='relu')(inputs)
x2 = tf.keras.layers.Dense(64, activation='relu')(x2)
# Combine branches
combined = tf.keras.layers.Add()([x1, x2])
combined = tf.keras.layers.Dense(64, activation='relu')(combined)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(combined)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
return model
Training this multi-branch DNN can run in parallel across GPUs. The architecture offers a balanced trade-off between memorizing low-level signals and generalizing complex relationships.
What if fraudulent actors change strategies abruptly?
Deep models adapt well if they regularly see updated examples. Incorporating fresh data and scheduling frequent retraining cycles allows the model to capture new attack profiles. Transfer learning is possible if new patterns partially overlap with historical trends. If the model sees a dataset where older examples carry less relevance, weighting recent data more heavily helps. Fine-tuning the network on new patterns without losing older knowledge keeps detection robust.
How do you ensure the model doesn't overfit?
Large networks risk memorizing random noise. Enforcing dropout, weight decay, and early stopping helps. Running offline validation on a holdout set reveals if the training error plummets while validation error spikes. If that occurs, reduce network size or increase dropout. Monitoring an area under the precision-recall curve is especially vital when classes are imbalanced. Tuning hyperparameters with cross-validation ensures stable performance across different segments.
How to handle interpretability requests from business stakeholders?
Sub-explanations about the top contributing features for a particular transaction score can be extracted from the gradient-based attributions of the final dense layers. Providing a table that shows which fields increased or decreased fraud risk allows direct feedback. Visual maps of IP addresses or shipping addresses help pinpoint patterns of possible card testing. Summaries of correlated transactions, based on name or email domain, provide further context. Building user interfaces that highlight these patterns in plain language fosters trust.
How can training speed be improved if data becomes 100 times bigger?
Distributing training workloads across multiple machines or GPUs is crucial. Mini-batch sizes can increase to keep GPUs fully utilized. Frameworks that support data parallelism or model parallelism (like TensorFlow or PyTorch with specialized libraries) help scale. Large-scale data pipeline tools can stream data without fully loading it into memory at once. Using mixed-precision floating-point can also accelerate operations on modern hardware.
What are the primary metrics to track?
Precision, recall, and false-positive rate are key. Precision measures how many flagged transactions truly are fraud. Recall measures how many fraudulent transactions the model catches out of all actual fraud. A small 0.1% false-positive rate keeps legitimate users from being blocked. Monitoring the cost of false positives vs. false negatives ensures the thresholds align with the business impact.
How to incorporate advanced methods like transfer learning and embeddings?
Embedding layers can transform categorical features such as merchant IDs or card tokens into dense, continuous vectors. Transfer learning can occur if you pre-train embeddings on large generic transaction data, then fine-tune them for specialized verticals (for example, digital goods vs. physical goods). Such embeddings capture domain-wide fraud signals while letting specialized fine-tuning adapt to each merchant’s unique profiles. Adding multi-task heads for different tasks (like risk scoring, chargeback prediction, or subscription abuse detection) leverages shared representations while customizing the final predictions.
What steps ensure data privacy and compliance?
Strict data segmentation and anonymization are critical. Personally identifiable information must be hashed or tokenized. Granular user permissions control who accesses raw features. Aggregated analytics and carefully controlled user-level data sets uphold compliance. The system must log usage for auditing, ensuring data usage remains aligned with privacy policies and local regulations.
How to keep false positives low in practice?
Continuous monitoring of flagged legitimate transactions is essential. When false positives spike, the team inspects specific cases, identifies shared traits, and adjusts features or threshold logic. Businesses can also set custom rules to override the automated model in certain edge cases, such as VIP customers or known addresses. Online learning techniques can quickly incorporate new information from mislabeled outcomes, gradually improving the system’s real-time decisions.
How to handle real-time latency constraints?
The scoring must occur in under 100 ms for a smooth user experience. Precomputing repeated features (like IP geolocation) is vital. Loading the model in memory and using efficient runtime frameworks (like TensorFlow Serving) cuts down inference time. Minimizing feature engineering steps at inference time also helps. For extremely tight constraints, model distillation or more efficient architectures can reduce complexity while preserving accuracy.
How would you debug tough support cases?
Examining suspicious transaction subsets in detail reveals if a legitimate payment was flagged by certain features (for instance, new IP address or velocity pattern). Searching the logs clarifies which signals triggered the high score. Visual tools can highlight the top feature contributions. Reviewing correlated transactions, addresses, or shipping information can confirm if it was a one-off anomaly or part of a larger fraud ring. Updating thresholds or adding a rule can fix repeated false positives.