
ML Case-study Interview Question: Optimizing Marketplace Recommendations Using Two-Tower Neural Network Models.


Browse all the ML Case-Studies here.
Case-Study question
A large online marketplace wants to increase user engagement and revenue by improving their recommendation system. They have massive user interaction logs, a diverse product catalog, and limited space for displaying recommended items. They want a machine learning pipeline that can handle data ingestion, feature transformations, model training, and real-time serving. How would you design and implement this system to optimize for both click-through rate and long-term user satisfaction?
Detailed Solution
A combined approach that leverages offline batch processing for feature engineering and an online serving mechanism for real-time predictions is common. The offline stage handles large historical datasets. The online stage handles real-time requests at scale. Key steps involve data ingestion, feature transformation, model training, model serving, and iterative evaluation with business metrics.
Data ingestion includes streaming user events from the website and batch data from past logs. A data warehouse stores them. A feature store or offline processing system collects aggregated features. These features might be user purchase history, item attributes, and contextual details. A Spark-based pipeline is often used for ETL tasks.
Feature transformations happen offline. Categorical variables are one-hot encoded, and continuous variables are normalized or bucketed. This reduces model bias toward skewed distributions. A context-aware approach includes session-based features and user’s device or location data.
Model training can use a neural network-based collaborative filtering approach. One model architecture includes a two-tower system. One tower embeds user features, another tower embeds item features, then a similarity metric produces a relevance score. This architecture is beneficial for scalable retrieval. A final ranking model refines top candidates to produce a final list of items.
Below is a simplified example using Python-like pseudocode:
import tensorflow as tf
def two_tower_model(user_features, item_features):
# Embedding for user tower
user_embedding = tf.keras.layers.Embedding(input_dim=user_vocab_size,
output_dim=embedding_dim)(user_features)
user_vector = tf.reduce_mean(user_embedding, axis=1)
# Embedding for item tower
item_embedding = tf.keras.layers.Embedding(input_dim=item_vocab_size,
output_dim=embedding_dim)(item_features)
item_vector = tf.reduce_mean(item_embedding, axis=1)
# Cosine similarity or dot product
score = tf.reduce_sum(user_vector * item_vector, axis=1)
return score
# Example usage
user_input = tf.keras.layers.Input(shape=(None,))
item_input = tf.keras.layers.Input(shape=(None,))
model_score = two_tower_model(user_input, item_input)
model = tf.keras.Model(inputs=[user_input, item_input], outputs=model_score)
model.compile(optimizer='adam', loss='mean_squared_error')
A learning-to-rank approach might optimize a specific loss function that measures the quality of ranked recommendations. A common function is the cross-entropy loss for classification or logistic loss for pairwise ranking. A fundamental binary cross-entropy loss can be shown as:
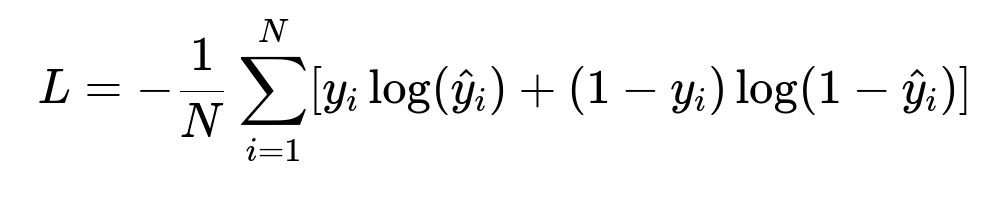
Where:
N is the total number of training samples.
y_i is the true label (clicked or not clicked).
hat{y}_i is the model’s predicted probability of a click.
Online model serving uses a low-latency service. A feature retrieval layer fetches relevant features. A model inference layer loads the trained model for scoring. A caching mechanism is helpful to reduce load by returning the most common user-item lookups quickly. A/B tests measure performance. A champion model is typically replaced only if a new version yields a significant gain in target metrics.
How do you handle cold-start scenarios?
A combined strategy uses metadata-based embeddings and content-based features for items with limited interaction history. Using side information such as product categories, textual descriptions, or brand attributes helps form embeddings. Collaborative filtering alone struggles for brand-new items. Content-based modeling gives an initial score for unfamiliar users or items.
How do you ensure the model remains up to date?
A regular re-training schedule updates embeddings based on recent user behavior. A continuous or incremental training pipeline is ideal. A near-real-time approach uses micro-batches to capture new signals. A rolling window or daily updates for production models keep predictions aligned with evolving user preferences.
How do you measure success beyond click-through rate?
User engagement metrics such as time spent and repeated sessions measure broader satisfaction. Downstream metrics like conversion rate, purchase frequency, and average order value indicate whether recommendations drive revenue. A multi-objective approach balances short-term clicks with sustained user satisfaction. Weighting each objective in the loss function or combining separate models for short-term vs long-term targets is common.
How do you mitigate potential biases in the recommendation pipeline?
Feature analysis ensures balanced representation for different items or user segments. Oversampling or weighting of minority categories helps avoid popularity bias. Attribution analysis or interpretability methods (for example, integrated gradients in neural networks) can diagnose biased behavior. Periodic fairness checks maintain responsible outcomes.
How would you handle large-scale model serving with minimum latency?
Horizontal scaling with container-based orchestration or serverless functions ensures capacity during traffic spikes. Vector databases or approximate nearest neighbor indices accelerate similarity searches. A multi-level architecture first narrows candidates (thousands) using a fast approximate model, then ranks a small subset (dozens) with a slower but more accurate model. GPU acceleration can handle heavy neural model inference loads.
How do you plan your data and feature validation strategy?
Data drift can break model assumptions. Automated checks compare distribution statistics (mean, variance, frequency of categorical levels) to reference values. If drift crosses thresholds, triggers alert or re-training. Feature validation includes schema enforcement, dimensional consistency, missing value checks, and outlier detection to ensure reliability before training or serving.
How do you handle edge cases and corner scenarios?
Safety checks for absent or malformed features ensure fallback logic. Graceful default embeddings or average item vectors reduce disruption. A conservative item set for uncertain predictions protects user experience. Regular logs highlight anomalies for debugging.
How do you iterate and refine this system?
User feedback loops guide refinements. Post-deployment analytics show misranking. Periodic reviews of feature engineering discover new signals. New deep architectures or specialized layers might improve personalization. Live experiments confirm benefits before broad rollout. Continuous integration pipelines run tests on data, code, and model performance to avoid regressions.