
ML Case-study Interview Question: Automating Media Interest Tagging with Ensemble Classifier Chains


Browse all the ML Case-Studies here.
Case-Study question
You lead a personalization project at a large media platform. The system has a list of user-selected interests and must surface relevant articles for each interest. The platform has historically relied on manually created queries using editorial tags to classify articles under these interests. These queries break easily, often miss relevant content, and depend on deep knowledge of legacy tagging rules. Propose a data-driven machine learning solution that replaces or supplements these manual queries. Specify how you would design the classification model, how you would label training data, and how you would handle edge cases where the model fails or over-generalizes. Outline your approach to validation, system deployment, and ongoing maintenance.
Detailed Solution
Building an automated interest-classification system requires multi-step reasoning. Starting with a labeled dataset is essential, even if the labels are imperfect. Existing queries can generate an initial labeled set, though it will include errors and omissions. Training a multi-label classification model on these noisy labels can produce better results if you carefully combine multiple representations of the text. One strategy is to build an ensemble of classifier chains using logistic regression, feeding it features from topic modeling (such as Latent Dirichlet Allocation), keyword frequencies, and Universal Sentence Encoder embeddings.
Training data comes from articles labeled via these queries. Noisy labels are inevitable, so simpler but well-regularized classifiers are less likely to overfit those errors. An ensemble approach averages predictions from multiple models to offset mistakes of any single classifier. During training, each classifier in the chain uses features from the article plus the labels predicted by previous classifiers, creating a rich multi-label predictor that captures correlations among interests.
Topic vectors from Latent Dirichlet Allocation capture global themes in each article. Keyword-based features isolate unusually frequent terms. Universal Sentence Encoder embeddings encode deeper semantics, especially after fine-tuning on internal text corpora. Combining these features gives the classification chain strong signals. For each interest, the model outputs a probability that an article fits that interest. Threshold tuning is done per interest to maximize precision-recall trade-offs.
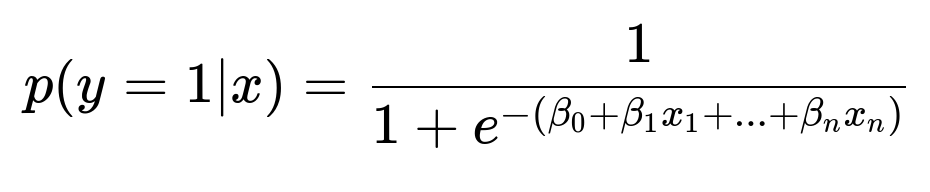
This formula shows the logistic regression probability for a binary label y=1 given input vector x. Parameters beta_0 through beta_n are learned weights. Each classifier in the chain applies such a function to its inputs. Overlapping labels can be captured by linking these classifiers together.
Human-in-the-loop validation is crucial. The model must not autonomously assign final interest labels without editorial oversight. This ensures nuanced context, like distinguishing “news stories about children” vs. “parenting-oriented content.” Integrating editorial feedback through periodic review cycles or partial overrides of the algorithmic output gives a balanced system. Productionizing the pipeline involves batch or streaming inference on new articles, storing predicted probabilities, and adjusting recommendation thresholds as user engagement metrics come in.
Long-term maintenance includes retraining on evolving content. If user interests shift or new editorial tags emerge, the model must refresh regularly. The model must also handle domain drift, where certain words or phrases change over time. Monitoring system performance through user engagement data and editorial input keeps the recommendations relevant.
Explaining the model to stakeholders is simpler with logistic regression. Weight vectors and predicted probabilities are more interpretable than black-box deep networks. For added interpretability, partial dependence plots or feature importance can show how certain topic or keyword features influence labeling. Combining interpretability with editorial curation helps build trust in the recommendations.
Python code for one of the logistic regression classifiers might look like this:
import numpy as np
from sklearn.linear_model import LogisticRegression
# Suppose lda_vec, keyword_vec, use_vec are combined feature vectors for articles
X = np.concatenate([lda_vec, keyword_vec, use_vec], axis=1)
y = labels_for_interest # 0/1 for a particular interest
model = LogisticRegression()
model.fit(X, y)
# Probability of belonging to this interest
probs = model.predict_proba(X)[:, 1]
Each chain classifier extends the input with previously predicted labels for earlier interests. The final ensemble prediction is typically the average of multiple such models, each using different random seeds or splits. That reduces variance and mitigates label noise.
Possible follow-up questions
How would you handle extremely unbalanced interests?
One approach is rebalancing the training data through under-sampling frequent classes or oversampling rare classes. Another is adjusting class weights in the logistic regression solver. If an interest is very rare, setting a higher class weight emphasizes correct classification. Precision-recall metrics guide final threshold selection. Frequent retraining can incorporate more examples of minority classes as new data accumulates.
How do you measure model success in a real system?
Offline metrics can include average precision, recall at specific cutoffs, and macro-averaged F1 across all interests. Online metrics focus on click-through rates, time spent, or user feedback on recommended content. A/B tests compare the new model’s performance to a baseline query-based approach. A significant gain in engagement or user satisfaction supports production rollout.
What if the hand-crafted queries are so noisy that they might mislead the model?
Noisy labels must be partially mitigated by simpler models with strong regularization. Ensemble methods dilute some label-specific noise. Some data cleaning or partial manual review can remove the most egregious errors. Active learning with editorial feedback helps produce cleaner labels over time. If certain interests are too poorly defined in the queries, you might temporarily drop those interests or augment them with curated labels from editors.
How do you integrate editorial knowledge if the automated model makes questionable classifications?
One approach is to provide editors with a user-friendly interface where they can accept or reject the model’s assignments in real time. Approved or corrected labels flow back into retraining. Over time, editorial input clarifies ambiguous topics and helps the system learn context nuances. Editors remain final gatekeepers when the stakes are high or where misclassification is sensitive.
Why not use a deeper neural network for classification?
Deep networks often excel in large data scenarios, but they can memorize noise in smaller or noisier datasets. Regularized logistic regression is simpler to interpret and faster to retrain. Using multiple feature types (topic vectors, keyword features, universal embeddings) and an ensemble of classifier chains can match or exceed deeper methods on moderate-scale data. If consistent improvements appear with deeper models in experimentation, then adopting them can be considered, but it must be weighed against interpretability and speed.
How would you update the system if new interests appear?
A new interest requires a new chain classifier trained on relevant data. Existing labeled articles or new editorially labeled examples seed the training. The logistic regression model for that interest is then appended to the ensemble. If an entirely new conceptual area emerges, you retrain or fine-tune the sentence encoder. Ongoing processes ensure new interests and content shifts are captured.
How do you handle inference at scale?
Batch processing pipelines can score new articles in scheduled intervals and store probabilities in a dedicated data store. Real-time scoring is possible if articles must be recommended instantly on publication. Caching model outputs for each article avoids repeated computations. Container-based or serverless deployments scale up or down as traffic fluctuates. Stream frameworks can feed the model as articles flow through content ingestion systems.
How would you explain performance drops over time?
Content trends, new editorial styles, or changes in interest definitions can degrade predictive accuracy. Domain drift happens when the language in articles shifts. Retraining with fresh data addresses drift. Regular performance monitoring and versioning the model helps isolate if performance drops are due to data changes, concept drift, or technical bugs.
How could you expand this system beyond article text?
Multimodal signals like images, audio transcripts, or social media discussions might enrich classification. Embedding these additional features into the logistic regression or a more advanced architecture can boost accuracy. Metadata like author or publication date can refine recommendations. Incremental tests gauge the impact of each new feature set before full deployment.