
ML Case-study Interview Question: Machine Learning Personalization for Scalable Travel Activity Search Ranking


Case-Study question
You are given a fast-growing platform offering unique local activities to travelers. The platform started with only a few hundred activities in a handful of cities, but it has since expanded to tens of thousands of activities worldwide. You must design and implement a search ranking system that maximizes user bookings while also preserving long-term business goals such as promoting high-quality activities and diversity of options. You have limited data in the initial phase and must still produce a meaningful ranking model. Over time, you gain more user interaction data, and your marketplace inventory expands significantly. How will you approach the ranking problem across different growth stages, ensuring the system scales and remains efficient at each stage?
Explain how you will:
Collect training data from user interactions.
Engineer features from users, activities, and queries.
Build a robust machine learning model pipeline that can handle personalization.
Overcome cold-start situations for new activities.
Incorporate business rules such as favoring higher-quality activities.
Implement online scoring infrastructure for real-time ranking.
Balance short-term booking gains with longer-term objectives like user satisfaction and supply-side fairness.
Finally, explain how you would test, deploy, monitor, and iterate on your ranking models. Assume you have freedom to choose a specific machine learning approach. Outline your steps and decisions clearly.
Detailed Solution
Building a search ranking system for an expanding marketplace requires a staged approach. Each stage must align with data availability, infrastructure constraints, and evolving business objectives. The progression typically moves from simple daily re-ranking to a fully online scoring infrastructure with personalization and deeper optimization.
First stage often starts with minimal data. Random re-ranking is a valid short-term approach while initial user interaction data accumulates. Once you have enough impressions, clicks, and bookings, switch to a small-scale supervised model. Create a labeled dataset by assigning positive labels to booked activities and negative labels to clicked-but-not-booked activities. Keep the feature set simple at first. Use basic metrics like area-under-curve (AUC) or normalized discounted cumulative gain (NDCG) to evaluate the model. If online experimentation is possible, do an A/B test to compare to the random baseline.
Second stage incorporates personalization features if you have enough data. Develop user-level attributes like previous bookings, traveled destinations, or category preferences. Include signals like distance between booked accommodations and the activity venue, trip dates, user clicks on category type, or time-of-day preferences. Ensure you avoid data leakage by only using features that existed before the user made a booking decision. Train two separate models: a personalized version for logged-in users and a fallback for logged-out traffic. A daily offline ranking approach might be enough for mid-sized inventories.
Third stage involves fully online real-time scoring. Implementing an online inference pipeline allows you to use fresh feature values at scoring time. Introduce query-level signals, such as distance from a typed location, number of guests, user origin country, and browser language. The system fetches features from a fast key-value store for users, from in-memory storage for items, and directly from the request for query parameters. This unlocks more sophisticated personalization and up-to-the-minute ranking. Conduct an A/B test comparing the new online approach to the offline baseline.
Fourth stage addresses business rules, which might include promoting new activities that show early promise, boosting high-quality activities (measured by user feedback, star rating, or additional structured signals), or maintaining diversity in top results. Achieve this by modifying the training labels or adjusting the loss function to give different weights for high-quality or diverse items. Validate that you do not compromise the primary objective of overall bookings.
Monitoring and explainability help sustain trust. Build dashboards to track how each activity’s rank changes over time and which features influence its position. Look for anomalies, such as a sudden drop or rise in ranking due to shifts in user preferences or host changes. Adjust your model or features if you see unwanted effects, such as price dominating results too heavily.
Below is a concise representation of a common loss function used in binary classification ranking tasks like logistic regression or gradient-boosted trees.
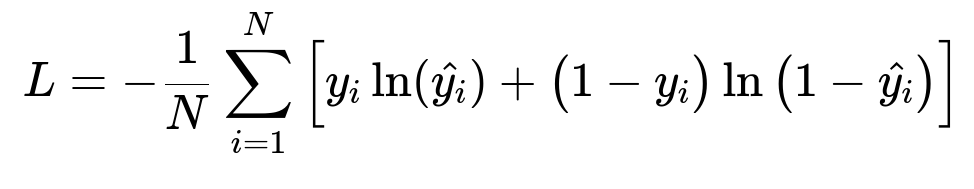
N is the total number of training examples. y_i is 1 if the user booked the activity and 0 otherwise. hat{y_i} is the model’s predicted probability of booking.
Lower L means better predictions. Expanding the objective with additional weights is one way to handle business rules, such as weighting certain positive labels more heavily if they meet high-quality thresholds.
Below is a simple code snippet for training a gradient-boosted decision tree (GBDT) classifier in Python:
import xgboost as xgb
import pandas as pd
import numpy as np
# Suppose df has columns:
# 'feature_1', 'feature_2', ..., 'clicked_or_not_booked', 'booked'
# We'll build a label: label = 1 if booked else 0 if clicked but not booked
df['label'] = df.apply(lambda row: 1 if row['booked'] == 1 else 0, axis=1)
features = [col for col in df.columns if col.startswith('feature_')]
X = df[features].values
y = df['label'].values
# Split into train and validation sets
train_size = int(0.8 * len(df))
X_train, X_val = X[:train_size], X[train_size:]
y_train, y_val = y[:train_size], y[train_size:]
# Create DMatrices for XGBoost
dtrain = xgb.DMatrix(X_train, label=y_train)
dval = xgb.DMatrix(X_val, label=y_val)
# Define parameters
params = {
"objective": "binary:logistic",
"eval_metric": "logloss",
"max_depth": 6,
"eta": 0.1,
"subsample": 0.8,
"colsample_bytree": 0.8
}
# Train model
eval_list = [(dtrain, 'train'), (dval, 'eval')]
bst = xgb.train(params, dtrain, num_boost_round=100, evals=eval_list, early_stopping_rounds=10)
# Predict probabilities and compute validation metrics
y_val_pred = bst.predict(dval)
This code trains a GBDT model with log-loss. It can be adapted for large-scale pipelines with daily or real-time scoring.
Continuous iteration is essential. Expand the feature set, incorporate short-term user actions, refine the loss function, and address position bias. Leverage real-time signals and experiment with new model architectures when the volume of data justifies it. Maintain performance dashboards to catch unexpected ranking patterns, such as too much emphasis on price or seasonal shifts not captured by the model.
How to Handle Tough Follow-Up Questions
1) How do you manage data leakage during feature engineering?
Check the time dimension. Only use data available before the moment of the user’s booking decision. If a click or booking happened after that decision, exclude it from the feature set. For example, do not include future average rating changes or future user clicks that occurred after the user made their booking. Ensure the pipeline reconstructs the historical state accurately.
2) How do you diagnose underperforming results in your A/B tests?
Compare offline metrics (AUC, NDCG) to online metrics (bookings, conversion). If the offline metrics look good but A/B tests fail to show improvement, investigate dataset mismatch, position bias, or user behavior changes. Inspect feature distributions and partial dependency plots to see if the model is overly fitting certain signals. Sometimes the offline test data differs from real production traffic, so real-world experiments may diverge from offline gains.
3) How do you handle model drift when user preferences change?
Refresh training data frequently. Recompute your features and retrain on recent user interactions. Use an online store for user attributes so you can update signals (like last-clicked category) in near real time. Re-run batch or streaming pipelines that feed the training process, and shorten retraining intervals if big shifts occur, like seasonal or global events.
4) How do you incorporate multiple objectives without hurting the main conversion metric?
Re-weight training examples, or modify your loss function to capture secondary goals. Assign higher weights to positive labels that align with business needs, such as high-quality bookings. Ensure you measure any trade-offs. Sometimes you aim for a slight dip in immediate bookings in exchange for better repeat bookings. Validate with offline and online metrics that measure both short-term bookings and any longer-term objectives like rebooking rate or user satisfaction scores.
5) How do you handle personalized ranking for large numbers of users without excessive computation?
Load item and query features in memory. Retrieve user features from a fast key-value store. Score on the fly for each query. Scale horizontally by adding more inference servers if throughput demands grow. Maintain only the necessary features in the store (recent categories clicked, time-of-day preference, etc.). If the store is updated in near real time, user-level signals remain fresh with minimal overhead.
6) How do you decide which new items might become top hits?
Look at early engagement signals (clicks, short-term bookings, star ratings from initial bookings, user feedback forms). Build a separate cold-start sub-model or heuristics that temporarily boost items that show strong early promise, preventing them from being overshadowed by mature listings with many reviews. Validate that the boost only applies within a certain window so subpar new items don’t remain artificially high for too long.
7) How do you explain ranking results to stakeholders?
Show how important features vary over time for each activity. Display partial dependency plots or side-by-side comparisons. Maintain dashboards that track ranking shifts in each market. Highlight price changes, rating drops, or user engagement dips. If business stakeholders or activity hosts see why a specific ranking changed, they can adjust their pricing, improve their offering, or fill in missing details.
8) How do you address trust and fairness concerns in the ranking?
Implement a system that helps less frequent hosts or minority categories surface in search. Consider fairness constraints that might ensure minimal coverage for certain categories or newly added local communities. Train or re-rank results post-model to enforce fairness if it aligns with product goals. Track metrics to see if your fairness approach impacts overall conversions or user satisfaction.
9) How do you test more advanced models, like neural networks, without risking production stability?
Start with offline experiments and smaller A/B tests in low-traffic segments. Compare performance to the existing GBDT approach. Ensure latencies remain acceptable. Gradually scale up traffic if results are promising. Keep a rollback plan ready in case performance degrades. If speed or complexity becomes a bottleneck, refine the model or use approximate search indexes.
10) How do you handle location-based queries differently from queries with no location?
Treat queries with a location or date range as higher-intent. Use features such as distance to user’s typed location and per-day availability. For broad queries with no location, focus on popular or high-engagement items. Consider re-ranking for diversity or novelty to capture user interest. Monitor how the top activities in these broad searches perform in terms of click-through-rate and conversion.
These detailed answers demonstrate a strong grasp of practical search ranking systems for a rapidly growing, two-sided marketplace.