
ML Case-study Interview Question: Enhancing Multilingual Grocery Search with LLMs and Vector Embeddings


Browse all the ML Case-Studies here.
Case-Study question
A rapidly growing online grocery platform operates in multiple countries with varied languages and culinary habits. The platform’s product catalog contains tens of thousands of items and a growing list of recipes. The firm wants to improve its search system to handle diverse queries from users, including typos, synonyms, and queries in multiple languages. They also want to integrate Large Language Model (LLM) capabilities for more intelligent retrieval without compromising speed. How would you architect a solution that leverages LLMs, vector embeddings, and a robust storage system to deliver accurate, real-time search results? Outline all steps, including how you would handle precomputation, model selection, embedding generation, and multi-country scalability. Address how you would test and validate the performance gains from this system.
Proposed Solution
Search Retrieval Overview
Search retrieval involves mapping user queries to the most relevant products or recipes. Queries can include misspellings, foreign language terms, or event-specific keywords. LLMs can interpret these diverse inputs, but raw inference for every request may be slow. Precomputation handles common queries by embedding them in advance. This approach ensures minimal latency.
Prompt-Based Query Enhancement
The system transforms user queries into more descriptive forms through an LLM prompt. The LLM translates short or ambiguous inputs into clearer descriptions. It also captures intent (birthday party, romantic dinner, or general interest). This transformation becomes a robust text vector via a small embedding model.
Embedding Computation
Precomputation embeddings happen for:
Common search queries collected from logs.
Catalog items and recipe text.
An appropriate embedding model (for instance a 1536-dimensional text-embedding model) converts each piece of text into a vector. The following formula measures the similarity between query vector Q and product vector P:
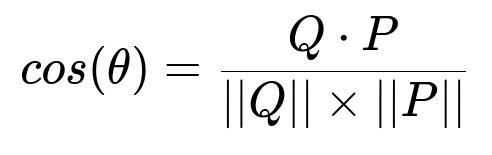
The parameter Q represents the query vector in text form, and P represents the product (or recipe) vector in text form. Q dot P means the sum of element-wise multiplications of vector entries. ||Q|| and ||P|| are the Euclidean norms of the respective vectors.
Higher cosine similarity indicates closer semantic meaning. This approach is resilient to spelling errors or linguistic variations.
Infrastructure with Open-Source Search Engine
The system uses a search engine that supports vector storage and k-nearest neighbors lookups in milliseconds. This engine stores:
Precomputed query embeddings.
Product and recipe embeddings.
When a new query arrives, the system checks if it exists in the precomputed set. If yes, the vector is retrieved from the cache. If no, the LLM generates a prompt-based description, computes its embedding, and then looks for top-matching items or recipes. Strict caching is applied to minimize calls to the embedding service.
Evaluation and Incremental Release
Offline tests use historical queries and clicks to gauge retrieval accuracy. The system is refined by adjusting prompts, model sizes, or ranking weights. It then rolls out in an online A/B test to live traffic. Metrics include click-through rate, conversion, and search speed. Gains are validated incrementally to avoid regressions in relevance or latency.
Code Snippet for Search Pipeline
import requests
import opensearchpy
# Step 1: Fetch precomputed embedding of query or generate on the fly
def get_or_create_query_embedding(query, embedding_cache, llm_endpoint):
if query in embedding_cache:
return embedding_cache[query]
else:
# Generate new prompt-based descriptive query
descriptive_query = call_llm_for_query(query, llm_endpoint)
# Convert to embedding
embedding = call_embedding_model(descriptive_query, llm_endpoint)
embedding_cache[query] = embedding
return embedding
# Step 2: Query vector search in OpenSearch
def retrieve_matching_items(query_embedding, opensearch_index):
client = opensearchpy.OpenSearch(...)
response = client.search(
index=opensearch_index,
body={
"query": {
"knn": {
"vector_field_name": {
"vector": query_embedding,
"k": 10
}
}
}
}
)
return response
The get_or_create_query_embedding function checks a cache. If the query embedding is missing, the LLM and embedding model are used. The retrieve_matching_items function uses vector-based similarity search.
Multi-Country Deployment
Multiple languages require generating descriptions and embeddings in each locale. The system can store language-specific embeddings and local synonyms or expansions. The pipeline ensures customers in each region see the correct items, even if they mix languages. Thorough local testing is essential to confirm correct coverage of different dictionaries and culinary terms.
How do you handle continuous improvement of this system?
Tricky aspects include evolving user behaviors, new products, new recipes, and updated LLM models. Continuous improvement involves:
Recomputing embeddings for new items.
Updating model prompts or fine-tuning to reflect linguistic changes.
Monitoring vector drift when the embedding service changes versions.
Conducting frequent A/B tests to confirm improvements in relevance and speed.
Follow-up Question 1
Why not embed every new query in real time using the LLM?
Real-time embedding for every new query leads to high latency and cost. Users expect results to update as they type. The LLM inference step adds seconds if done repeatedly. Caching a large fraction of historical and predictable queries significantly reduces wait times and operational fees.
Follow-up Question 2
How would you minimize risk from LLM performance fluctuations?
LLM responses can change with model updates. Validation procedures compare embeddings over time for the same prompts. If the new model deviates, re-tuning or partial rollback can be performed. Having robust fallback in the search engine also mitigates issues if the LLM starts returning odd outputs.
Follow-up Question 3
How would you handle ambiguous or incomplete queries?
LLM prompts produce a clearer textual interpretation of the query. For example, “ice” might translate to “Ice-making utilities.” The vector search captures the intent of that expanded prompt. The search engine can still look at literal matching if needed. The approach merges semantic signals from embeddings with traditional keyword search, providing robust coverage for ambiguous queries.
Follow-up Question 4
What are the primary metrics used in online A/B testing?
Click-through rate measures relevance when a user clicks on a retrieved result. Conversion rate tracks how often a user who searches for an item eventually purchases it. Search abandonment rate indicates dissatisfaction if users leave without clicking anything. Latency is crucial because slower responses can cause higher bounce rates.
Follow-up Question 5
How would you integrate recipes with product listings?
The pipeline stores both products and recipes in the vector engine, each with distinct embeddings. When a user enters a query, the similarity search can return either recipes or products. A re-ranking layer might blend or separate them based on context. If a user frequently clicks recipes, the system can adjust the ranking to favor recipe entities.
Follow-up Question 6
How do you maintain cost-effectiveness while using paid LLM services?
Caching embeddings for frequent queries avoids repeated calls. Batching embedding generation tasks lowers overhead. Offline generation for known queries and product descriptions helps. Monitoring usage ensures early detection of runaway costs. Budget-friendly approaches include limiting LLM usage to important or ambiguous queries.
Follow-up Question 7
What if the search engine must stay available when the LLM or embedding service is down?
Caching embeddings and storing them in the local search engine enables normal operation even if the LLM service fails. The system can fall back to a default keyword-based search for truly unknown queries until the external dependency recovers. Distributed caching across regions ensures resilience against outages in one data center.