
ML Case-study Interview Question: Adversarial Training for Context-Aware Grammatical Error Correction


Browse all the ML Case-Studies here.
Case-Study question
A global organization wants to build an AI-based system for grammatical error correction. They plan to treat it as a text-to-text transformation problem. They already have a traditional neural machine translation approach but struggle with semantic inconsistencies when correcting sentences. They want to incorporate adversarial training with a generator-discriminator architecture to improve contextual correctness and fluency. How would you design such a system, ensure stable training, and evaluate it thoroughly?
Detailed Solution
A generator is trained to transform an erroneous sentence into its corrected form. A discriminator distinguishes real corrected sentences from generated ones. Both models are trained in a min-max fashion.
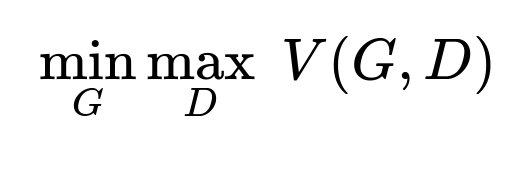
Here, G tries to minimize the difference between its output and the real corrected sentence. D tries to maximize its ability to distinguish real from generated corrections. The discriminator also gives a policy gradient-based reward signal to the generator, encouraging more accurate corrections.
Generator Architecture A sequence-to-sequence model with either an RNN-based encoder-decoder or a transformer-based encoder-decoder is used. It takes an incorrect sentence as input and outputs a corrected sentence. It is updated via conventional supervised losses and also via a reinforcement signal from the discriminator.
Discriminator Architecture A sentence-pair classifier is used to score (input_sentence, corrected_sentence). It estimates how likely the corrected_sentence is a valid rewrite for input_sentence. This approach captures both grammatical correctness and semantic alignment. The discriminator then guides the generator by penalizing outputs that drift semantically or fail to fix errors.
Adversarial Training The generator produces corrected sentences. The discriminator evaluates them against ground-truth rewrites. The generator receives high reward for more plausible corrections, nudging its parameters to produce outputs that match human quality. This adversarial signal complements standard loss metrics.
Stable Training Considerations Use warm-start training by pre-training the generator with supervised data. Also, pre-train the discriminator to recognize correct vs. incorrect text. Then start the adversarial loop. Apply gradient clipping and schedule the adversarial updates carefully to avoid mode collapse or vanishing gradients.
Evaluation Evaluate with standard GEC metrics such as GLEU or MaxMatch for error-correction quality. Also check semantic fidelity by comparing meaning preservation. Empirically verify that the discriminator’s sentence-pair approach helps preserve context.
Example PyTorch-Like Code Snippet for Adversarial Loop
generator_opt = torch.optim.Adam(generator.parameters(), lr=...)
discriminator_opt = torch.optim.Adam(discriminator.parameters(), lr=...)
for batch in data_loader:
incorrect_sentences, correct_sentences = batch
# Generator forward
gen_outputs = generator(incorrect_sentences)
# Pre-train or supervised loss
loss_supervised = supervised_loss(gen_outputs, correct_sentences)
# Discriminator forward on real and fake
real_preds = discriminator(incorrect_sentences, correct_sentences)
fake_preds = discriminator(incorrect_sentences, gen_outputs.detach())
# Discriminator loss
disc_loss = -(torch.log(real_preds) + torch.log(1 - fake_preds)).mean()
discriminator_opt.zero_grad()
disc_loss.backward()
discriminator_opt.step()
# Generator adversarial loss
fake_preds_for_gen = discriminator(incorrect_sentences, gen_outputs)
gen_loss_adv = -torch.log(fake_preds_for_gen).mean()
# Combine supervised and adversarial
total_gen_loss = loss_supervised + lambda_adv * gen_loss_adv
generator_opt.zero_grad()
total_gen_loss.backward()
generator_opt.step()
Use curriculum strategies like gradually ramping up the lambda_adv that multiplies adversarial loss. Monitor both discriminator and generator losses to keep training stable.
Follow-Up Question 1
How do you handle semantic consistency if the generator starts producing corrected sentences that look grammatically fine but alter the meaning?
Answer
A sentence-pair discriminator captures whether the output remains faithful to the original sentence. It looks at the original text and the proposed correction together. This helps penalize outputs that stray from the original semantics. Explicit semantic similarity metrics can also be added as part of the reward. Another approach is adding auxiliary classifiers that check whether key content words match the source meaning, and incorporate that feedback into the generator’s loss. Combining these strategies constrains the generator to not only fix errors but also preserve intent.
Follow-Up Question 2
How do you mitigate mode collapse in adversarial training for language tasks?
Answer
Warm-starting the generator via supervised pre-training is crucial. That allows the generator to produce reasonable outputs before adversarial updates begin. Balancing training steps between generator and discriminator also helps. If one side trains too fast, the other side has difficulty converging. Gradient clipping, careful learning rate selection, and using a regularization term in the discriminator can further stabilize training. Periodic resets of the discriminator, or updating it multiple times per generator update, also reduce mode collapse.
Follow-Up Question 3
How do you compare adversarial training to standard n-gram-based objectives for GEC?
Answer
N-gram-based approaches optimize overlap between predicted and reference text. This sometimes punishes creative rewrites that still fix errors. Adversarial training directly optimizes correctness, fluency, and semantic fidelity through the discriminator’s reward. This yields higher-quality corrections. The discriminator also enforces stricter requirements on coherence, which encourages the generator to match not only local token patterns but also contextual accuracy.
Follow-Up Question 4
How would you tune hyperparameters for balancing supervised loss and adversarial loss?
Answer
Set a hyperparameter (lambda_adv) to weigh the adversarial loss relative to the supervised loss. Start with a small lambda_adv so the generator remains anchored in correct rewriting. Gradually increase it as the discriminator becomes more competent. Track validation metrics, especially GEC accuracy and fluency. Adjust lambda_adv to avoid overshadowing the supervised signal. Also tune the discriminator learning rate so it neither becomes too strong nor too weak relative to the generator.
Follow-Up Question 5
What are the main challenges in deploying such a solution in production?
Answer
Maintaining inference speed is crucial. Large adversarially trained models may be slow. Quantization or model distillation can help. It is also challenging to handle domain-specific text, where the model might see unusual terminology. Continual learning is important to adapt. Ensuring consistent user-facing suggestions requires robust fallback for cases the model is uncertain. Monitoring real-world error patterns helps refine the model over time.
Follow-Up Question 6
If you had to extend this system to multilingual error correction, what extra considerations come up?
Answer
You would need multilingual embeddings or a multi-branch architecture to handle different languages. Grammar rules vary widely, so language-specific pre-training might be needed. Building parallel corpora of erroneous-correct pairs is harder in some languages. The discriminator should be capable of interpreting the source and target text in multiple languages. Cultural or stylistic norms also differ, so the model might require domain adaptation or fine-tuning for each language.
Follow-Up Question 7
How would you validate that adversarial training actually improves user experience?
Answer
Conduct offline evaluations with standard GEC benchmarks and measure improvements in correction quality. Also run human evaluations on diverse text samples. Check if user satisfaction scores increase when suggestions are more contextually relevant. Logging real user interactions can reveal acceptance rates of suggested corrections. This helps confirm that adversarially trained models provide more helpful and coherent rewrites compared to purely n-gram-optimized systems.