
ML Case-study Interview Question: Real-Time Manufacturing Step Identification Using Sensor Data and FastDTW


Browse all the ML Case-Studies here.
Case-Study question
You are a Senior Data Scientist at a large consumer healthcare company. The company wants to optimize its toothpaste manufacturing. They have multiple sensors streaming data, such as pressure and temperature, every few seconds. The goal is to identify distinct manufacturing steps in real time and alert operators if any step takes too long or deviates from expected conditions. The team wants a robust solution that can align real-time sensor patterns with predefined step templates. Propose a complete system design that uses Fast Dynamic Time Warping, explains data requirements, and ensures the approach scales to high-volume production. Also outline how to maintain good accuracy despite FastDTW’s approximation.
Full In-Depth Solution
Overview
Each manufacturing step has an expected sensor pattern. FastDTW calculates similarity between incoming sensor data and these predefined patterns. One key requirement is near real-time processing, so regular DTW might be too slow. FastDTW uses down-sampling and a search window constraint, which accelerates computation but introduces approximation error. The solution starts by capturing continuous sensor data, standardizing each feature, creating process templates for steps, and establishing a distance threshold to detect matches.
Step Templates
The system requires a historical template for each manufacturing step. Operators or process engineers supply these reference templates, indicating normal sensor trajectories over time. The real-time data stream is compared against these references. The best match determines which step is ongoing.
FastDTW Core Formula
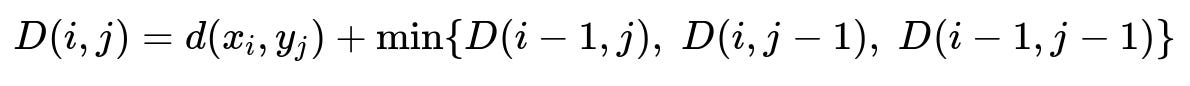
This recurrence relation calculates the cumulative cost matrix D, where d(x_i, y_j) is the Euclidean distance between data point x_i in one series and y_j in another. D(i,j) is the minimal cumulative alignment cost up to indices i in one series and j in the other. FastDTW constrains the search area for D(i,j), reducing computations.
Implementation Details
Incoming sensor readings are batched in windows that match or exceed the length of each step template. The system standardizes these readings to mean 0 and standard deviation 1. FastDTW is then applied to compute distance against each reference pattern. If the distance is below a global threshold, the step is considered detected.
The threshold is determined by analyzing historical data. Operators validate that threshold so small deviations do not trigger false positives. The system checks steps in sequence, but it can also skip a step if detection fails, avoiding lock-ups. This ensures robust detection even under streaming conditions.
Real-Time Data Flow
Data ingestion occurs every few seconds through sensor arrays feeding a data collector. The collector pushes data to a cloud-based pipeline, where the FastDTW-based model processes these readings. Once a match is found, the system logs the detected step and alerts operators if a step’s duration exceeds acceptable limits. The final outcome is displayed on a dashboard that tracks real-time progress.
Example Code Snippet
Below is a simple example of how FastDTW might be used, substituting actual streaming code with dummy sequences:
import numpy as np
from scipy.spatial.distance import euclidean
from fastdtw import fastdtw
# Sensor sequences as arrays
sequence_a = np.array([1.0, 2.0, 3.0, 3.1, 2.9])
sequence_b = np.array([0.9, 2.1, 3.2, 3.0, 3.0])
distance, path = fastdtw(sequence_a.reshape(-1,1),
sequence_b.reshape(-1,1),
dist=euclidean)
print("Computed FastDTW distance:", distance)
print("Warp path indices:", path)
The scaling to a production environment adds more complexity with streaming frameworks, distributed processing, and robust data storage.
Accuracy Versus Speed
FastDTW trades off some accuracy. Manufacturing processes often have large sensor data volumes, so near-linear time complexity is crucial. If accuracy demands are higher, standard DTW can be employed for shorter sequences or when computational resources are plentiful. Another option is tuning the search radius parameter in FastDTW, which narrows or widens the search region.
Threshold Selection
A global distance threshold is typically set for each step. It is derived from past runs where the system calculates typical alignment distances. An excessively strict threshold leads to missed detections. An overly loose threshold triggers false positives. Careful engineering ensures stable detection for routine manufacturing runs and edge cases.
Data Preprocessing
Standardization ensures each sensor feature has equal impact. Without scaling, features with larger absolute values dominate. Optional smoothing or filtering reduces sensor noise. The pipeline can also examine derivative features, such as rate of change in temperature or pressure, before applying FastDTW.
Monitoring and Maintenance
Once in production, continuous monitoring tracks false positives and detection misses. Any drift in sensor patterns might require re-training step templates or adjusting the threshold. Operators can calibrate the system if process changes alter the shape or duration of manufacturing steps.
Follow-Up question 1
How would you handle the scenario where multiple sensors have different data ranges or different frequencies of collection?
Answer
Different data ranges require scaling. Each sensor’s values are standardized so the mean is 0 and standard deviation is 1 for each feature. If sensors sample at different rates, data alignment is done before FastDTW. Interpolation or resampling creates consistent time intervals. A pipeline step merges these streams into synchronized windows. FastDTW is then applied on unified data vectors. This ensures each sensor contributes equally to the overall distance calculation.
Follow-Up question 2
If a step is missed in real time and the system keeps looking for step N instead of N+1, how do you ensure the process detection continues without a deadlock?
Answer
The model searches for consecutive steps but also attempts to detect the next step in parallel. It compares incoming data with step N and N+1 templates. If N fails to match but the distance to N+1 drops below threshold, the system confirms the process has advanced. This prevents the pipeline from freezing on a step that may have already occurred. A maximum time window also serves as a fallback. If time passes beyond normal bounds for step N, the system shifts its search to N+1, preserving real-time coverage.
Follow-Up question 3
How would you evaluate the trade-off between pure DTW and FastDTW for long time series?
Answer
Traditional DTW has quadratic time complexity in sequence length. For extended sensor readings, this can be slow. FastDTW uses down-sampling and restricts the warping path, improving speed. The trade-off is potential misalignment in local details. The decision depends on resource constraints, response time needs, and acceptable error. If the manufacturing process requires precise detection of subtle differences, the full DTW might be considered for final confirmation. If real-time responsiveness is critical, FastDTW is preferred. Tuning the search window size gives a middle ground, allowing partial improvement in accuracy with some speed sacrifice.
Follow-Up question 4
How would you deploy and maintain this system in production?
Answer
A cloud pipeline ingests sensor readings, standardizes them, and stores the data. A containerized service runs the FastDTW-based step detection logic. Real-time dashboards visualize each detected step and highlight irregularities. Automated alerts notify operators when thresholds are exceeded. A continuous monitoring layer logs performance metrics, false positive counts, and missed detections. Periodic reviews update thresholds and reference templates to match any process or hardware changes. This cyclical improvement process keeps the system reliable.