
ML Case-study Interview Question: Accelerating Vehicle Image Labeling with Embedding Similarity and Iterative Refinement.


Case-Study question
You are given a massive dataset of millions of vehicle images. Some images show the front of the vehicle, some show the interior, and others show random details or even unrelated objects. You must devise a way to label all images with the correct category (for example: front, rear, interior, etc.). The categories are not always clear upfront, and you may need to update your category set over time as you discover rare or unusual images. Propose an end-to-end solution, including how you would quickly generate a high-quality labeled dataset, train a suitable model, and integrate the system back into a large-scale platform.
Most In-Depth Solution
Overview of the Challenge
You have a large image repository. Some images belong to easy classes (common viewpoints), while others are rare (unusual interior angles or unrelated objects). Manual labeling of millions of images is impractical. You need a strategy to accelerate labeling and refine categories on the fly.
Step 1: Collect a Representative Sample
You want a curated subset of images from the platform that covers the common classes and captures rare patterns. You combine a balanced sample (covering various vehicle generations or models) plus a random sample (covering random images). This ensures broad coverage of classes, including those you are not fully aware of yet.
Step 2: Generate Embeddings
You use a pre-trained deep learning model to create embeddings for each image in the sample. The model could be from any popular open-source model repository. You slice off the final classification layer and extract the penultimate layer’s vector output. Images with similar patterns in pixel space have embedding vectors that are close in distance.
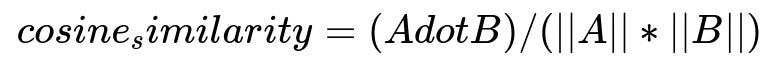
Here, A and B are embedding vectors for two images. A dot B represents the dot product of A and B. ||A|| is the magnitude (norm) of vector A, and ||B|| is the magnitude of vector B. The closer the ratio is to 1, the more similar the images.
Step 3: Similarity-Assisted Labeling
You build a simple web tool (for example, using Streamlit in Python). You pick or upload a “reference” image. You calculate the cosine similarity of all unlabeled images against that reference. The tool sorts images by highest similarity first. You then bulk-label those top images. If you upload a steering wheel image, you quickly find other steering wheel images and label them all in one pass. This boosts labeling speed.
Step 4: Model Training for Prediction-Assisted Labeling
You train a small classification model on the initial labeled subset. You then run this model on the unlabeled data to predict labels. You sort images by predicted class probability. You quickly confirm or correct these predictions in bulk. The model steadily improves as you feed back more confirmed labels.
Step 5: Reiterate and Expand
You repeat embedding-assisted and prediction-assisted labeling in cycles. Each cycle increases the total labeled set. Rare classes become easier to handle because you can explicitly search for them with embedding similarity. You can also refine or add new categories at any time without losing momentum, because the process is interactive.
Step 6: Final Deployment
You move from the small model to a larger, more powerful model on a dedicated GPU cluster. You deploy the final model behind an API or service layer to label incoming images in near real-time. You retrain or finetune as new categories emerge.
Sample Python Code for Embedding Extraction
import torch
import torch.nn as nn
from torchvision import models, transforms
from PIL import Image
# Example pretrained model (ResNet18)
model = models.resnet18(pretrained=True)
model.fc = nn.Identity() # Remove final classification layer to get embeddings
model.eval()
def get_embedding(image_path):
img = Image.open(image_path).convert('RGB')
transform_pipeline = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
img_tensor = transform_pipeline(img).unsqueeze(0)
with torch.no_grad():
embedding = model(img_tensor)
return embedding[0].numpy() # Return as numpy array
This code snippet shows how to extract embeddings with a standard pre-trained ResNet. You then compute similarities between embeddings.
Potential Follow-Up Interview Questions
Below are key probing questions. Each question is in H2 font, followed by comprehensive answers.
How do you ensure your labeled sample is representative enough to generalize?
A diverse dataset must reflect real-world variation. You first sample common classes (because they appear frequently) and deliberately include images from every known subcategory. You also randomly sample to discover outliers. You may check class distribution after an initial pass and resample underrepresented classes. You might rely on domain knowledge to identify vehicle categories or angles you suspect are missing. When the tool reveals unusual images (like damaged parts or distracting objects), you assign or create new labels if they appear often enough to be significant.
Ensuring representativeness involves continuous monitoring. You watch how your model performs on validation slices of fresh data. If misclassifications cluster around a particular new angle or feature, you know you must expand the training data for that category.
Why not outsource labeling to external services?
Outsourcing can be costly and risky for data quality. You lose domain expertise if crowdsourced workers are unfamiliar with vehicle features. Inaccurate labels slow model convergence. Rapid iteration is harder because you cannot instantly create or remove categories. Building an in-house tool keeps the feedback loop tight and captures domain-specific insights. You get immediate control over the labeling process, ensure data confidentiality, and refine categories on the fly.
What if your chosen similarity approach misses certain visual nuances?
Cosine similarity on generic embeddings might fail for very subtle differences if the pre-trained network has not encountered those specifics. You can mitigate this by transferring weights from a specialized model that was trained on automotive images or by finetuning the embedding model on a small labeled set of your images first. You can also combine embedding-based similarity with a metadata filter (for example, a known year or make of the vehicle) to narrow the candidate images. If nuance remains a problem, you refine your approach by gathering more examples of the subtle class and retraining an embedding model specifically for that domain.
How do you decide the threshold for model confidence when auto-labeling?
You consider both precision and recall trade-offs. If you set a high threshold for auto-label acceptance, the tool only confirms labels that the model is very sure about. That maintains high precision but might mean you miss many correct but lower-confidence predictions. You can adopt a tiered approach. High-confidence predictions get automatically accepted, moderate-confidence predictions require quick manual review, and low-confidence predictions are skipped until the model has more training data. You can systematically adjust these thresholds after observing real-world performance.
How do you handle the incremental addition of new categories?
The tool must allow the user to create a new category at any stage. You then gather a few examples for that category, label them manually, and run the same embedding-similarity or model-prediction approach to discover more examples in the unlabeled pool. Because the approach is iterative, the new category quickly accumulates labeled samples. You retrain the classification model to incorporate that category. If the model architecture remains the same, you adjust the final classifier layer for the new label set. If you frequently add categories, a more flexible approach like a multi-label system or a prompt-based architecture could help.
How does training a larger model on a GPU cluster differ from training the small prototype model?
The prototype model is fast to train on a small subset of data. It helps you label the dataset without huge compute overhead. The final large model is trained on more data and might use a deeper architecture (like a bigger backbone network). It requires powerful GPU resources to handle longer training times, higher memory usage, and potentially advanced hyperparameter tuning. The large model’s advantage is better accuracy and generalization to the full image repository. You integrate it into a production environment (with an API or batch pipeline) so the platform can label images at scale. Monitoring, logging, and resource optimization are crucial at this stage to handle the volume of images efficiently.
How would you keep improving and monitoring the system after deployment?
You track two main areas. First, watch runtime performance, such as throughput and latency of your labeling service. Second, continuously evaluate accuracy using real-time feedback or random sampling. You can insert fresh unlabeled images into the system, label them (or partially label them) with the tool, and see if the system’s predictions match. You track confusion matrices by category to see which categories have higher misclassification rates. When new patterns arise (for example, new vehicle models or new angles), you incorporate them by collecting examples, labeling them, and retraining or finetuning. You keep a loop of monitoring → labeling → retraining → redeploying.
How would you handle images with multiple relevant labels?
You might need a multi-label classification approach if a single image can belong to multiple categories (like front view plus partial interior, or if it has a unique feature visible). You adjust your training objective from a single cross-entropy loss per sample to a multi-label binary classification approach. You produce a binary output for each label. For labeling, you adapt your tool to allow multiple selections. You still use embedding similarity, but you might separately filter images by different reference images, each focusing on a particular aspect. This is more complex but sometimes necessary if categories are not mutually exclusive.
How do you guarantee domain experts trust your labeling system?
You keep the process transparent. You show domain experts sample images and predicted labels. You let them manually adjust if needed. You demonstrate quantitative evaluation metrics (accuracy, recall, precision) on a hold-out test set. You also involve domain experts early, so they participate in setting categories and confirm the labeling logic. Trust grows when the system shows consistent high-quality outputs, especially on known edge cases. Providing an explainable component (like embedding visualization for similarities or score distributions for model predictions) also reinforces confidence.
Would your approach generalize to video or text data?
Yes, the concept extends to other modalities. For video, you can extract embeddings frame by frame using a pretrained video model or by extracting key frames and applying an image model. For text, you embed sentences or documents and then use a similar similarity-assisted labeling strategy. The core idea is to reduce data items to vectors that capture semantic meaning, then leverage those vectors to cluster and label items in bulk. The same prediction-assisted approach applies once you have enough labeled examples. Adjustments might be needed for domain-specific embeddings and unique features (like time structure in video).
Conclusion
You create a fast and iterative system that combines embedding-based similarity for rapid data discovery, a small classification model for early prediction assistance, and a final large-scale model for fully automated labeling. This pipeline handles massive unlabeled datasets, supports dynamic category updates, and provides the foundation to serve high-volume image classification needs.