
ML Case-study Interview Question: Boosting Streaming Retention: Personalized Recommendations via Deep Neural Networks.


Browse all the ML Case-Studies here.
Case-Study question
A large enterprise faced customer churn in its streaming service. User engagement varied, and retention dropped when certain content recommendations mismatched user preferences. You must design and deploy a system that improves user retention through better personalized recommendations, using Machine Learning approaches on huge volumes of streaming data. Propose a detailed plan for data gathering, feature engineering, model training, deployment, and continuous evaluation.
Provide:
Straightforward explanation of your end-to-end solution. Include how you manage data preprocessing, the type of models used, the objective function, and your approach to retraining. Describe how you handle system performance and scalability.
Detailed Solution
Understanding the Data
Historical user interactions included session logs with watch durations, likes, skips, and user profile data (age, preferences, subscription details). Metadata for content items included genre, popularity, and release date. Engagement events were large-scale and arrived daily.
Data Preprocessing
Ingest data from streaming logs into a distributed file system. Convert logs into a structured format. Create user-content interaction records. Clean anomalies and missing values. Normalize numeric fields such as watch time. One-hot encode categorical variables such as device type.
Feature Engineering
Construct user-level embeddings that represent content preferences. Build content embeddings from textual descriptions and metadata. Combine user embeddings and content embeddings as input features for the model.
Model Architecture
Use a deep Neural Network for user-item preference prediction. Stack fully connected layers with ReLU activation. Output a probability that the user will engage with a recommended item. Train the model with a binary cross-entropy objective. Keep a final sigmoid output layer.
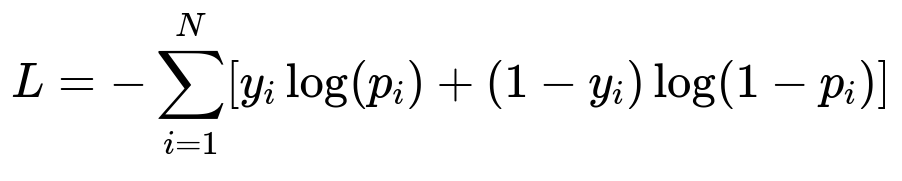
Here:
y_i is the actual label, indicating whether the user engaged with the content.
p_i is the predicted probability of engagement.
N is the total number of training examples.
Minimize L by updating network parameters with stochastic gradient descent. Shuffle data to avoid biases. Check validation accuracy after each epoch.
Deployment
Export trained model parameters. Store them in a versioned repository. Serve predictions through an online microservice. Connect the microservice to an event queue that sends user profile updates. Scale the service with container orchestration. Retrain regularly with fresh data.
Continuous Evaluation
Track engagement metrics, retention rate, and watch-time patterns. Monitor real-world feedback. Compare predicted engagement probability against actual outcomes. Implement an automated pipeline that triggers retraining if performance drops below a threshold.
Example Code
import torch
import torch.nn as nn
import torch.optim as optim
class RecommendationModel(nn.Module):
def __init__(self, input_dim):
super(RecommendationModel, self).__init__()
self.hidden1 = nn.Linear(input_dim, 128)
self.hidden2 = nn.Linear(128, 64)
self.output = nn.Linear(64, 1)
self.sigmoid = nn.Sigmoid()
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.hidden1(x))
x = self.relu(self.hidden2(x))
x = self.sigmoid(self.output(x))
return x
model = RecommendationModel(input_dim=300)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Example training loop:
for epoch in range(10):
for batch_data, batch_labels in data_loader:
optimizer.zero_grad()
outputs = model(batch_data)
loss = criterion(outputs, batch_labels)
loss.backward()
optimizer.step()
Train with historical data. Store the best model weights for inference. Retrain on new data to adapt quickly.
How to Handle Tough Follow-up Questions
How do you ensure the model generalizes and handles drift?
Train on balanced and diverse samples. Track data drift by checking distribution changes of features over time. Compare the current data distribution with historical data. Trigger retraining when new distributions differ significantly from training data. Use incremental learning if possible.
How do you optimize performance at scale?
Partition the dataset using a distributed infrastructure that scales horizontally. Train multiple instances of the model on different data shards. Merge learned parameters if the architecture allows. Use micro-batching and parameter servers. Deploy inference services close to user data to reduce latency.
How do you handle cold starts for new users or new content?
Initialize user or content embeddings with default average values. Collect first few interactions to update embeddings. Use collaborative filtering signals from similar items or users to bootstrap initial recommendations. Explore new content to gather engagement signals.
How do you validate your solution in a real-world setting?
Deploy an A/B testing setup. Expose a subset of users to the new model. Compare retention metrics against a control group. Measure watch duration changes and subscription renewal rates. Confirm statistical significance before a full rollout. Keep logs for further error analysis.
Why might you consider an ensemble approach?
Combine tree-based models with deep Neural Networks to leverage structured signals and latent features. Tree-based methods handle sparse data and outliers. Neural Networks capture complex interactions. Aggregate predictions to improve stability and reduce variance. Evaluate performance gains against added complexity.