
ML Case-study Interview Question: Machine Learning for Grocery Substitutions: From TF-IDF to Deep Learning Recommendations.


Browse all the ML Case-Studies here.
Case-Study question
A large online delivery platform started with prepared food delivery and then expanded to grocery products. The engineering team noticed that many items were out of stock, leading to canceled items in orders. They needed an automated solution that suggests suitable replacements in real time to keep customers happy, avoid refunds, and prevent lost sales. You are a Senior Data Scientist hired to design a machine learning approach for generating high-quality substitution recommendations. How would you approach this problem from end to end, considering data collection, modeling, and iterative improvements?
Detailed Solution
Overview of the challenges
Customers often order items that might be out of stock in grocery inventories. Delivery agents cannot always find these items on store shelves. The platform wants to show relevant alternatives that match the original item closely. This prevents back-and-forth texts or calls and improves satisfaction. The core challenge is constructing an algorithm that scores potential substitutes effectively, then scales as the product offering grows.
Phase 1: Unsupervised approach
The platform had limited labeled data at first. The team opted for text-based similarity of items using TF-IDF. The raw names of products were transformed into vectors, and the system calculated cosine similarity between them. Relevant categories were further restricted by a taxonomy-based filter. Customers who ordered a 12-pack of a certain soda would see 12-packs of the same brand or other brands.
Phase 2: Binary classification with LightGBM
The platform introduced a thumbs-up or thumbs-down feedback mechanism. This created labeled data on whether a proposed substitution was good or bad. The team built a binary classifier to predict the probability that one item is a good substitute for another. LightGBM was chosen for its performance, ease of tuning, and track record. Historical labels showed that quantity was more important than brand for certain products. A 12-pack of a competitor’s soda was preferred over a 2-liter bottle of the same brand.
Phase 3: Deep learning recommendation model
Higher volumes of feedback made it feasible to implement a deep learning approach in PyTorch. This model used embeddings for items, combined with features in a multi-layer perceptron (MLP). A sigmoid function then generated a probability score for the substitution. The team leveraged existing semantic embeddings trained on user search behaviors. This captured more nuanced relationships. For example, canned peas instead of canned beans is closer in concept than swapping beans for corn.
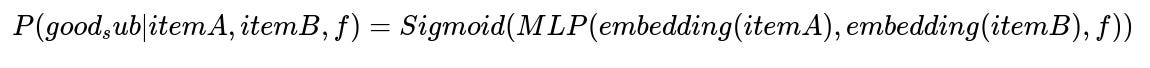
Where P(good_sub | itemA, itemB, f) is the probability that itemB is a suitable replacement for itemA given additional features f. embedding(itemA) and embedding(itemB) are vector representations of the items. MLP(...) is a multi-layer perceptron combining both item embeddings and other signals. Sigmoid(...) ensures the output is a probability between 0 and 1.
Below is a simplified code snippet illustrating how the team built such a PyTorch model:
import torch
import torch.nn as nn
class SubstitutionModel(nn.Module):
def __init__(self, embedding_dim, dense_feature_dim):
super(SubstitutionModel, self).__init__()
self.bottom_mlp = nn.Sequential(
nn.Linear(dense_feature_dim, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU()
)
self.top_mlp = nn.Sequential(
nn.Linear(embedding_dim*2 + 32, 64),
nn.ReLU(),
nn.Linear(64, 1)
)
self.sigmoid = nn.Sigmoid()
def forward(self, embeddingA, embeddingB, dense_features):
bottom_out = self.bottom_mlp(dense_features)
combined = torch.cat([embeddingA, embeddingB, bottom_out], dim=1)
out = self.top_mlp(combined)
return self.sigmoid(out)
In this example, embeddingA and embeddingB represent learned item embeddings. dense_features include relevant numeric or categorical signals, such as brand similarity or package quantity. The bottom MLP processes the dense features. The model then concatenates everything and feeds it into a top MLP followed by a sigmoid layer.
Metrics and experimentation
The team used human-curated datasets for manual evaluation early on. They eventually relied on classification metrics like AUC. Production experiments measured acceptance rate, coverage, and the reduction in refunds. The platform also tracked how frequently customers indicated satisfaction with these suggestions.
Next steps
The team planned to refine item metadata for harder categories (such as produce and meat), incorporate product attributes like organic or kosher, and personalize recommendations. Some customers care more about brand loyalty than others, so personalization can refine these predictions.
Q1: How would you address the cold-start problem when introducing an entirely new product category?
A new product category has limited historical data. A simple approach uses unsupervised TF-IDF or semantic embeddings trained on analogous categories. Item metadata such as brand name, product attributes, and taxonomy hierarchy fill gaps. Collecting explicit or implicit feedback (like a thumbs-up or purchase data) allows retraining models over time. Ramping up sampling and showing carefully chosen substitutes for these new items expedites feedback collection.
Q2: Why not rely solely on classic collaborative filtering from the start?
Collaborative filtering requires sufficient user-item interaction data. Early in a new category, the platform cannot rely on user co-purchase signals. The team instead used textual or taxonomical metadata to generate initial recommendations. This overcame the sparse data problem by leveraging similarity in product descriptions and categories, which provided decent results until enough labeled feedback accumulated.
Q3: What were the main benefits of transitioning from LightGBM to a deep learning model?
A deep learning approach uses embeddings that capture more subtle relationships among products, even when direct feedback is sparse. The MLP architecture can learn complex interactions between product attributes (such as brand, package size, or user preferences). LightGBM performed well on structured features, but deep learning embeddings uncovered richer representations, especially for rare items that might not have had many ratings.
Q4: How would you measure the impact of these recommendations in production?
The team would run A/B tests comparing a new recommendation model with a control. Key metrics include coverage of recommendations for out-of-stock items, acceptance rate (how often a recommended substitute is accepted), and overall impact on refunds. Measuring user satisfaction through post-delivery ratings or net promoter scores helps confirm improvements. Business metrics such as increased average order value or reduced churn also indicate success.
Q5: How do you handle real-time model scoring when thousands of items might be potential substitutes?
Precomputing embedding vectors for every item saves time at inference. When an item goes out of stock, the system retrieves the embedding of the out-of-stock item and calculates a similarity or model-based probability with candidate item embeddings. A well-designed retrieval process filters out obviously irrelevant items. A final re-ranking pass can use the full model to narrow down to the top few recommendations. Distributed caching and optimized nearest-neighbor searches can speed up this process.
Q6: How do you generalize these solutions to other recommendation systems beyond grocery substitutions?
The same approach applies wherever alternative recommendations are needed. The concept of text-based similarity, user feedback collection, and iterative model improvements can power cross-selling in e-commerce or track suggestions in a media library. Collecting item metadata, user feedback loops, and rich embeddings remains pivotal. The pipeline design for offline training and real-time serving follows the same pattern of data collection, labeling, model training, and A/B testing for continuous optimization.