
ML Case-study Interview Question: Combating Coordinated Spam: Real-Time Anomaly Detection, Clustering, and Automated Rule Generation.


Browse all the ML Case-Studies here.
Case-Study question
A large-scale social platform faces waves of coordinated spam attacks. The attackers create massive numbers of accounts and posts linking to suspicious domains. You are the Senior Data Scientist leading an initiative to detect these attacks quickly, cluster them, and automatically generate rules to block future waves. How would you design and implement an end-to-end system that:
Explores incoming traffic to detect sudden bursts of suspicious activity with minimal latency. Clusters potential attackers based on shared features such as domains, IP ranges, and device type. Generates specific short-term blocking rules that neutralize the spam wave while minimizing false positives. Archives or retires these rules once the attack subsides.
Explain your approach, proposed architecture, machine learning methods, data pipelines, and how you ensure continuous adaptation against evolving spammers.
Detailed solution
Overall Approach
Use real-time anomaly detection on time-series data to flag unusual spikes in suspicious behavior. Gather event records from flagged intervals, then cluster users by common features. Automatically generate blocking rules targeting attributes that dominate each cluster. Send sampled users for human review before activating these rules. Finally, deactivate or archive the rules once the attack ends.
Anomaly Detection
Monitor incoming user events, such as post creations or link shares, at fine-grained intervals. Track features like user location, IP address, device type, and domain. Forecast expected counts and compare them with actual counts. If actual minus expected exceeds a threshold, label it anomalous.
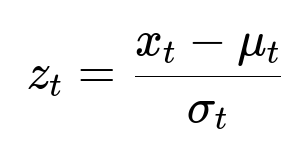
Here, x_t is the observed event count at time t, mu_t is the predicted average event count, and sigma_t is the predicted standard deviation. If z_t is above a critical cutoff (for example, 3 in absolute value), raise an anomaly flag.
Use a data processing job that checks event counts across different feature combinations (for instance, city + device type). Split out only those combinations that exceed thresholds, and store those event records in a data lake.
Clustering Suspicious Events
Run a job that groups anomalous events by domain, IP range, or other relevant dimensions. For each group, examine feature distributions (IP, account age, post text templates). If a few values dominate most events within that group, mark it as a spam cluster. For example, 90 percent of the accounts might be new signups, linking to one domain, and sharing identical post text.
Automated Rule Creation
Extract the primary conditions that define each cluster. Compose a rule statement that blocks all accounts meeting those conditions. One example in a SQL-like language might look like this:
where user_account_age < 3 days
and user_device = 'android'
and post_text starts_with('Check out our website')
In production code, wrap this in a service (for example, a pipeline that writes the final rule conditions into a rule engine).
Review and Deployment
Before permanently activating the rule, sample user accounts from the newly clustered group and send them to internal review. Once validated, push the rule to an online rule engine to block or deactivate matching accounts. Keep these rules active for a limited period. Decommission them once the corresponding spam wave ceases.
Rule Retirement
Track the lifetime of each rule. If the number of matches drops below a low threshold for several days, retire the rule automatically. This practice avoids harming legitimate users who might accidentally match the conditions in the future.
Example Python Snippet for Anomaly Detection
import numpy as np
import time
historical_data = ... # Past event counts
model_mean = np.mean(historical_data)
model_std = np.std(historical_data)
def is_anomaly(current_count):
z = (current_count - model_mean) / model_std
return abs(z) > 3
# Simulate streaming
while True:
current_count = get_current_event_count() # Implement accordingly
if is_anomaly(current_count):
send_to_suspicious_queue(current_count)
time.sleep(3600)
This snippet illustrates checking the z-score in real-time and routing suspect events to further analysis.
Follow-up question: How would you handle spiky noise from normal user activity that might trigger false alerts?
Use domain knowledge and historical patterns. Identify known high-traffic events (like major holidays) and exclude them from generic anomaly detection. Maintain separate baselines for different user cohorts. Combine multiple features (domain, device, region) so that noise in one feature doesn’t trigger an alert unless the pattern is unusual across multiple dimensions. Implement a grace period or rolling window to reduce one-off spikes from normal usage spikes.
Follow-up question: How do you ensure the automated rules don’t deactivate legitimate users?
Limit rule scope by setting thresholds on user volume and event frequency. Only deploy a rule if a large group of users (for example, more than 10) shares highly specific traits. Automatically expire rules to reduce long-term false positives. Sample flagged accounts for human review to confirm high accuracy before fully activating the rule. Log all deactivations and compare to user appeal reports; if appeals spike, investigate and refine rules.
Follow-up question: How would you adapt your system over time when spammers mutate and change tactics?
Implement continuous monitoring of new anomalies. Retrain the anomaly detection models and re-run the clustering pipeline regularly. Allow dynamic feature selection; when a certain feature (for instance, a single IP address) becomes irrelevant, the system still watches for new features like suspicious domain name patterns or device signatures. Maintain a feedback loop with historical spam signals so that repeated mutated attacks still share subtle patterns the system can catch.
Follow-up question: How would you integrate this solution with a larger machine learning platform?
Build data ingestion pipelines that feed real-time events into an anomaly detection engine. Use a feature store to store relevant user attributes. Send flagged events to a central cluster manager that runs the clustering algorithm. Host the rule generation service in a modular architecture so that the final rule definition can be quickly pushed to the online rules engine. Link this pipeline to a metadata system that catalogs each rule, its start time, and performance metrics.
Follow-up question: How do you evaluate effectiveness and measure success?
Track precision, recall, and latency to identify how many spam accounts were caught accurately and how quickly. Compare the number of spam reports from users before and after deploying rules. Monitor false positives by analyzing appeals or reactivation rates. Conduct A/B experiments in which a fraction of traffic does not receive the new rule, and compare spam outcomes. Maintain metrics dashboards to see trends in spam attempts, cluster sizes, and user growth.