
ML Case-study Interview Question: Accurate Retail Demand Forecasting Using Transformers and Scalable MLOps


Browse all the ML Case-Studies here.
Case-Study question
A rapidly growing online retail platform wants to improve its demand forecasting system to reduce waste and prevent stockouts across multiple warehouses. They have large volumes of historical sales data, multiple seasonal and external features such as weather and promotions, and they need a robust, scalable system that can handle hundreds of millions of predictions daily. How would you design a machine learning solution, ensure data quality, handle continuous retraining, manage potential drifts, and integrate the system into an existing operational infrastructure so that demand is forecasted accurately at scale?
Detailed Solution
Start by setting up a straightforward baseline. Simple methods like moving averages or ARIMA can clarify whether a more complex model is truly necessary. These basic models also act as fallback mechanisms.
When scaling to a massive product catalog with warehouses in different regions, a deep learning architecture can exploit richer input features. Transformer-based approaches such as Temporal Fusion Transformers (TFT) often excel because they handle multiple covariates effectively.
Model Architecture and Data Pipeline
Establish a pipeline that ingests structured data (order history, item properties, promos, holidays) and unstructured or semi-structured data (weather forecasts). Transform them into time-series features. Train your transformer-based model on these sequences to predict future demand. High-level attention-based mechanisms model temporal and cross-feature dependencies effectively.
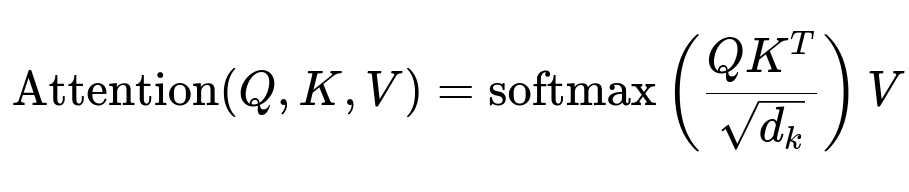
Q represents the query projections derived from your target sequence tokens. K and V come from your feature embeddings. d_k is the dimensionality of those key vectors. The softmax operation finds the weights over V.
Use frequent retraining to handle product introductions, new warehouses, and shifts in buying behavior. Automate the process by scheduling training jobs on GPU-equipped instances. Track performance across subsets (each product group or warehouse) to confirm improvements before deploying any new model.
Ensuring Data Quality
Proactively monitor input data. Validate essential columns (dates, item IDs, numeric ranges). If your training or inference data fails these checks, switch to a last-known-good prediction. This prevents invalid data from propagating into production. Below is an example of how to integrate Pandera checks in Python:
import pandera as pa
from pandera import Column, Check
weather_features_validation_schema = pa.DataFrameSchema(
columns={
"avg_cloud_cover": Column(checks=Check.in_range(0, 1), nullable=False),
"min_temperature": Column(checks=Check.in_range(-30, 50), nullable=False),
"max_temperature": Column(checks=Check.in_range(-10, 60), nullable=False),
"avg_wind_speed": Column(checks=Check.in_range(0, 20), nullable=False),
},
unique=["key_delivery_date","key_fc"],
)
# Example usage in your data pipeline
sampled_dataframe = sample_snowflake_table(table_name, num_rows_sample)
weather_features_validation_schema.validate(sampled_dataframe)
If your validation triggers, the pipeline falls back to previously confirmed predictions and logs an alert. This approach handles anomalies or drifts in incoming data.
Monitoring and Deployment
Precompute daily (or hourly) predictions in batch for all required item-warehouse combinations, instead of predicting on the fly. Batch processing handles large sets of items efficiently, reduces latency, and offers an automatic fallback. Store predictions in a fast retrieval system. If you notice any model performance issues, revert to a stable baseline. Log each prediction for later analysis.
Implement a model tracker to compare key metrics like Mean Absolute Error (MAE) or Root Mean Squared Error (RMSE) across item categories. A new model only goes live if it consistently outperforms the old one on critical metrics.
Scalability and Fault Tolerance
Adopt distributed compute resources to handle frequent retraining. Maintain a flexible microservices-like architecture that scales horizontally under high load. Keep your workflow orchestrated with simple scheduling (for example, using cron jobs or an Airflow pipeline) to run training and inference at set times. Deploy your model in a container-based environment that can replicate easily.
How do you handle data drift in live systems?
Monitor real-time performance by comparing actual demand vs. predictions. Track the error distribution and watch for sudden changes. If errors exceed a threshold, investigate potential data or concept drift. In practice, schedule incremental retraining more frequently during drastic shifts (e.g., new seasonal behavior). Keep your fallback mechanism ready at all times.
How do you manage cold-start items or entirely new warehouses?
Initialize predictions with the simplest approach (e.g., average of similar product categories) or partial historical analogs. Once enough data accrues, let the main model train on those items. Speed up adaptation with transfer learning from existing models if items share features with known categories.
What steps ensure correctness if the model starts producing anomalies?
Design your system to detect unusually high or low forecasts compared to historical norms. Use validation rules (like the Pandera snippet) to flag anomalies. If flagged, block those predictions in real time and revert to recent correct predictions. Log all details for root-cause analysis.
How do you optimize your infrastructure for frequent training of deep models?
Set up GPU-enabled containers or specialized cloud instances. Ensure your data pipeline is efficient with advanced load balancing. Use specialized frameworks supporting multi-GPU and distribution strategies if the dataset is large. Cache intermediate results to avoid reprocessing feature engineering steps repeatedly.
How do you validate the transformer models are better than simpler baselines?
Establish a test set or a rolling forecast window. Compare performance metrics for both the baseline and the transformer. Validate results across multiple time periods, product families, and warehouses. The new model should outperform in most subsets and not degrade in others.
What if the model’s predictions are good overall but occasionally fail for certain items?
Check if the failing items are underrepresented in training data. Augment the data pipeline or add relevant features. If those items are inherently unpredictable (extreme seasonal or external factors), create specialized sub-models. Use your fallback approach for such items if the error rate remains high.
How do you monitor and troubleshoot issues after deployment?
Record every model output. Periodically compare them with actual demand. Investigate errors and identify patterns. For instance, if under-predictions cluster around specific weather conditions, refine that feature. Implement dashboards that alert you when certain error metrics pass a threshold.
How do you handle large scale concurrency with so many predictions?
Batch processing handles concurrency well. Generate predictions for all items in chunks. Store them in a low-latency cache. Calls for predictions instantly receive the stored values. This architecture is efficient and avoids repeated, on-demand scoring that can overload GPU resources.
How do you ensure you never ship broken predictions into production?
Implement test checkpoints for data integrity, model performance, and system functionality. Run them automatically before updating the model. Maintain version control on your model pipeline. If a test fails, do not deploy. Rely on your last validated model so your system remains stable.
How do you decide on the best forecast horizon for operational needs?
Align your forecast horizon with operational constraints. For daily ordering, a one-day horizon might be enough. For supplier negotiations, a longer horizon may be needed. Combine multiple horizons if your supply chain has short-term and long-term requirements.
What if data is temporarily unavailable from external APIs?
Have backup features. For instance, if the weather API fails, use average seasonal weather or default values. Your fallback approach might be a simple time-series model ignoring external features. Log the event and investigate the outage later.
How would you handle promotions or events that heavily skew normal demand patterns?
Tag those events as special features in your data. Train your model to factor them in. If new promotions arise, maintain a mechanism for adding new event features. If the skew is severe, set up a distinct model or retrain with emphasis on event data.
How do you ensure your forecasting system will scale with more products, countries, or warehouses?
Adopt a microservices or container-based approach. Each component of the pipeline (data extraction, feature transformation, model training, batch inference) can replicate easily. Precompute all predictions in large batches on a robust cluster. Stash results in a reliable data store. Add nodes when you expand. Confirm no single service becomes a bottleneck.
How do you combine multiple models if you want ensembling?
Have a meta-layer that gathers predictions from each model, then decide a final forecast (for example, a weighted average). Validate ensembles carefully because merging multiple complex models can introduce unexpected bias. Ensure thorough monitoring, so if the ensemble approach underperforms, you revert to a simpler method.
How do you mitigate waste if the forecast is wrong?
Introduce safety buffers if an item’s production cost is high, or the item is perishable. Identify acceptable over-forecast margins. Combine forecast data with downstream optimizers (stock control, supply chain orchestration) that handle final ordering decisions. Track how your forecast impacts actual waste levels.
How do you handle spiky or intermittent demand items?
Implement specialized methods that focus on sparse or zero-heavy data. Some items need a separate model that captures sporadic jumps (for instance, intermittent item forecasting). Evaluate whether the main pipeline is robust enough or if you need custom logic.
How do you test the system before launching live?
Use shadow testing. Feed real-time data to your new pipeline but do not let it affect operations. Compare the predictions with the active system’s forecasts. If results are stable and produce fewer errors, switch to the new pipeline.
How do you retrain and upgrade models during peak seasons without risking downtime?
Run new training jobs off-peak. Deploy the new model gradually. If metrics remain stable, roll it out to full traffic. Maintain quick rollback. Separate the training environment from live inference to avoid performance hits on user-facing processes.
How do you handle incremental improvements once the core deep learning system is live?
Maintain a continuous improvement loop. Gather insights from your logs. Experiment with additional features or new architectures. Use A/B testing on subsets of your products. If the updated model outperforms, gradually expand it across the catalog.
How do you keep the system interpretable for stakeholders?
Produce daily metrics to compare forecast vs. actual. Report feature importances or attention weights that highlight factors strongly influencing demand. Schedule knowledge-sharing sessions with operations teams so they understand how the model’s predictions tie into daily decisions.
How do you ensure the solution remains robust over time?
Design the pipeline with reliability checks. Monitor the entire chain, from data ingestion to final predictions. Validate data, model outputs, and business metrics. Use automated alerts if anything drifts out of expected ranges. Regularly retrain, refine features, and revise your fallback logic.
Use these strategies to create a demand forecasting system that balances complexity and reliability. This ensures strong predictive accuracy for day-to-day operations while retaining resilience through fallback mechanisms if anything in your pipeline fails.