
ML Case-study Interview Question: Adaptive On-Device Keyboard Dictionary Management Using Time Decay & Edit Distance


Browse all the ML Case-Studies here.
Case-Study question
A technology company built a mobile keyboard application that personalizes spelling and autocorrect suggestions based on each user's unique vocabulary. They require the solution to work entirely on the device for privacy reasons. The keyboard must learn new words that are not in the default dictionary, detect and ignore random “casual” inputs (extra letters, missing apostrophes, etc.), and continuously adapt which words it remembers by removing rarely used or obsolete words. The system must load fast, remain responsive, and stay within strict memory limits. How would you approach building and evaluating such a system?
Proposed Detailed Solution
On-Device Personalization
Personalizing on the device prevents sending user data to external servers. It avoids privacy risks and eliminates the need for internet access to generate suggestions. A local model also avoids complex server syncing.
Memory Constraints
Average mobile devices offer limited memory to a keyboard process. Loading large language models can strain RAM. A memory-mapped key-value structure can read only relevant entries for a typed context. Caching computations, especially for repeated words, cuts down load time.
Time-Based Decay for Rare Words
Removing obsolete words prevents infinite dictionary growth. A time-based decay score reduces the probability of a word if it has not been used recently. An example formula:
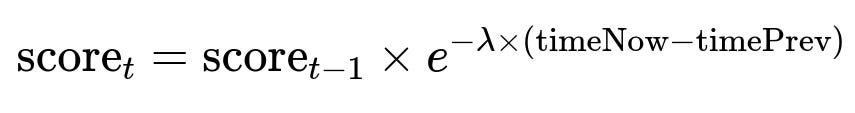
score_t is the updated score for a specific word at the current time. score_{t-1} is the word’s previous score. lambda is a decay constant. timeNow - timePrev is the elapsed time between consecutive uses of that word, measured in any consistent unit (like seconds). Words with lower score are removed once storage is tight.
Identifying Noisy Inputs
Inputs with irregular lengths of repeated letters, missing basic punctuation, or random casing are flagged and excluded. Simple regex matching and custom rules help filter them out. This ensures the model does not treat “heeyyy” as valid.
Edit-Distance Threshold
A new word is learned if repeated often enough to confirm it was intentional. An edit-distance calculation can distinguish a valid new term from common typos of standard words. One typical form of edit distance, d(i, j), can be represented as:
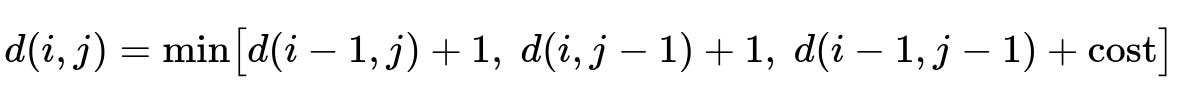
d(i, j) is the distance between the first i characters of one string and the first j characters of another. cost is 0 if characters match, or 1 otherwise. If the distance from a new term to a known standard word is small, it is likely a typo. The system waits for enough confirmed occurrences before suggesting the new term.
Evaluation and Testing
An offline replay simulator tests the model by simulating user typing sessions with known sequences of words. It checks whether the system correctly excludes casual spelling, retains frequently used new terms, and does not degrade application performance. Logs confirm fewer incorrect suggestions are offered, while acceptance of correct suggestions is slightly higher.
Additional Follow-Up Questions
How would you handle extremely frequent but casual usage patterns in certain communication contexts, such as quick chats with friends that have many repeated letters or slang terms?
Such usage might blur the lines between casual and intended words. A direct approach is adjusting the rules or thresholds for flagging casual terms. Lower thresholds can temporarily permit repeated letters if the user consistently repeats them. This might involve separate dictionaries for formal and informal contexts. A potential approach is to tag each input’s context (e.g., chat vs. email) and selectively reduce the penalty for repeated letters in casual chat contexts. This can be done without changing the entire global model by switching dictionary modes or adjusting regex filtering rules on the fly.
What happens when the available dictionary space is nearly full, but the user keeps adding new words?
The time-based decay function provides a dynamic ranking of words based on recent usage. If space is nearly full, the model prunes the lowest-ranked entries first. This ensures the user’s newest repeated words receive space. Ensuring old words vanish gracefully without abruptly disappearing is managed by threshold-based removal. The user rarely notices those words are removed because the frequency of usage was low.
How would you measure whether your model is improving the user’s typing experience?
Comparing metrics before and after deploying the personalized model is key. One metric is the rate of reverted suggestions: how often users delete or replace the keyboard’s autocorrections. A drop in reverted suggestions implies better alignment with user intent. Another metric is acceptance rates: how frequently users keep the proposed correction. Elevated acceptance indicates the model is helping. Performance logs also track average memory use and latency to confirm the keyboard remains responsive.
How would you adapt your approach if you needed to sync personal dictionaries across multiple devices?
Maintaining on-device personalization complicates multi-device consistency. One potential approach is implementing a secure, opt-in sync that transfers only the learned dictionaries—still encrypted—between the user’s devices. Sensitive data never goes to third-party servers in plain text. Alternatively, a federated learning approach might train partial parameters on each device and aggregate them without uploading raw text. The core idea is to ensure user data remains private while merging knowledge across devices.
What modifications would you make to manage multilingual users who need custom terms in multiple languages?
Each language can have a separate personal dictionary. The model detects which language the user is currently typing. A quick language classifier can switch among dictionaries in real time. Alternatively, a single dictionary can store language tags and usage frequencies for each entry. For words shared across languages, any usage can increment the same record. The biggest challenge is ensuring memory constraints stay manageable. Frequent checks on which dictionaries have the least-used words help keep overall storage from exploding.
How do you ensure user privacy is never compromised if your system includes analytics or logging?
Only aggregated metrics should leave the device, such as the number of suggestions accepted or reverted, without transmitting actual typed data. For debugging, logs can store abstracted references instead of raw text. Approaches like differential privacy or secure enclaves reduce any chance of reconstructing sensitive content. Strict policies in code review and logging frameworks further protect user data, preventing accidental exposure.
Why might you avoid a purely server-based approach for this personalization system?
A purely server-based system requires continuous internet connectivity. Users in poor network conditions would lose personalization benefits. It also raises privacy concerns because personal vocabulary is exposed to a remote server. Device-only solutions solve both issues and simplify the design by not requiring server synchronization. The user gains control over what is learned and stored, and personal data never leaves the device.
How do you handle model updates if you discover a better approach for personalization?
A versioning mechanism can deploy updated models through routine application updates. Backward compatibility ensures existing dictionaries remain valid. Migrating dictionary data into new models can involve a conversion script triggered the first time the new model version runs. This preserves user vocabulary while adopting new logic. Repeated offline testing guarantees that updates do not degrade performance or cause data loss.