
ML Case-study Interview Question: Unified Next-Product Retrieval for E-commerce Using BERT Sequence Models.


Browse all the ML Case-Studies here.
Case-Study question
A large e-commerce platform offers both organic product recommendations and sponsored ads. They need a single retrieval system that can handle in-session user actions and recommend next products across different surfaces (search, item detail page, cart, etc.). The catalog has millions of products, spread across many retailers. The existing systems rely on product co-occurrence, popularity, and similarity signals, but do not handle the exact sequence of user actions. How would you design a unified contextual retrieval system that predicts the next product a user may engage with, and how would you scale it to millions of items? Provide a detailed approach covering model architecture, training procedure, evaluation, and practical trade-offs.
Detailed Solution
Problem Framing
The system must predict the next product a user may interact with in a shopping session. At a high level, the model tries to find p(P_i | P_t1, P_t2, ...), where P_t1, P_t2, etc. are product interactions in sequence.
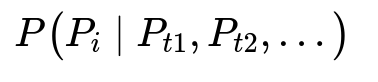
Here P_i denotes the i-th product in the catalog, and the conditional probability depends on previously interacted products. The system sorts products in descending order of this probability and selects top-K items for final ranking.
Sequence Model
A BERT-like transformer is trained with a Masked Language Modeling approach. The training data consists of user interaction histories as sequences of product IDs. During training, a certain portion of the tokens are masked, and the model tries to predict them. During inference, the unmasked sequence representation is used to compute probabilities for possible next products.
Transformers can handle long-range dependencies. The self-attention layers capture correlations among previously interacted products. For large product vocabularies, the model might map rare product IDs to an out-of-vocabulary token.
Catalog Size Constraints
The vocabulary can exceed millions of products. Training and inference become challenging with such a large set. A solution is restricting vocabulary to popular products plus an out-of-vocabulary token. For full coverage, approximate nearest neighbor search can help. Embeddings from the transformer output are matched to a vector index of all products.
Handling Retailer-Specific Products
Many items share a canonical identity across retailers. Others, like unbranded produce, do not. The base model uses product ID tokens, which may not generalize well for those unbranded products. Alternative approaches (like text-augmented embeddings) can group identical items.
Popularity Bias
The model often suggests popular items over niche ones. A post-processing step or downstream ranking model can re-rank and boost underrepresented items. Filtering or re-scoring helps ensure product diversity.
Practical Implementation
Training data is extracted from user sessions, preserving the order in which products were viewed or added to cart. The model uses a sequence length (like 20) to focus on the most recent interactions. Any code snippet for the training loop follows standard transformer-based Masked Language Modeling style:
import torch
import torch.nn as nn
from transformers import BertModel
class NextProductPredictionModel(nn.Module):
def __init__(self, vocab_size, hidden_dim):
super().__init__()
self.bert = BertModel.from_pretrained("bert-base-uncased")
self.linear = nn.Linear(hidden_dim, vocab_size)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids, attention_mask=attention_mask)
last_hidden_state = outputs.last_hidden_state
logits = self.linear(last_hidden_state)
return logits
At inference, the sequence encoding is used to compute scores for each product in the limited vocabulary. If approximate nearest neighbor search is used, the hidden state vector is matched against a large index of product embeddings.
Offline Evaluation
Recall@K is calculated by checking how often the ground truth next product appears in the top-K predictions. Masking sequence order degrades performance (10–40% drop), confirming the importance of precise sequence information.
Unified Retrieval
Both ads and organic recommendations share the same next-product prediction engine. Maintenance costs are reduced by removing parallel retrieval systems. Each downstream ranking layer can then optimize for different objectives, such as revenue for sponsored items or user satisfaction for organic items.
How would you address edge cases where the user adds no items to the cart?
A model trained purely on product sequences has little data when the user has not interacted with anything yet. One workaround is to use popular products or historically top-purchased items as a cold-start fallback. Another approach is to incorporate extra signals such as user profile data, location, or seasonal factors. If the model supports text input (like search queries), initial user search terms can help seed recommendations.
How do you incorporate more contextual signals like user search queries?
Including queries requires modifying the model inputs. Instead of just product IDs, the sequence includes tokens representing search terms. At the embedding layer, product tokens and query tokens have separate learned embeddings. The transformer attends to both product history and textual signals, which boosts personalization.
How do you handle performance issues with extremely large catalogs?
When the item vocabulary is in the millions, storing the entire output layer is expensive. Two techniques help. One is restricting the vocabulary to high-traffic products plus an out-of-vocabulary token for rare items. Another is approximate nearest neighbor search. The model produces embeddings for the user’s sequence, and we do a similarity search in a vector database indexing all products. This avoids computing scores for every product ID.
Why did you choose a BERT-like model over alternative sequence models?
Empirical tests showed that simple BERT-like architectures perform better than or on par with XLNet or other models on these next-product prediction tasks. BERT’s Masked Language Modeling approach helps the model learn bidirectional context from user interaction sequences. XLNet can yield similar results but may be slower to train for this particular setup.
How do you evaluate the impact of the last few products in the sequence?
Empirical evaluation reveals that the most recent products strongly influence the next product. Restricting sequences to around 20 products captures most of the predictive context. If the sequence is too long, older interactions dilute the model’s focus. Checking top-K recall with different truncation lengths confirms the diminishing returns of older items.
Could popularity-based approaches alone achieve similar success?
Pure popularity-based retrieval is simple but often fails for individualized recommendations. Sequence-based models substantially outperform them. Popularity signals do appear in the final ranking because frequent items dominate training data. A strong next-product prediction system still surpasses popularity heuristics in recall and user satisfaction metrics.
How do you ensure diversity in recommendations?
You can post-process the top-K list to de-duplicate products of the same brand or category. A secondary model or heuristic can reduce item redundancy. This ensures users do not get repetitive recommendations, which can happen if the transformer overfits on popular items.
What are the main benefits of a unified retrieval system?
It simplifies architecture and maintenance. Ads and organic surfaces share a central embedding space and get consistent next-product predictions. Engineers can iterate faster by improving a single retrieval layer. Each vertical (ads or organic) can apply independent ranking logic. The performance lift can be observed across the platform, boosting both transaction volume and ad revenue.