
ML Case-study Interview Question: Predictive Ranking of Restaurants for Food Delivery Expansion Using XGBoost


Browse all the ML Case-Studies here.
Case-Study question
A company in the food delivery space wants to build a Machine Learning system that identifies and ranks off-platform restaurants to onboard. The system should discover which off-platform merchants will provide the most value to customers and expand the company’s overall addressable market. The company’s sales team will use these rankings to target priority leads. How would you design an end-to-end solution that (1) collects merchant data, (2) builds appropriate features, (3) defines a success label for on-platform merchants, (4) trains and evaluates the model, (5) generates daily predictions and rankings, and (6) measures the business impact of the model?
Detailed solution
Data pipeline and infrastructure
Data is collected from external vendors and internal sources. The main dataset includes information about each potential merchant’s geolocation, cuisine type, reviews, and relevant business metadata. Sparse signals reflecting consumer search behaviors and previous platform demand patterns are also extracted. All these inputs flow into a feature store where they are stored and regularly updated.
This pipeline typically runs on a daily schedule. Feature transformations (e.g., normalizing review scores, encoding cuisine types) must be consistent between training and inference. Production-grade workflows often rely on platforms like Databricks for orchestrating Spark jobs, Snowflake for performing data transformations at scale, and a specialized feature store for storing and retrieving the final processed features.
Feature engineering
Features capture key traits. Consumer intent features reflect how often users in a local region search for specific cuisines. Merchant-specific features capture established reputation (e.g., public reviews, ratings, business hours). Some features are sparse, such as user search queries pointing to certain sub-categories. Tree-based models like XGBoost handle sparse features naturally, making them a good fit.
Labeling merchants
Labels come from on-platform merchants. The main goal is to measure each merchant’s actual performance after they have been on the platform for sufficient time. Many newly activated merchants need a ramp-up phase, so the true measure of their success only becomes accurate once they have stabilized operations. The company chooses a time window after the merchant becomes active (e.g., after store activation plus a certain stabilization period) to compute success metrics. Historical merchant data is then used to define these labels in the training dataset. Special handling is applied if merchants churn and then re-activate.
Model training
Training data is prepared by pairing each merchant’s features with that merchant’s eventual success label. Because the label is typically a continuous variable capturing predicted sales or other demand metrics, the system compares regression models. Decision tree methods such as LightGBM and XGBoost are tested. After hyperparameter tuning, XGBoost is chosen for its strong performance. Separate models are built for certain merchant segments (e.g., local merchants vs. chain stores, new to the platform vs. re-activations) since the relationship between features and labels can differ by segment.
A typical Python training pipeline might look like:
import xgboost as xgb
import pandas as pd
# Example training code snippet
train_data = pd.read_csv("train.csv")
X_train = train_data.drop("label", axis=1)
y_train = train_data["label"]
dtrain = xgb.DMatrix(X_train, label=y_train)
params = {
"objective": "reg:squarederror",
"eta": 0.1,
"max_depth": 6,
"eval_metric": "rmse"
}
model = xgb.train(params, dtrain, num_boost_round=200)
model.save_model("final_xgb_model.json")
The final models are registered in a model store (for instance, using MLflow) to enable version management. Regular training occurs weekly or monthly to capture changing business dynamics.
Daily inference and ranking
Daily inference takes each off-platform merchant’s features from the feature store, runs them through the models, and computes a predicted success value. The system also ranks merchants within each local market. These predictions help the sales organization prioritize the most promising leads. The pipeline is fully automated. If model drift is detected or new data sources are introduced, the models are retrained and re-validated.
Model explainability is crucial. The system leverages Shapley values to highlight how each feature affects an individual merchant’s predicted success. These insights are displayed in interpretability dashboards, letting business stakeholders understand why certain merchants rank highly or poorly.
Weighted decile CPE
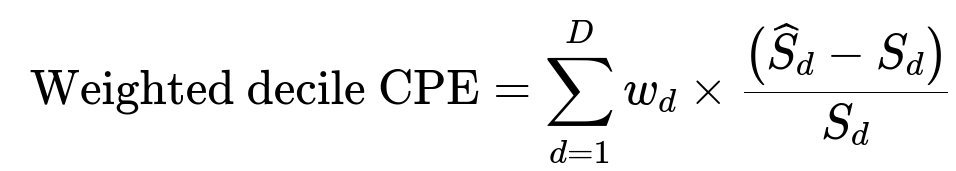
In this formula, d is the decile index, D is the total number of deciles (often 10), w_d is the weight assigned to that decile (based on business priorities), S_d is the actual aggregated sales for merchants in decile d, and (\widehat{S}_d) is the predicted aggregated sales for that same decile. The fraction ((\widehat{S}_d - S_d)/S_d) captures the percentage error. The overall sum is a weighted sum of percentage errors across all deciles.
This metric tracks model accuracy in terms of absolute value predictions. Underestimates or overestimates in high-value deciles matter more, so they can carry a higher weight w_d.
Decile rank score
This metric checks how well the model ranks merchants in each decile. The system compares each merchant’s predicted decile vs. its actual decile. Larger discrepancies incur higher penalties. The business aggregates these penalties into a balance score. If too many merchants are placed far from their true ranking, the decile rank score degrades.
Usage and monitoring
These metrics and the daily rankings feed into dashboards. The operational teams see a breakdown of which merchants the model recommends. Weighted decile CPE indicates how accurate the model is when it comes to forecasting potential sales. The decile rank score measures how well the model orders merchants by their overall value. Shifts in top feature importances or large errors in certain segments trigger alerts for deeper investigations.
Follow-up question: How do you manage the cold-start problem when there are very few merchants in a new region or limited historical data?
Answer
Collecting training data from established markets is one practical approach. The model can be trained on merchants who joined previously in similar regions, possibly using local embedding techniques to adapt from a well-known region to a newer region with fewer historical samples. Including additional signals that do not depend on local orders—such as user search trends and external merchant review data—also helps bootstrap the model. Segment-based modeling can mitigate cold starts by sharing learned patterns from more populous segments while letting sub-models fine-tune to unique local factors. Another tactic is to incorporate a fallback baseline model or heuristic for extreme cases where data is severely limited.
Follow-up question: How would you handle a situation where your most influential features shift drastically over time, causing model performance to drop?
Answer
Regular retraining and robust monitoring is critical. The pipeline should compare current feature distributions against historical training distributions and raise alerts if drift is detected. If a feature like “consumer search frequency” changes meaning due to a new user behavior trend, the data team must audit the transformations. Adjusting feature engineering logic or introducing newly relevant features may be necessary. Segmenting the models more finely can help if certain sets of merchants are impacted differently. Shapley value analyses can highlight which features changed, enabling data scientists to revise features, add new ones (e.g., seasonal signals), or remove stale features that no longer correlate with merchant success.
Follow-up question: How do you incorporate interpretability into a production model for business users?
Answer
Shapley values are a standard way to derive how each feature contributes to an individual prediction. For each merchant, the system produces a decomposition of the predicted success into contributions from geolocation, consumer search signals, public ratings, and so on. These attributions are displayed in the interpretability dashboard. When a user sees an unexpectedly high or low predicted success, they can check the breakdown of feature effects. This helps non-technical stakeholders trust the model and identify possible data anomalies. Storing these attributions in a separate table or visualization layer also lets data scientists track how feature importance evolves over time.
Follow-up question: If you wanted to scale this system to include many new data sources (e.g., real-time consumer feedback or supply chain metrics), how would you refactor the workflow?
Answer
Setting up a more modular feature store is key. Each new data source adds transformations (e.g., daily batch or streaming processes) that produce new features in the store. The model training pipeline remains stable by simply pulling the new features if they pass data quality checks. Additional retraining jobs can incorporate these expanded features. The system also needs automated validation steps that monitor distribution shifts, missingness rates, or delays in data ingestion. If real-time feedback is integrated, the pipeline might adopt micro-batch or continuous data processing. The primary design principle is to decouple feature computation from model training so that new features can flow in with minimal changes to the existing architecture.