
ML Case-study Interview Question: Scaling Sequence Recommendation Model Training with PyTorch Distributed Data Parallel.


Browse all the ML Case-Studies here.
Case-Study question
You are presented with a large-scale personalized recommendation system that uses a sequence-based time series model for scoring items, trained using PyTorch on a single Graphics Processing Unit. The model has grown in complexity, leading to slower training times. The requirement is to reduce training time by distributing the workload across multiple Graphics Processing Units while preserving model performance. The system must still be retrained on a regular cadence to deliver updated predictions. Propose a clear solution that scales training to multiple Graphics Processing Units, ensures minimal maintenance overhead, and maintains or improves model performance. Outline design decisions and detail how you will validate any potential shifts in performance due to changes in batch size or hyperparameters.
Proposed Solution
Overview of the model and pipeline
The model takes a sequence of user-item interactions along with temporal features. It processes these sequences through an encoder that masks future interactions. The pipeline includes feature generation, scoring, and ranking modules. Training occurs regularly, triggered by a Directed Acyclic Graph pipeline. Verification of model quality uses offline backtesting on held-out data. Production deployment hinges on meeting a threshold for model performance.
Choice of distributed training framework
PyTorch Lightning helps to separate business logic from device-specific code. It enforces a standardized structure for forward passes, optimization steps, and checkpointing. This choice simplifies multi-Graphics Processing Unit parallelization. Minimal modifications are needed for the training loop. There can be drawbacks if customization of training flow is required, but for typical use cases, it reduces boilerplate.
Data Parallel vs. Distributed Data Parallel
Data Parallel strategy splits each mini-batch across multiple devices but replicates the model on each forward pass. Distributed Data Parallel initializes a single model copy on each device one time, then averages gradients across devices each iteration. This second approach is recommended because it avoids synchronization bottlenecks caused by Python’s Global Interpreter Lock. Distributed Data Parallel scales better when more Graphics Processing Units are added.
Core gradient update formula for Distributed Data Parallel
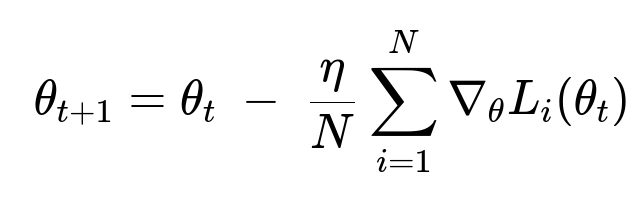
Where:
theta represents the model parameters.
eta is the learning rate.
N is the number of Graphics Processing Units.
L_{i} is the loss function evaluated on the mini-batch assigned to Graphics Processing Unit i.
Implementation details
Code relies on PyTorch Lightning’s Trainer module:
import pytorch_lightning as pl
model = MySequenceModel() # inherits from pl.LightningModule
trainer = pl.Trainer(
max_epochs=NUM_EPOCHS,
accelerator="gpu",
devices=2, # number of GPUs
strategy="ddp" # distributed data parallel
)
trainer.fit(model, train_dataloader, val_dataloader)
Each Graphics Processing Unit runs a mini-batch forward pass. After backpropagation, gradients are averaged. Each device updates its local model copy with these averaged gradients. Communication overhead increases as the number of devices grows, but total training time drops significantly compared to single-device training.
Performance trade-offs
Doubling Graphics Processing Units roughly cuts epoch training time by more than half (observed around 0.55 times single-device training). Communication overhead can become notable when scaling to many devices. Choosing the optimal number of devices involves balancing cost (instance size and number of devices) against speed gains.
Effective batch size effects
Increasing the number of devices effectively raises the batch size if the optimizer updates occur less frequently. For example, moving from one device to two devices can double the per-optimization-step batch size. Careful tuning of the learning rate and other hyperparameters is needed to mitigate potential drops in accuracy.
Validation and deployment
Offline backtesting assesses performance on a held-out dataset. A do-no-harm experiment in production confirms that the distributed model maintains key metrics. Once validated, the distributed training approach is adopted for all future model releases. Regular retraining is triggered by the existing pipeline to keep predictions updated.
Follow-up question 1
How do you debug potential gradient synchronization issues when scaling to multiple Graphics Processing Units?
Explanation and Answer
Watch the distribution of gradients on each Graphics Processing Unit. Log gradient statistics (mean, variance) for every parameter across devices. Compare these statistics to confirm they are synchronized. If discrepancies are found, check for code that might be skipping the DDP broadcast step or inadvertently freezing a subset of parameters. Tools like PyTorch’s DistributedDataParallel debug logging or tensorboard can reveal when certain device gradients diverge. If anomalies persist, test a smaller batch size or fewer devices to isolate whether the issue is data- or hardware-related.
Follow-up question 2
How do you handle the communication overhead while scaling to many Graphics Processing Units?
Explanation and Answer
Reduce overhead by using network-friendly backends like NCCL (NVIDIA Collective Communications Library) if training on NVIDIA devices. Ensure the cluster has high-bandwidth connections (for example, Elastic Fabric Adapter when on cloud). Smaller mini-batch sizes can partially mitigate traffic spikes if memory permits more frequent updates at each step. Overlapping communication with computation is another technique. Some frameworks prefetch gradients on the next mini-batch during the current forward pass, minimizing idle device time. Profiling the training loop is important to see if communication or compute is the bottleneck.
Follow-up question 3
What if model performance drops after increasing the number of Graphics Processing Units?
Explanation and Answer
Investigate changes in effective batch size because the optimizer may update parameters less frequently if multiple mini-batches are averaged per step. Tune the learning rate schedule or lower the batch size per device. Consider using a warmup learning rate strategy or dynamic scaling of momentum parameters. Validate new hyperparameters using standard offline metrics to confirm improvements. Run short experiments to confirm that smaller modifications (e.g. adjusting the initial learning rate) restore performance. If the model continues to underperform, revert to fewer Graphics Processing Units or refine the data preprocessing pipeline.
Follow-up question 4
What are the considerations for scaling beyond a single physical machine?
Explanation and Answer
Distributed Data Parallel can extend across multiple nodes. Confirm that each node has sufficient bandwidth and the same software environment, including library versions. Set up a job manager that orchestrates training launch commands across nodes with a shared initialization method (for example, specifying the right rank, world size, and master address). If network latency is high, gradient synchronization can slow training. Node communication is usually more expensive than device communication on a single node. Evaluate if the added complexity is worth the speed gains. Monitor logs to detect potential cluster failures or partial node restarts.
Follow-up question 5
How would you leverage mixed precision to further accelerate training?
Explanation and Answer
Enable automatic mixed precision, which uses half-precision (float16) operations where possible. This usually benefits matrix multiplications in large layers without degrading accuracy. Most frameworks let you enable this with a single flag. Validate numerics, because some operations lose stability at lower precision. Check for problematic layers or loss functions that become volatile in float16. If that occurs, keep them in float32. Incrementally test performance gains to ensure no major regression in final metrics. Mixed precision typically speeds up compute-limited networks and reduces memory usage, allowing bigger batch sizes.
Follow-up question 6
How do you decide between standard data parallelism and other advanced techniques like model parallelism?
Explanation and Answer
If the network is large enough that it does not fit into the memory of a single Graphics Processing Unit, model parallelism becomes attractive. Layers or sub-blocks of the model are split across different devices. This is more complex to implement. Data parallelism remains simpler when the model fits in device memory but training is slow. Model parallelism demands more architectural changes and careful placement of layers. If you only need to accelerate training time for an already memory-feasible model, data parallel methods such as Distributed Data Parallel are typically sufficient and easier to maintain.