
ML Case-study Interview Question: Leveraging Generative AI to Enhance On-Demand Platform Experiences and Operations.


Browse all the ML Case-Studies here.
Case-Study question
A large on-demand platform that connects customers with restaurants and retailers is exploring ways to embed Generative AI in five major areas: (1) assisting customers in cart building, tracking orders, and finalizing checkouts, (2) enriching discovery and recommendations through chat and voice interactions, (3) generating personalized content such as menus, promotions, and merchandising lists, (4) extracting structured data from unstructured sources including receipts and images, and (5) boosting employee productivity with automated document drafting and SQL generation. Assume user data is anonymized or pseudonymized. How would you design a comprehensive solution strategy, including model selection, data processing workflows, system architecture for real-time and offline interactions, privacy safeguards, bias mitigation, and monitoring methods?
Detailed Solution Approach
Overview of Generative AI
Generative AI uses deep neural networks to produce new content by learning complex patterns from large datasets. Language models often operate on the principle of autoregressive modeling.
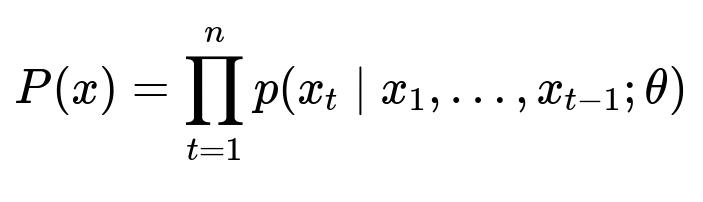
This expression defines the probability of a text sequence x as a product of conditional probabilities. x_{t} is the token at position t, and theta are the learned model parameters. The model predicts each token x_{t} given all prior tokens.
Assisting Customers with Task Completion
Models can generate recommended carts by analyzing the customer's purchase history and dietary preferences. They can also handle voice-based queries. One approach is to fine-tune a large pre-trained model (for example, GPT-like architectures) on anonymized historical orders. Data can be stored in a data lake. The system can have a real-time prediction service that queries the trained model for suggestions and pre-built carts.
Enhancing Discovery and Recommendations
Contextual understanding arises from combining large language model embeddings with user purchase data. The application can match user queries with store catalog data for relevant results. A recommender service can rank these results. The system might store user event data in a warehouse, retrain embeddings daily, and serve them through a vector database.
Personalized Content and Merchandising
Dynamic menus can be generated by mapping popular items, promotions, and seasonal trends to textual or visual templates. Generative image models can create eye-catching graphics. A personalization pipeline can select which promotions to show each user. The final content can be tested with A/B experiments.
Extraction of Structured Information
Optical Character Recognition (OCR) can parse receipts and menus. Generative AI can transform the text into structured formats, such as item, price, and ingredient fields. The pipeline might involve a fine-tuned model on domain-specific data, with a post-processing validator that checks for errors before updating the main database.
Employee Productivity Tools
A fine-tuned language model can speed up internal tasks by generating SQL queries. A user could type questions like “Show me the top-selling items this week,” and the model would return an optimized SQL query. Drafting support for customer support templates can rely on fine-tuned text-generation models. Access control mechanisms are key, ensuring employees cannot query sensitive data.
Practical Example: Text-Generation Setup in Python
A simple approach is to use a popular deep learning framework and a pre-trained model:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
prompt = "Suggest three breakfast items for a family of four"
inputs = tokenizer(prompt, return_tensors="pt")
output_ids = model.generate(inputs["input_ids"], max_length=50)
generated_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(generated_text)
This code shows a minimal pipeline. The prompt is fed to a pre-trained model. The generated text can be post-processed to shape the final recommendations.
Data Privacy and Bias Mitigation
Sensitive user information should be anonymized. Only aggregated purchase histories should be accessible by the models. Differential privacy can help mask unique user data. Bias can appear if certain items or promotions are suggested disproportionately. Retraining with balanced data or applying fairness constraints can mitigate these effects. Regular audits, including checking outputs for problematic patterns, are essential.
Monitoring and Maintenance
A feedback loop can log model outputs, user interactions, and overall system metrics. A separate evaluation system can measure time-to-checkout improvements, user satisfaction, and churn rates. A shadow or canary deployment can test new models in production with a small fraction of traffic, limiting potential negative impact from flawed model suggestions.
Potential Follow-Up Question 1: How do you ensure real-time inference under high traffic?
A dedicated inference service can be built, backed by hardware accelerators such as GPUs or specialized inference chips. Caching recent results and prompt-engineering optimization can reduce tokens processed. Distillation techniques or quantization can shrink model sizes. Horizontal scaling, load balancing, and asynchronous queuing can handle peak volumes. Monitoring latencies is key. If latencies spike, auto-scaling triggers new inference instances.
Potential Follow-Up Question 2: How would you address model hallucinations?
Model hallucinations occur when the system generates incorrect or unrelated content. Retrieval-augmented generation can reduce errors by grounding outputs on authoritative data. The model is restricted to recognized knowledge vectors, or an additional module cross-checks results with factual sources. Confidence scores can gate final output. If a score is below a threshold, the system either asks for clarification or re-checks references.
Potential Follow-Up Question 3: How do you handle edge cases like new merchants with limited data?
Warm-start strategies can use region or category-level patterns for new merchants. Collaborative filtering can group similar merchants to share representations. If user data is sparse, fallback logic might rely on popular global items. Data augmentation can fill training gaps. Once enough orders flow in, standard fine-tuning retrains the model to incorporate these new patterns.
Potential Follow-Up Question 4: What is the best approach for large-scale offline training?
Batches of anonymized user interactions, order histories, and item data can be collected. A cloud-based distributed training environment can use frameworks like PyTorch with Apache Spark. Sharding data helps parallelize training. Checkpoints and versioning keep track of model progress. After training, the final model is validated on a hold-out set. Thorough offline evaluation ensures that newly introduced biases or regressions are caught.
Potential Follow-Up Question 5: How do you measure success and decide on production readiness?
Evaluation metrics can include time-to-checkout, cart conversion rates, A/B test outcomes on user engagement, and manual quality reviews. A substantial positive shift in these metrics signals readiness. For each release cycle, a canary deployment runs side by side with the production model. If operational metrics remain stable or improve, the new model fully rolls out.