
ML Case-study Interview Question: Using textCNN and Bayesian Inference to Rank Important Home Attributes from Guest Text.


Case-Study question
You have a large travel marketplace for short-term rentals, where guests frequently send messages to hosts, leave reviews, and contact customer support regarding their stay experiences. You want to leverage all this unstructured text data to discover which home attributes (amenities, facilities, location features) matter most to guests. Your goal is to build a system that:
Extracts the important attributes from raw text.
Generates a custom ranking of these attributes based on factors such as property type, geographic location, price range, and capacity.
Identifies which attributes actually exist in a home, even if the host has not explicitly disclosed them.
Makes personalized recommendations to each host on what attributes to highlight or acquire to attract more bookings.
How would you design such a system? How would you handle the machine learning models, data ingestion, language coverage, and interpretability challenges?
Detailed Solution
Overview
The system needs to process multiple text sources (messages, reviews, customer support tickets) to figure out guest interests and then map those interests back to each home. This requires named entity extraction, entity mapping to known attributes, and a way to personalize attribute rankings by home features. Finally, the system should confirm whether a home truly has certain attributes before advising the host to highlight them.
Step 1: Named Entity Recognition (NER)
The first component extracts salient phrases from unstructured text. A textCNN (convolutional neural network for text) model can be used to classify each token or phrase into categories like Amenity, Activity, Event, or Point of Interest. textCNN takes the embedded representation of each word and applies convolutions over sliding windows, capturing local context. After this convolution, the model applies pooling, a non-linear activation, and a fully-connected layer to output the named entity class. The process is trained on labeled sentences from diverse sources.
Step 2: Entity Mapping
After extracting phrases, the system matches each phrase to a known home attribute. The entity mapping step uses word embeddings to find semantic similarity between the extracted phrase and possible attribute labels. The phrase is mapped to the attribute whose label has the highest cosine similarity score in the embedding space. If the similarity score is below a threshold, the system flags a new or unknown attribute, potentially updating the attribute dictionary over time.
Step 3: Measuring Attribute Importance
Each attribute’s importance is determined by how often guests mention it. We collect the frequency of references across messages, reviews, and tickets. Attributes that appear more frequently in these sources are deemed more important. Instead of simply counting references within a rigid grouping of homes, the system personalizes the ranking of attributes for each home’s unique features such as location, property type, capacity, and price range.
A specialized inference model handles potential data sparsity when dealing with many unique home segments. It uses the observed mention frequencies from similar homes to estimate how often guests might mention each attribute for a target home with specific characteristics.
Step 4: Checking Attribute Existence
Even if an attribute is important, the host might not have explicitly listed it. To confirm or refute that the home truly has the attribute, the system examines multiple data sources:
Host-provided data (prone to missing entries).
Guest confirmations in reviews or messages.
Trusted third-party databases with location or property details.
One approach is a Bayesian inference model that accumulates evidence from multiple guest confirmations and updates its certainty in whether the home has the attribute. Another approach is a supervised neural model (WiDeText) that takes features about the home to predict the probability of the attribute existing.
Below is an example of a Bayesian-style update formula to represent the probability that a home has a certain attribute, given guest confirmations:
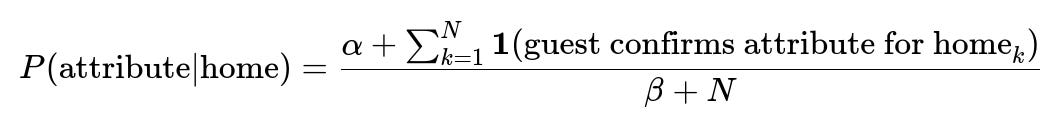
Here:
P(attribute | home) is the probability the home has this attribute.
alpha and beta are hyperparameters reflecting prior beliefs.
The sum_{k=1 to N} is the total number of guest confirmations across N independent pieces of feedback.
The indicator function 1(...) is 1 if the guest confirms the attribute, 0 otherwise.
A larger number of confirmations increases the confidence that the attribute exists.
Step 5: Generating Host Recommendations
Once the system knows which attributes are most important for a home’s typical guests and which attributes are likely missing or unverified, it can produce a personalized list of actions:
Acquire new attributes if they significantly drive guest interest.
Highlight existing attributes if guests frequently mention them.
Clarify ambiguous attributes that often cause questions to customer support.
These insights are fed back to hosts through the host-facing application or dashboard. Hosts can then act on the recommendations to increase booking rates.
Step 6: Future Applications
The same importance scores can power other features, such as ranking search results by the attributes guests want most. If a user searches for mountain cabins, the system can emphasize homes verified to have top-scoring amenities like fire pits and lake views. Over time, it can adapt to new guest needs or new property types by continuously retraining on incoming data.
Possible Follow-Up Questions
1. How would you handle the challenge of class imbalance in NER, where certain attributes appear much less frequently than others?
Many attributes might be rare in text data, causing the model to see fewer training examples for them. One way is to oversample the minority classes or use data augmentation to synthetically expand examples for rarer attributes. Another way is to apply a focal loss in the training objective, which places more emphasis on hard, minority-class examples.
You can also maintain a dynamic threshold per attribute in the entity mapping step if the model might overpredict or underpredict certain classes. Another option is to incorporate external knowledge (like synonyms and context data) to help the model recognize low-frequency attributes.
2. How do you handle multiple languages?
You can train language-specific textCNN models or a single multilingual model if you have enough labeled data in each language. Embeddings can come from a multilingual embedding space such as multilingual BERT or similar large language models. If the system sees new languages with limited resources, you can leverage cross-lingual transfer learning or machine translation to English before applying the pipeline.
3. How would you prevent incorrectly attributing mentions from a single guest message to an entire listing?
The inference model should consider the number of confirmations from multiple independent sources. A single user’s message might be an outlier or misunderstanding. If that attribute is not re-confirmed by other guests, the Bayesian inference probability stays low. This prevents the system from overcounting one-off mentions.
4. How do you ensure quality when new, previously unregistered attributes appear?
Entity mapping can detect unrecognized phrases with low similarity to known attributes. Those phrases go into a review queue. Human annotation or a specialized text-matching pipeline can process them. If repeated phrases keep appearing, the system can add a new attribute label to the known dictionary after an approval step, improving coverage over time.
5. How would you measure success and performance of this system?
Key performance metrics could include:
Accuracy of detected attributes against a labeled validation set.
Precision and recall in NER classification.
Decrease in customer support tickets about missing amenities after implementing host recommendations.
Increased booking rates for hosts who follow the system’s suggestions.
Overall user satisfaction, measured by post-stay surveys or guest review sentiment.
One could run A/B tests to compare how often guests book listings with recommended improvements versus control groups without those recommendations.
6. How would you handle hosts’ privacy and ethical considerations?
Only aggregate or anonymize the textual data. Ensure compliance with data protection regulations by stripping or hashing personally identifiable information. Limit who has access to raw message content. Provide transparency to users on how the data is used and allow opt-outs if required by local regulations.
7. What if the system suggests an attribute that the host cannot actually provide?
Always frame the recommendation as optional. The host can skip or reject any suggestion if their home cannot support it. Over time, the system may learn from host input, adjusting its estimates of which attributes are feasible for certain property types or locations.
8. How would you scale the system to support rapid growth in text data volume?
Use a distributed framework for data ingestion and offline batch processing, such as Apache Spark or a similar system. The textCNN model can be served online through GPU or CPU clusters. The entity mapping step can be cached to speed up repeated lookups. Monitoring resource usage and automatically provisioning additional servers or GPU instances helps maintain latency targets as data grows.
9. How do you handle data that comes in real time, for example new messages from guests?
Maintain a streaming pipeline that processes incoming text data in near real-time, updating attribute extraction and mention frequencies. This pipeline can feed into a data store that quickly calculates incremental updates to the ranking model. The system then recalculates personalized home attributes on a frequent schedule (or triggers when thresholds are exceeded) to keep recommendations fresh.
10. Could you share a quick example of how the textCNN inference step might look in Python?
Below is a sketch of a textCNN inference process. It assumes you have already trained the model and now you just pass an input text snippet for entity classification:
import torch
import torch.nn as nn
import numpy as np
class TextCNN(nn.Module):
def __init__(self, vocab_size, embed_dim, num_classes):
super(TextCNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.convs = nn.ModuleList([
nn.Conv2d(1, 100, (k, embed_dim)) for k in [3,4,5]
])
self.dropout = nn.Dropout(0.5)
self.fc = nn.Linear(300, num_classes)
def forward(self, x):
x = self.embedding(x).unsqueeze(1)
conv_results = []
for conv in self.convs:
c = torch.relu(conv(x)).squeeze(3)
pooled = nn.functional.max_pool1d(c, c.size(2)).squeeze(2)
conv_results.append(pooled)
cat = torch.cat(conv_results, 1)
out = self.dropout(cat)
out = self.fc(out)
return out
# Suppose we have a pre-trained model loaded, a tokenizer, and a label dictionary.
# Tokenize the text, convert tokens to indices, then run inference:
def predict_attribute_class(model, tokenizer, text):
tokens = tokenizer(text)
token_ids = torch.tensor([tokens]) # shape (1, sequence_length)
model.eval()
with torch.no_grad():
logits = model(token_ids)
predicted_class_id = torch.argmax(logits, dim=1).item()
return predicted_class_id
The predict_attribute_class function tokenizes a text input, runs it through the textCNN, and returns the predicted class for the attribute. This is just a skeleton, but it illustrates how the model transforms text into entity category predictions.
This end-to-end explanation covers how unstructured text flows through entity extraction, attribute mapping, Bayesian inference, and final recommendation. When done correctly, the marketplace benefits by surfacing the attributes that truly matter to travelers, and hosts gain a clear roadmap on how to enhance or showcase their homes for maximum guest satisfaction.