
ML Case-study Interview Question: Designing a Scalable Deep Learning Recommendation System for Large Consumer Platforms


Browse all the ML Case-Studies here.
Case-Study question
A large consumer platform processes millions of daily user interactions. They introduced a deep learning recommendation system to increase user satisfaction and revenue. They gathered massive behavioral signals, built feature engineering pipelines, and deployed a high-volume serving layer that personalized product rankings in real time. How would you design the entire solution, including data ingestion, feature extraction, model training, and deployment, to handle scale and deliver measurable improvements?
Proposed Detailed Solution
Start with data ingestion by collecting user behavior logs, product metadata, and contextual data. Store them in a distributed file system to accommodate large volumes. Transform the raw data into structured formats for model consumption. Use data partitioning to reduce I/O and speed up queries. Apply event timestamps for time-based analysis. Aggregate metrics like view count, clickthrough frequency, and purchase frequency.
Proceed with feature engineering by combining user profiles, product attributes, and contextual signals. Derive embeddings for product and user features. Convert categorical variables into embedding vectors or one-hot encodings. Encode continuous features into normalized scales. Track user session sequences in chronological order to reflect real browsing paths. Generate advanced features, such as interaction-based similarity scores or product co-view frequency.
Design a model architecture that includes an embedding layer for user and product entities. Feed session-based features into a recurrent or attention-based layer. Concatenate user embeddings, product embeddings, and contextual signals into a dense representation. Pass that representation through a feedforward network for prediction. Use cross-entropy loss to maximize the probability of correct recommendations. Center the key formula for clarity:
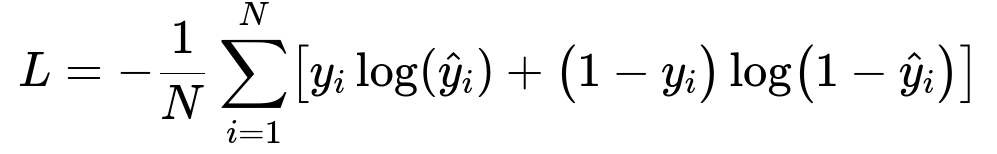
Here, y_{i} is the ground-truth label for item relevance. hat{y}_{i} is the predicted probability that item i is relevant. N is the total number of training samples. This loss function penalizes wrong predictions and encourages correct classification probabilities.
Train this model on a distributed cluster. Shuffle data to avoid biased batch sampling. Use mini-batch stochastic gradient descent or an adaptive optimizer. Validate frequently on holdout sets to detect overfitting. Measure classification metrics like AUC and log loss for performance. Once training completes, export the model for serving.
Deploy at scale by hosting the model on a high-performance inference service. Cache frequently accessed user embeddings to reduce latency. Keep an offline refresh pipeline for embeddings to capture evolving user behavior. Integrate an online module that updates model inputs with fresh interaction data. Monitor real-time latency and throughput. Apply post-processing for diversity or novelty if necessary.
Evaluate improvements by running online experiments. Split traffic between baseline and new model. Compare user engagement, purchase rates, or session duration. Analyze distribution shifts and track anomalies. Introduce cyclical retraining to adapt to changing trends.
Example Code Snippet
import pyspark.sql.functions as F
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("RecommendationDataPipeline") \
.getOrCreate()
data = spark.read.parquet("s3://path/to/raw_data")
data = data.filter(F.col("event_type") == "view")
# Simple transformation
data = data.withColumn("view_count", F.lit(1))
# Aggregation
user_views = data.groupBy("user_id", "product_id") \
.agg(F.sum("view_count").alias("total_views"))
user_views.write.mode("overwrite").parquet("s3://path/to/feature_data")
Use a similar approach to prepare all essential features. Feed them into a model training script that constructs the network and uses the loss function shown above.
What if the dataset has severe imbalance?
Balance your training data by under-sampling frequent classes or applying re-weighting. Use cost-sensitive learning to amplify the loss for underrepresented labels. Calibrate the model outputs with threshold tuning or a separate calibration layer.
How would you handle cold-start issues?
Create a separate pipeline for new users or items. Generate context-based or content-based profiles until enough interactions exist. For items, rely on metadata embeddings such as categories or textual descriptions. For users, infer preferences from demographic or contextual signals. Gradually integrate them into the main collaborative filtering pipeline once you collect more interactions.
How would you ensure near real-time updates?
Deploy a streaming system that captures new user interactions. Refresh embeddings on a fixed interval or whenever significant behavioral changes occur. Keep a high-throughput queue that publishes incremental updates. Perform partial retraining if necessary, or maintain a lightweight online learning module that updates parameters for new patterns.
Why use distributed training?
Massive data demands parallel processing. Distribute the training workload across multiple nodes with synchronized gradient updates. Leverage data parallelism by partitioning the dataset. Exchange gradients or model parameters over a high-speed network. Verify convergence speed and memory usage in your cluster setup.
What if performance stalls?
Investigate learning rate schedules. Verify data quality. Examine feature drift where certain features lose relevance over time. Check for label leakage if some columns reveal the target. Tune hyperparameters or architecture depth. Adjust the batch size for better gradient estimates. Evaluate more robust optimizers like Adam or RMSProp.