
ML Case-study Interview Question: Optimizing Personalized Coupons Beyond Prediction Using Causal Inference


Browse all the ML Case-Studies here.
Case-Study question
A fast-growing financial services startup wants to optimize its marketing coupon strategy to attract new users who are most likely to generate long-term value. The team has a large incoming customer flow, plus enough historical data of coupon allocations and resulting conversion rates. There is a desire to personalize coupon amounts to different customer profiles while controlling costs. How would you design a data-driven solution that combines traditional predictive models with causal inference to decide who should receive specific coupons and how many, so that the net gain in user acquisition and retention is maximized?
Outline every step, from data gathering and feature creation to experimentation and final deployment, and ensure to address how you would estimate not just the probability of conversion but the incremental effect of each coupon level. Also specify your methodology for validating the performance of your approach in production.
Detailed Solution
The goal is to determine how different coupon offers affect a person's likelihood of converting and remaining active. Traditional classification models only predict overall conversion probability. The real requirement is to measure incremental responses to specific treatments (coupon levels). This shifts the approach toward causal inference.
Traditional Predictive Modeling vs Causal Inference
Many marketing teams initially treat coupon allocation as a simple predictive modeling task. They train a model that classifies users as "likely to convert" or "unlikely to convert." That alone does not answer who actually needs more coupons or who would have converted anyway. Causal inference focuses on treatment effects, or how an intervention changes the outcome. For coupon decisions, the treatment is the coupon amount, and the outcome is user retention or spend.
Key Causal Formula
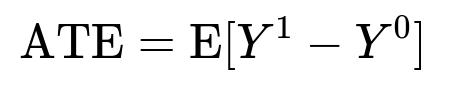
ATE stands for Average Treatment Effect, which measures the expected difference in the outcome (Y) if a user is treated (1) versus not treated (0). Here, "treated" means receiving a given coupon amount. This helps decide which coupon magnitude truly moves the needle for each user.
Dataset Preparation
All user records include demographics, behaviors, and past interactions. For each user, there is a record of whether they received coupon A, B, or C (or no coupon), plus the outcome of interest (conversion or not, plus subsequent behavior). Confounding arises when certain user types are more or less likely to receive certain offers. Controlling for confounding is crucial. Techniques like propensity score matching or inverse propensity weighting help reduce bias in observational datasets.
Experimentation Strategy
A robust Randomized Controlled Trial (RCT) is ideal. For a sample of new users, randomly assign coupon groups. That ensures each group is similar on average, allowing direct measurement of how different coupon offers affect behaviors. If an RCT is not possible, well-structured quasi-experimental methods (e.g., difference-in-differences or instrumental variables) might be used, but RCT remains the gold standard.
Model Building
One approach is uplift modeling, where the target variable is the incremental benefit of offering a coupon (or a specific coupon level) compared to not offering it. Another approach is training separate outcome models for each coupon group and comparing them to find the difference in predicted outcome. More advanced methods like meta-learners can also be used.
In a meta-learner setup, the first step is to fit models that estimate the outcome given each treatment. The second step is to estimate the difference in predicted outcomes across treatments. That difference is the Individual Treatment Effect (ITE). The best coupon for each individual is the treatment with the highest predicted effect.
Implementation Example (Python)
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
# Suppose df has columns:
# 'features...' for user profile data
# 'coupon_type' for the actual treatment received
# 'converted' for the outcome
# Step 1: Create dummy variables for coupon_type
df = pd.get_dummies(df, columns=['coupon_type'], prefix='treat')
# Step 2: Fit outcome models for each coupon group
model_A = RandomForestClassifier()
model_A.fit(df[df['treat_A']==1][['feature1','feature2']],
df[df['treat_A']==1]['converted'])
model_B = RandomForestClassifier()
model_B.fit(df[df['treat_B']==1][['feature1','feature2']],
df[df['treat_B']==1]['converted'])
# Step 3: Predict outcomes for each user under each coupon
df['pred_outcome_A'] = model_A.predict_proba(df[['feature1','feature2']])[:,1]
df['pred_outcome_B'] = model_B.predict_proba(df[['feature1','feature2']])[:,1]
# Step 4: Estimate incremental effect
df['effect_of_A_over_B'] = df['pred_outcome_A'] - df['pred_outcome_B']
# Step 5: Decide who gets which coupon
df['optimal_coupon'] = np.where(df['effect_of_A_over_B'] > 0, 'A', 'B')
This toy example shows how one might compare two treatment effects. With more coupon levels, you would fit multiple models or use a multi-class approach.
Validating the Model
After training, evaluate using a validation strategy that separates data into training and test segments or uses cross-validation. For a rigorous check, run an offline simulation or a new RCT to verify that the recommended coupon strategy yields better net outcomes than a uniform approach.
Deployment
Operationalize the model in a pipeline that scores incoming users. For each user, produce an ITE for each coupon. Assign the coupon with the highest predicted effect on future value. Monitor real-world performance, and if the environment changes, retrain with fresh data.
Potential Data Leakage
Ensure that features capturing post-treatment user actions are excluded because they break the causal assumption. The system only sees relevant pre-treatment features. If any variable is recorded after the coupon, it introduces bias.
Handling Costs and Risk
Coupon redemption cost must be weighed against incremental gains. High-value coupons are more expensive. The best approach might limit coupon magnitude for users whose predicted incremental gain is marginal. This risk-return tradeoff is crucial for the final recommendation engine.
What If The Interviewer Asks These Follow-Up Questions?
How would you handle multiple treatment levels beyond just coupon vs no coupon?
Categorize each coupon tier as a separate treatment. For example, treat_0 for no coupon, treat_1 for a moderate coupon, and treat_2 for a large coupon. Fit separate models or use a single model with one-hot encoding for each treatment. Estimate the outcome for each treatment. Subtract one treatment’s predicted outcome from another’s to get the incremental effect. For real-time decisions, pick the treatment that yields the highest net improvement.
In practice, that means more complex modeling or an uplift model that directly outputs a matrix of predicted outcomes for each treatment. Evaluate these predictions for each user and choose the best action. The challenge is ensuring enough data in each treatment group so that the model learns valid relationships.
Could you adapt this approach for continuous treatments like dynamic pricing?
Yes. Instead of discrete coupon levels, the treatment can be a real-valued price or discount. A typical approach is to parameterize the effect as a function of the treatment variable. For example, use regression-based methods to approximate how changes in price shift demand. Nonlinear regressors can capture diminishing returns. Make sure to collect data at varying price points. Then, for a new user, predict the outcome curve across the price range. Pick the price that maximizes net benefit.
How do you ensure internal stakeholders trust a causal model’s recommendations?
Explain that a causal model explicitly estimates how user behavior changes with each coupon option, unlike a purely predictive classifier. Show them the difference between "likelihood to convert" and "incremental conversion if we apply a coupon." Demonstrate the model’s performance with a pilot test or A/B test. Publish results that confirm the causal model outperforms naive targeting. Build interpretability into the pipeline. Provide dashboards that reveal how predicted incremental effects vary by user segment.
How would you handle cold-start users who have no historical features?
Use domain knowledge or aggregator features like broad demographic data. Alternatively, randomize coupon assignments at the start, gather initial responses, and rapidly adapt the causal model. Online learning techniques or bandit algorithms can help. Over time, incorporate new data as it arrives to refine your incremental effect predictions.
What if you suspect unobserved confounders are biasing your estimates?
Unobserved confounders are variables that affect both coupon assignment and outcome but are not in your dataset. This biases the treatment effect estimation. Strategies include instrument variables, difference-in-differences (if you have a suitable time-based control group), or designing a better RCT to isolate the effect. If randomization is impossible, attempt robust sensitivity analyses to bound the possible bias from missing covariates.
How do you integrate domain constraints like user equity or fairness?
Adjust the optimization to include fairness terms or constraints. For example, ensure no user demographic is systematically deprived of beneficial coupons if your policy requires inclusive allocation. This can be done by adding penalty terms or constraints in your optimization objective that ensure some fairness measure is respected. Confirm no group is penalized in a way that violates company policy or legal guidelines.
Could you automate the entire pipeline with minimal human intervention?
Yes, as long as you trust the dataset’s integrity and can rely on a continuous flow of valid training data. The pipeline would retrain periodically or follow an online learning strategy. Real-time data ingestion, feature engineering, treatment assignment, and outcome measurement must be stable and consistent. Proper monitoring is mandatory to detect data shifts or concept drift.
How do you measure long-term user value in real-time?
Use proxy metrics for immediate signals that correlate with long-term outcomes. Example: short-term retention or a usage metric that highly correlates with eventual revenue or net present value. Calibrate these proxies periodically with actual long-term data. If the correlation changes, adjust the strategy. Alternatively, use survival analysis techniques or discount future revenues to get net present value estimates.
What if your model must scale to tens of millions of users every day?
Use distributed systems. Pre-compute features in a robust pipeline (e.g., Spark jobs or streaming frameworks). Deploy your causal model behind a low-latency service that quickly returns the recommended coupon for each user request. Cache repeated user data or embed approximate nearest neighbor searches for fast predictions. Continuously monitor throughput, latency, and failures.