
ML Case-study Interview Question: Scalable Text Classification Using Semantic Embeddings and Faiss Similarity Search


Browse all the ML Case-Studies here.
Case-Study question
A large organization collects vast amounts of text data daily, covering multiple topics or categories. They have an existing text classification pipeline that retrains a model whenever new categories appear. This causes significant delays and high computational costs, especially under imbalanced class distributions. They want a scalable approach that handles new categories without frequent retraining, while maintaining reliable performance and fast search. How would you design a system that solves these requirements using semantic embeddings and similarity-based classification, and what steps would you take to ensure the solution remains robust and flexible over time?
Detailed Solution
Overview
A simple way to handle classification with minimal retraining is to adopt a semantic search approach. Transform text into embeddings, store them in an index, and retrieve the nearest neighbors for classification. The idea relies on converting raw text into numerical vectors with a model like MiniLM. Then a similarity search library such as Faiss is used for fast lookups.
Steps
Data Preparation Clean and pre-process text by normalizing case, removing unwanted characters or punctuation, and eliminating stop words.
Embedding Generation Use a sentence transformer (for example, all-MiniLM-L6-V2) to convert text to vector embeddings. Each text sample is mapped to a numerical representation that preserves semantic meaning.
Index Construction Select a Faiss index type. Common choices include:
Flat Index (IndexFlatL2 or IndexFlatIP) for accurate but slower exhaustive search.
Partitioned Index (IVFFlat) for faster searches with slightly reduced accuracy.
Product Quantization (IVFPQ) for large-scale compression and high speed.
Query Embedding and Search At inference time, transform the query text into an embedding, then search in the Faiss index. Retrieve top matches with their similarity scores.
Final Classification Fetch the categories of the top matches. Pick the category with the highest frequency or apply a weighting scheme for final classification. This avoids fully retraining a model when new categories appear. Just generate embeddings for the new data, insert them into the index, and classify queries against the updated index.
Core Distance Formula
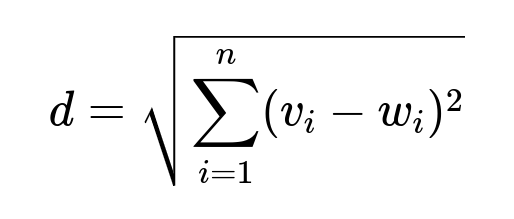
Parameters: v and w are the two embeddings being compared; v_i and w_i are their respective components. The goal is to find neighbors with minimal distance or maximum inner product.
Example Code Explanation
Below is a simplified snippet in Python. The embeddings are generated with a SentenceTransformer, then added to an inner product Faiss index. Queries are converted to vectors, normalized, and searched:
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
train_embeddings = model.encode(train_data)
index = faiss.IndexIDMap(faiss.IndexFlatIP(train_embeddings.shape[1]))
faiss.normalize_L2(train_embeddings)
index.add_with_ids(train_embeddings, np.array(list(doc_ids)))
When predicting:
def predict(query, index):
query_vector = model.encode(query)
query_vector = np.asarray([query_vector], dtype="float32")
faiss.normalize_L2(query_vector)
distances, ids = index.search(query_vector, k=10)
# Map retrieved ids to categories, pick the most frequent
...
return final_class
This approach is resilient, as the index can be rebuilt or updated without retraining a giant classification model.
Follow-up Questions
1) How do you handle data imbalance when constructing the embeddings and building the index?
Resampling or class weighting is not always critical here. The nearest neighbor method addresses imbalance by focusing on the distances between embeddings. However, if one category is severely underrepresented, gather enough representative samples or use domain knowledge to ensure embeddings capture all classes well. Ensure embeddings generalize with a model trained on broad data, then rely on Faiss to find neighbors accurately.
2) Why choose Flat L2 over Partitioned Index when accuracy is crucial?
Flat L2 exhaustively searches all embeddings, yielding the most accurate results. Partitioned indexes skip many distances for speed, risking missing some optimal neighbors. If accuracy is paramount, exhaustively compare embeddings. For very large data, consider partition-based or product-quantization indexes, but test if the slight loss in accuracy is acceptable.
3) How would you integrate new categories without retraining?
Generate embeddings for the new category’s data. Append these vectors to the existing pool, then rebuild or update the Faiss index. New queries can then find neighbors among the new category vectors. No full retraining is necessary, only embedding computation and index update.
4) What if the number of embeddings grows into the billions?
Use advanced indexes like IVF with product quantization (IVFPQ). This scales well in memory usage and keeps search latency low. Consider a multi-node or GPU-based Faiss setup. Partition the data across multiple machines or use a vector database that handles sharding for large-scale deployments.
5) How do you validate correctness when applying similarity-based classification?
Split a labeled dataset into train and test sets. Build the index with the train set. For each test sample, compute its embedding, retrieve top matches, and finalize a predicted category. Compare predictions with true labels. Compute metrics like precision, recall, and F1. Adjust thresholds or the number of neighbors if needed.
6) Is there a risk of misclassification with new data that has overlapping semantics?
Yes. Closely related categories can have overlapping embedding distributions. Mitigate by improving embedding quality, refining text cleaning, or applying domain-specific word embeddings. Consider re-checking the top few neighbors to ensure they represent the correct category context.
7) What hardware considerations do you have?
Faiss can leverage both CPUs and GPUs. For large-scale data, GPU indexes speed up searches. CPU-based solutions suffice for moderate data and are easier to deploy. Monitor memory usage when building large indexes and consider adding more memory or distributed architecture.
8) How do you detect if your semantic approach is drifting over time?
Monitor classification accuracy on a rolling sample of the newest data. If performance degrades, refresh embeddings with a more up-to-date model, re-index fresh data, and verify that top neighbors represent new semantic nuances. Adjust the embedding model periodically if domain language evolves.