
ML Case-study Interview Question: Robust Skill Extraction and Mapping via Two-Tower Models and Knowledge Distillation


Browse all the ML Case-Studies here.
Case-Study question
You are working at a large professional networking platform aiming to build a robust skill extraction system that analyzes text from resumes, job postings, and online course descriptions. The goal is to capture relevant skills from any text input, map them to a unified skill taxonomy, and use these skills to power recommendations, job matching, and learning course suggestions. How would you design and implement this system from data ingestion through production deployment, ensuring high accuracy, efficient serving, and continuous improvement?
Detailed Solution
Skill extraction requires parsing raw text to detect and map skills to a curated taxonomy. This process involves several subproblems: text segmentation, entity normalization, context-based filtering, model architectures, and feedback-driven refinement.
Parsing and segmentation
Segment text into sections (experience, skills, qualifications) to catch context-specific cues. A skill mentioned in a "Requirements" block is more crucial than one in a "Company Description."
Token-based skill tagging
Use a trie-based tagger to detect explicit mentions of known skills at scale. This tagger quickly flags string matches from the taxonomy but may miss synonyms or paraphrases.
Semantic skill tagging
Train a two-tower model that encodes text content in one tower and known skill names in another tower. Compare the embeddings via a similarity function to capture more subtle mentions.
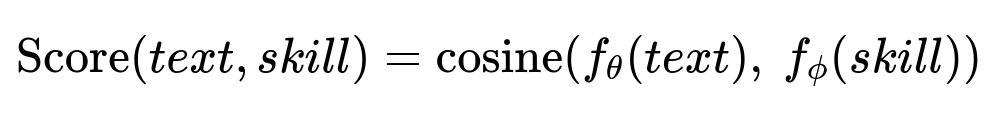
Here, f_{\theta}(text) is the embedding function for the text. f_{\phi}(skill) is the embedding function for the skill. The similarity measure is cosine(...) on the two embeddings.
Skill expansion
Leverage the skill taxonomy to expand candidate skills by grouping, parent-child relationships, or known synonyms. This boosts coverage for relevant skills not explicitly listed.
Multitask cross-domain scoring
Assign each skill a relevance score for a given text snippet. A shared Transformer-based encoder extracts contextual features. Then domain-specific towers (resume, job posting, course content) refine the shared encoding to address subtle domain differences.
Knowledge distillation for efficient deployment
Large Transformer-based models can be slow for real-time serving. Compress them using knowledge distillation, where a smaller student model mimics the outputs of the larger teacher model.
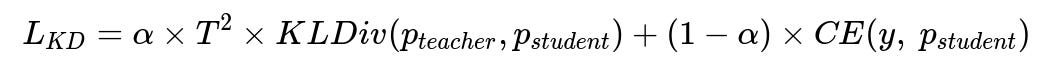
p_{teacher} is the probability distribution from the larger model. p_{student} is from the smaller model. T is the temperature parameter. KLDiv(...) is the Kullback-Leibler divergence. CE(...) is the cross-entropy loss. This training strategy preserves accuracy while reducing model size.
Production serving
Use nearline or offline pipelines to handle large-scale reprocessing. Serve the smaller student model in real time to meet latency constraints. Listen to user actions (e.g., recruiters editing skill suggestions) for fast feedback loops.
Python code snippet for nearline inference
def process_profile_text(profile_text, model, skill_taxonomy):
# Segment text into relevant sections
sections = segment_text(profile_text)
# Token-based tagging
token_tags = trie_tag_skills(sections, skill_taxonomy)
# Semantic-based tagging
semantic_tags = semantic_skill_match(sections, model)
# Combine and expand
candidate_skills = expand_with_taxonomy(token_tags, semantic_tags, skill_taxonomy)
# Score and filter
scored_skills = domain_specific_scoring(candidate_skills, sections)
return scored_skills
This approach splits the text, applies multiple detection methods, merges skill candidates, and filters them through a domain-oriented scoring model.
Feedback-driven improvement
Collect recruiter edits of job skill lists and member feedback on skill matches. Track skill verifications (like skill quizzes) as strong signals. Retrain and refine the skill extraction models based on these real-world corrections.
Follow-up Question 1
How do you ensure that newly emerging skills, which might not appear in the taxonomy, are captured and recognized?
Answer
Monitor text for out-of-vocabulary terms. Use semantic similarity from the two-tower model on skill names and keep track of high-similarity mentions lacking a mapped skill. Flag these as potential new skills. Human-in-the-loop labeling or active learning workflows confirm if they belong in the taxonomy. Then fold them back in for future tagging.
Follow-up Question 2
How do you handle ambiguous skill names that can represent multiple concepts?
Answer
Examine the surrounding context. If a term can mean different things, the domain-specific tower checks the job title, section type, or co-occurrence of related keywords. Additionally, gather user feedback signals, such as job seekers marking certain skill matches as irrelevant. This helps disambiguate meaning over time.
Follow-up Question 3
What if some resumes or job postings are in languages you have not fully supported?
Answer
Train or fine-tune multilingual models that can encode text in many languages. Extend the two-tower approach with multilingual embeddings. Confirm coverage by measuring performance on region-specific test sets. Use cross-lingual knowledge distillation to compress the multilingual model for serving.
Follow-up Question 4
How would you measure the quality of your skill extraction system?
Answer
Use precision, recall, and F1 scores. Compile a labeled set of documents and their expected skills. Measure how many skills the system catches (recall), how many returned skills are correct (precision), and combine them in an F1 score. Track usage metrics in production: how often recruiters accept or reject suggested skills, how often job seekers confirm skill matches, and any direct impact on job applications or job matching outcomes.
Follow-up Question 5
What strategies do you apply if you observe declining performance in production?
Answer
Monitor feedback signals to detect drifting distributions or new skill trends. Schedule regular retraining using fresh data or incremental fine-tuning of the model. Investigate mislabeled or incorrectly extracted samples. If needed, adjust model architecture (e.g., add domain-specific heads). Use live A/B tests or hold-out sets to validate improvements before full deployment.
Follow-up Question 6
How do you avoid sending too many irrelevant skill suggestions to the user?
Answer
Rank skill candidates by relevance. Factor in context signals such as job title, role, or text section. Apply threshold-based filtering so low-scoring or tangential skills are dropped. Use historical acceptance rates: if a skill rarely gets confirmed in certain contexts, lower its priority or remove it from auto-suggestions.