
ML Case-study Interview Question: Product Title Matching: Efficiently Combining Lexical and Semantic Search with Retrieval-Rerank


Browse all the ML Case-Studies here.
Case-Study question
A global e-commerce retailer needs to identify whether a given product title matches any product in a large inventory list. The retailer wants to find near-duplicate products, products with different variations like “500ml” or “0.5L,” and items with misspellings or synonyms. The data is limited to product titles. How would you architect an end-to-end solution that can efficiently handle lexical overlap, capture deeper semantic meaning, and balance speed with accuracy? Propose a method, outline the possible challenges, and discuss optimization strategies.
Detailed Solution Approach
A lexical matching approach starts by breaking each product title into words. It calculates how many words overlap between two titles and normalizes by the union of their words. The Intersection over Union (IoU) formula often appears as the core similarity metric:
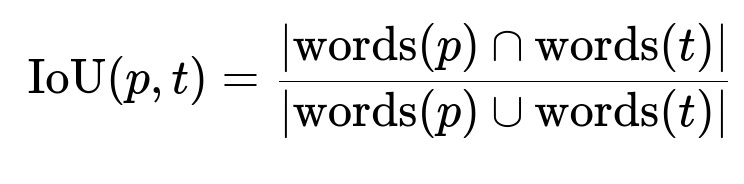
p is the candidate product title. t is a title in the inventory. words(p) and words(t) are the sets of words extracted from p and t. The numerator is the count of common words. The denominator is the total count of unique words across p and t.
This method can scale quickly using an inverted index. Tools like Lucene help with indexing. However, exact word matching cannot handle synonyms or brand variations. For instance, “Coca-Cola 250ml” vs “CocaCola 250ml” have partial overlap. Lexical matching may miss them if the brand is spelled differently.
A semantic approach uses a Sentence-BERT (SBERT) encoder to transform each title into an embedding vector. The encoder captures word order and context better than lexical methods. Two semantically similar titles produce close embeddings in vector space. The model is usually trained on matched vs not-matched pairs of product titles. Euclidean distance or cosine similarity between embeddings helps measure how similar two titles are. This works well even if the words differ, such as “USB charger” vs “USB adapter.”
A pure semantic approach can miss certain important words. If the embedding has limited dimensionality, it might overlook brand names or numeric size differences. Also, encoding each query against a large inventory can be computationally expensive.
A Retrieval-Rerank pipeline balances cost and accuracy in two stages. First stage quickly retrieves k likely candidates. The second stage reranks these k candidates using a more accurate and heavier model:
Retrieval: A lexical index retrieves the top k matches based on word overlap or BM25. This step is fast.
Reranking: A cross-encoder (transformer) processes each candidate pair (query and candidate) together to consider word interplay more deeply. This step is slower but only happens on the reduced set of candidates.
During training, hard negative sampling selects negative pairs that the model confuses as positives. The system collects pairs whose embeddings are too similar even though the labels say they are not matches. Fine-tuning the cross-encoder with these “hard” examples pushes the model to differentiate nuanced differences in product titles.
Below is a rough Python snippet illustrating a Retrieval-Rerank flow. The first part uses a simple lexical retrieval, and the second part runs a cross-encoder for the final match decision:
import numpy as np
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from some_lexical_tool import LexicalMatcher
# Stage 1: Retrieval
inventory_titles = ["Pepsi 1L", "CocaCola 250ml", "Marigold HL Chocolate Milk 200ml", ...]
lexical_matcher = LexicalMatcher(inventory_titles)
query_title = "Pepsi 1000ml"
candidate_titles = lexical_matcher.retrieve_top_k(query_title, k=5)
# Stage 2: Reranking
tokenizer = AutoTokenizer.from_pretrained("cross-encoder-model")
model = AutoModelForSequenceClassification.from_pretrained("cross-encoder-model")
scores = []
for candidate in candidate_titles:
inputs = tokenizer(query_title, candidate, return_tensors="pt", truncation=True)
outputs = model(**inputs)
# assume model returns higher score for better match
scores.append((candidate, outputs.logits.item()))
# sort by best score
scores.sort(key=lambda x: x[1], reverse=True)
best_match = scores[0][0]
print("Best match:", best_match, "with a confidence score of:", scores[0][1])
This pipeline retrieves promising candidates with minimal compute cost. Then it analyzes those candidates more thoroughly with a cross-encoder that looks at both titles side by side to decide if they match.
Underlying Reasoning
A lexical approach is fast but limited to surface word overlap. A purely semantic encoder can handle synonyms or paraphrases but might overlook rare or important keywords. A retrieval-rerank system combines both. The first filter with lexical methods narrows the search pool. The second pass with a cross-encoder sees how each word in the query interacts with each word in the candidate. This two-step system is more efficient than running a cross-encoder on the entire inventory.
Hard negative samples help the model learn. Similar-looking product titles labeled as not matches push the network to discriminate subtle differences. This prevents the model from relying on partial brand matches when the rest of the title differs significantly.
Implementation Details
Large-scale deployment typically demands distributed computing or specialized indexing systems. The retrieval stage often runs on a search engine that indexes product catalogs. The cross-encoder typically uses a transformer architecture like BERT or RoBERTa. Fine-tuning uses pairs of titles: label 1 if matched, 0 if not matched. Hard negatives are cases where the encoder incorrectly assigns high similarity to non-matching pairs. Those pairs are essential for training the cross-encoder to refine how it weighs certain brand or numeric tokens.
Follow-up Question 1
How would you handle the risk that the encoder-based approach might miss crucial brand keywords when generating embeddings?
Answer
The encoder might compress all information into a fixed-size embedding and lose brand tokens if the brand name is unique or rarely seen. Fine-tuning on domain-specific data with explicit emphasis on brand presence is critical. Hard negative sampling should include examples differing only by brand. Data augmentation techniques, like substituting brand tokens, help the model learn brand importance. Another approach is to add brand or numeric tokens as separate special tokens or keep them as separate features for a final classifier layer.
Follow-up Question 2
Why not just use the cross-encoder for every comparison instead of doing a two-stage Retrieval-Rerank?
Answer
Running a cross-encoder on every single title in a large inventory is computationally prohibitive. Cross-encoders have a higher runtime because each query-candidate pair is processed together. For N product titles in the inventory, that would require N forward passes. The lexical approach filters the inventory to k promising candidates. The cross-encoder then only compares the query to those k titles. This saves time and resources and is essential for large-scale deployments.
Follow-up Question 3
Explain a situation where lexical matching might actually outperform the semantic approach.
Answer
Lexical matching can outperform the semantic approach if a brand name is spelled consistently in both query and candidate, and synonyms or paraphrases are not a concern. When exact brand names and model numbers must match exactly, lexical methods excel. If the semantic encoder fails to pay proper attention to brand tokens, lexical matching can give fewer false positives.
Follow-up Question 4
How do you evaluate the performance of this product-matching system?
Answer
Precision and recall are the main metrics. We want high precision to avoid matching dissimilar products. We want high recall to catch genuine duplicates. F1 score is the harmonic mean of precision and recall and balances both metrics. In e-commerce, an additional metric is top-k accuracy: the correct match should appear in the top k results. Offline evaluation uses a labeled set of query-product pairs. We compare the system’s predictions to ground truth matches. For retrieval-rerank, we measure how well the retrieval stage recalls correct candidates. Then we see if the reranking places the true match at the top.
Follow-up Question 5
Is it possible to integrate other product attributes like price or size into your system?
Answer
Yes. Concatenate or encode these attributes along with the title text. A semantic model can treat numeric or categorical attributes as text tokens or as separate features. Combining them during training helps the encoder learn that products identical in name but with distinct sizes are not duplicates. Price differences also help the cross-encoder see that a cheaper item could be a smaller size, which might indicate a mismatch.
Follow-up Question 6
Describe how you might extend the same approach to matching product images instead of text titles.
Answer
Use an image encoder, such as a convolutional neural network or vision transformer, to transform each product image into an embedding. Similar images produce closer vectors. For retrieval-rerank, the retrieval step might employ a lightweight image hash or color histogram approach to narrow the search pool. The rerank step applies a more advanced vision transformer cross-encoder that takes the query and candidate images together. Hard negative sampling involves visually similar images labeled as mismatches.
Follow-up Question 7
How do you handle data imbalance if most product pairs are not matches?
Answer
Data augmentation and weighted sampling help. By oversampling matched examples or undersampling not-matched examples, we ensure the model sees enough positive pairs. Hard negatives help the model learn from the most confusing negative examples. Another solution is using specialized loss functions (like focal loss) that place more emphasis on underrepresented classes. The key is to keep the label distribution realistic so the final model handles real-world conditions.
Follow-up Question 8
What strategies exist to speed up nearest-neighbor searches for embeddings when you have millions of product titles?
Answer
Approximate Nearest Neighbor (ANN) search techniques, such as HNSW (Hierarchical Navigable Small World) or FAISS (Facebook AI Similarity Search), index embeddings so queries can be done in logarithmic or sublinear time. They cluster embeddings and prune large sections of the vector space. This drastically reduces latency compared to brute force scanning. ANN is used in the retrieval stage before the cross-encoder does final reranking.
Follow-up Question 9
Why is hard negative sampling beneficial, and what happens if we do not use it?
Answer
Hard negatives prevent the model from growing complacent with easy negatives that are obviously different. This forces the model to identify subtle differences in near-identical text pairs. Without hard negatives, the model might overfit to simpler patterns. It would struggle when faced with lookalike brands or slight differences in numeric labels. Training becomes more robust by challenging the model to separate tricky pairs.
Follow-up Question 10
How would you handle multilingual product titles?
Answer
Use a multilingual model like XLM-R or a multilingual SBERT variant. Fine-tune on labeled pairs in multiple languages so the model learns cross-lingual alignment. Where possible, unify brand tokens or numeric features across languages. If a strong cross-lingual approach is not feasible, segment the pipeline by language. Perform retrieval and reranking independently in each language track, then unify results.