
ML Case-study Interview Question: Real-Time Recommendation Ranking with Transformers Using User Action Sequences


Browse all the ML Case-Studies here.
Case-Study question
You are leading a recommendation system for a large content discovery platform. The system’s main feed uses a ranking model to surface a small subset of items to users. Historically, the model only used static user embeddings to capture long-term preferences. The platform wants to increase user engagement by incorporating short-term feedback in real time. Many users return to the feed quickly after interacting with items, so the goal is to deliver content that matches their most recent actions as well.
Propose how you would design a ranking model that combines a user’s real-time behavior sequence with existing static embeddings. Discuss data pipeline requirements to stream user events with low latency. Also outline the model design, production deployment considerations, and how you would ensure stable serving performance while handling high traffic. Finally, address any metrics you would track to confirm that real-time signals actually boost overall engagement, and describe how you would keep the model fresh without causing regression or system downtime.
Detailed Solution
A recommendation system that merges real-time user actions with precomputed embeddings can capture both short-term and long-term interests. One effective approach is to augment the existing feed ranking model with a sequence encoder for the user’s recent actions. The pipeline has two main phases: real-time data ingestion and model inference.
In the real-time pipeline, capture the user’s latest actions through a streaming system. Each action includes an item identifier, an action type (e.g. save or click), and a timestamp. Maintain a buffer of the most recent actions per user, usually up to 100 actions. Then transform each action into a vector, such as an item embedding or an action-type embedding. Stream these vectors into a feature store for low-latency retrieval.
At inference time, a ranking service fetches user context (like static user embeddings), candidate items, and the stored real-time sequences. The model merges both types of features:
Static user embeddings that reflect the user’s historical usage patterns.
Real-time sequences of actions that capture short-term interests.
A neural network architecture such as a transformer encoder is ideal for modeling sequential data. The encoder ingests the user’s action embeddings, along with each candidate item’s embedding, to highlight interactions between them. Early fusion of the candidate item embedding with each action in the sequence can improve prediction accuracy. After processing the sequence, the resulting hidden representations are combined with other features through a final set of MLP layers to produce ranking scores.
Switching from CPU-based inference to GPU can handle the high computational load of a transformer. Training must occur frequently to prevent performance decay because real-time signals capture rapidly shifting user preferences. Training at least twice per week, or more frequently if data volume allows, helps sustain engagement improvements. Real-time signals can also create a positive feedback loop: the more relevant the feed, the more often users engage, which further refines the real-time sequence the model sees.
Example Transformer Self-Attention Formula
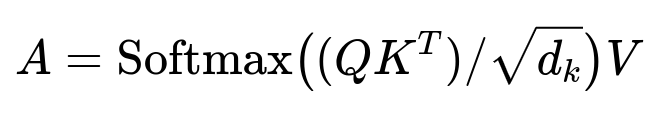
Here, Q, K, and V are transformations of the input sequence embeddings. d_k is the dimensionality of K. Self-attention computes a weighted sum of the value vectors, where weights are derived from the scaled dot-product of queries and keys.
Explaining each element in text (inline plain format for variables):
Q is the query projection of the real-time sequence or the candidate embedding.
K is the key projection of the real-time sequence or the candidate embedding.
V is the value projection, often the same input as K but projected differently.
Softmax(...) normalizes similarities among query-key pairs.
d_k is a scaling factor to keep gradients stable.
Real-Time Data Pipeline Explanation
A stable real-time data pipeline handles these core requirements:
Fault Tolerance. Ensure minimal downtime if any job or network path fails.
Latency Constraints. Batch intervals must be small. The entire retrieval must fit sub-second latencies.
Schema Validation. Validate incoming data to prevent malformed events from breaking inference.
When an event arrives, it is parsed, validated, and joined with item metadata. The system updates user-action sequences in near real time.
Large-Scale Serving
A transformer-based model is compute-intensive. Serving on GPUs can drastically reduce latency while handling large batch sizes. Implement an efficient parallelism strategy to process many requests concurrently on a single GPU instance. Frequent code and model updates demand robust CI/CD pipelines. Blue-green or canary deployment strategies can minimize risk.
Metrics Tracking
Engagement lifts from real-time integration appear in key metrics:
Volume of primary engagement events, such as saves.
Negative signals (like hides) to ensure they do not rise.
Stability over time. If new patterns emerge, the model must be retrained frequently.
If real-time data is used only sporadically, then the potential advantage is not fully realized. If it is used too aggressively, diversity can suffer if the user quickly sees repeated item types.
Handling Decay Over Time
Real-time models that rely on immediate signals can lose effectiveness if not retrained on fresh interactions. Short-term interests shift rapidly. To combat decay:
Increase training frequency, scheduling multiple retraining jobs weekly.
Continuously monitor engagement for any drift.
Maintain fallback logic in case real-time data fails or is delayed.
Practical Tips for Implementation
Frequent user feedback loops will shift the distribution of user actions, so your training data distribution must adapt. Each new user iteration changes the short-term sequence composition. This synergy can lead to greater gains in real production than in small-scale A/B tests.
GPU clusters must be tuned for concurrency. Evaluate peak throughput. Pre-warm GPU instances and optimize frameworks to handle many parallel requests. Thoroughly test the interplay of new real-time features with legacy features.
Follow-Up Question 1
How would you decide which actions to prioritize in the real-time sequence when resources or storage constraints limit how many actions you can keep per user?
Answer Explanation Identify which actions correlate most strongly with your feed’s target metric. If saves drive your primary objective, then saves should be given higher priority. Maintain a balanced subset of positive and negative engagements (such as saves vs. hides) if both matter. Dropping rarely occurring or low-impact actions can free capacity for more frequent, meaningful interactions.
Follow-Up Question 2
You want to ensure the model remains robust if the real-time data pipeline fails. How would you implement a fallback mechanism?
Answer Explanation Store a simple version of short-term preferences or gracefully revert to the static embedding only. The ranking service can detect missing real-time signals and automatically switch to default embeddings. This guarantees continuity if the real-time system is down or partial. Once the pipeline is back up, switch again to the full model pathway.
Follow-Up Question 3
What challenges arise when switching from CPU to GPU inference for a deep ranking model, and how might you address them?
Answer Explanation There are changes in batch processing and concurrency. GPU inference works best with batched requests, so gather requests and feed them in one go. Too-large batches can cause memory overflows. Complex architecture and large embeddings can also stress GPU memory. Optimize model footprint by pruning unneeded layers or compressing embeddings. Tune batch size for maximum throughput without risking timeouts.
Follow-Up Question 4
How would you handle a scenario where the real-time user actions become too narrow and harm content diversity in recommendations?
Answer Explanation Introduce a slight random time-based masking or limit how aggressively short-term signals dominate. A fraction of items can come from broader user interest or from a random exploration pool. Weighted blending of long-term embeddings with short-term signals balances responsiveness with coverage. Monitor if certain engagement metrics drop, and adjust the weighting of real-time signals accordingly.
Follow-Up Question 5
Why might final performance in full production be better than in a controlled A/B test, and how should you monitor this effect?
Answer Explanation Positive feedback loops unfold more strongly in full production because more users see highly relevant items, increasing engagement. That extra engagement refines the short-term signals for the next training cycle. Monitor daily or weekly engagement to see if usage patterns significantly change. Track shifts in real-time sequence composition (like increasing saves). Adjust training intervals if usage changes faster than expected.
Follow-Up Question 6
What additional data or modeling strategies could further improve real-time recommendations?
Answer Explanation Include metadata such as action context or session context. Possibly embed features describing the time spent on items. Expand the real-time window to capture more behavior while ensuring no latency spikes. Experiment with advanced architectures like multi-head attention on each action’s metadata. Explore new negative feedback signals to better avoid irrelevant items.
Follow-Up Question 7
How would you handle concept drift or sudden changes in user behavior (for example, seasonality or viral trends)?
Answer Explanation Monitor engagement distribution changes in real time. If a certain category or style of content surges, a real-time signal can capture it quickly. Trigger more frequent retraining or partial fine-tuning if the data distribution deviates significantly from historical patterns. A partial model update with fresh user sequence data can help the system react to abrupt shifts without waiting for a full training cycle.
Follow-Up Question 8
Explain how cross-feature interactions (for example, short-term user sequence combined with user demographics) can be modeled. Would you add them explicitly or let the network learn them implicitly?
Answer Explanation Interaction layers like a product-based neural network or a cross network can explicitly model feature interactions. This can help the system recognize non-linear relationships between short-term behavior and demographic groups. Alternatively, large deep networks might capture these interactions implicitly. For interpretability or extra accuracy, explicitly modeling cross features is often beneficial.
Follow-Up Question 9
How do you evaluate the effectiveness of each part of the pipeline in isolation (e.g. the real-time embedding generation vs. the transformer encoder) to confirm improvements come from the entire approach?
Answer Explanation Ablation tests measure individual feature impacts. Compare a baseline with no real-time sequence, a model with real-time features but no transformer, and a model with both. Track metrics on each step to see incremental lifts. If real-time signals are present but the encoder is off, see how performance changes. These tests confirm each pipeline component’s contribution to final results.
Follow-Up Question 10
What potential limitations of a transformer-based approach should you watch out for in a high-throughput environment?
Answer Explanation A multi-layer transformer can be large, making inference costly unless carefully managed. It may require specialized acceleration like GPUs or custom hardware. Large parameter counts risk slower throughput or memory issues. Real-time updates also mean your system must handle frequent model refreshes. You must continuously monitor latency, memory usage, and costs, since transformers can blow up your infrastructure if left unchecked.