
ML Case-study Interview Question: Optimizing Millions of E-commerce Ad Bids via a Hybrid ML/Rules Architecture.


Browse all the ML Case-Studies here.
Case-Study question
You are given an e-commerce platform's ads bidding scenario. The system must generate optimal cost-per-click bids across millions of product listings and keywords. The platform attempts to combine heuristic- and ML-based algorithms under a single architecture, while ensuring scalability, observability, and easy experimentation. How would you design a complete end-to-end ads bidding solution for this company, including data ingestion, feature engineering, model training, bid arbitration, and final bid deployment? What challenges do you foresee, and how do you address them?
Detailed In-Depth Solution
The core challenge is to decide how much to pay for each click without overspending or missing potential traffic. This requires high-volume data pipelines, robust model deployment, real-time adjustments, and analytics.
Data Engineering
Large streams of events flow in from internal logs and external ad platforms. Engineers build a unified pipeline that aggregates, cleans, and standardizes features. These features include historical spend, click-through rates, conversions, product attributes, and search keywords. A modular data transformation system avoids large fragile scripts. Instead, each transformation is a small, reusable unit. Records are enriched with various flags or values (for example, abnormal spikes can be filtered or imputed).
Bidding Console
A console allows business analysts or data scientists to specify objectives such as ROI = (Revenue - Cost)/Cost. It also enables them to calibrate aggressiveness or maintain budgets for specific product groups. Users tune these levers at different granularity (for example, individual product lines).
Single Bid Calculators
Each calculator takes a bidding unit (for example, a single SKU) and uses the relevant features to produce a bid. One calculator might use a rule-based approach (for instance, a simple multiple of past average cost-per-click). Another might load a trained regression or neural model to forecast expected profit margin, then output a maximum willingness to pay.
The platform supports multiple calculators in parallel, each generating its own bid. This modular design encourages experimentation. If a new calculator performs well for certain products, the system can route relevant traffic to it.
Arbitration
When multiple calculators produce different bids, an arbitration component decides which bid to finalize. Sometimes the system picks the highest. Sometimes it falls back if the primary calculator lacks enough data. Sometimes it runs an A/B test to compare. This mixing approach broadens coverage and facilitates quick swaps of new approaches.
Vendor Mapping
Once the platform selects final bids, the system maps internal product identifiers into the identifiers expected by external channels (for example, vendor-specific campaign IDs). Bids are then pushed out through APIs (for instance, Google Ads or Bing Ads) at scale.
Key Technologies
A parallel data processing framework (such as a managed big data platform) scales these computations. A fast key-value store can fetch features and store final results with low latency. Python code can quickly load ML models in-memory. A robust SQL/analytics warehouse is essential for advanced queries, debugging, and validation. Containerized web services handle control-plane functionalities such as real-time updates and health checks.
Example Python Snippet
Below is a simplified illustration for a single bid calculator that uses a trained regression model:
import joblib
import aerospike
# Load the regression model
model = joblib.load("my_regression_model.pkl")
# Connect to Aerospike for features
client = aerospike.client({"hosts": [("127.0.0.1", 3000)]}).connect()
def single_bid_calculator(bidding_unit):
# Retrieve features
key = ("namespace", "set_name", bidding_unit)
_, _, record = client.get(key)
# Example features
avg_conversion_rate = record["avg_conversion_rate"]
past_cpc = record["past_cpc"]
# More features...
# Model inference
features_vec = [avg_conversion_rate, past_cpc] # plus others as needed
predicted_margin = model.predict([features_vec])[0]
# Simple logic to produce a bid
# We can refine formula or add business constraints
recommended_bid = predicted_margin * 0.5
return recommended_bid
Multi-Armed Bandit for Rapid Optimization
Some solutions use a multi-armed bandit approach to continuously adapt bidding strategies. A key formula for the upper confidence bound (UCB) method is:
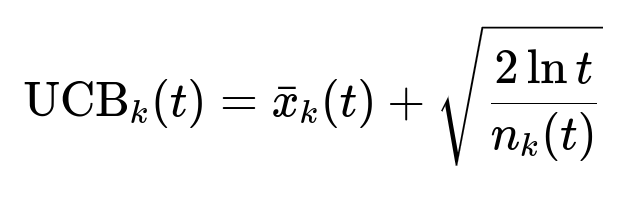
Where:
t is the total number of observations so far (sum of all arms’ trials).
n_k(t) is how many times arm k was chosen until time t.
x_k(t) is the average observed reward for arm k.
UCB_k(t) is the optimistic estimate of the expected reward for arm k.
The system picks the arm with the highest UCB, explores it, and updates statistics accordingly. This mechanism continuously balances exploration (trying new strategies or product categories) with exploitation (investing more heavily in proven strategies).
Challenges
Large catalogs demand careful scaling. Many items have sparse data or irregular traffic, so pure ML might fail unless combined with rules or fallback heuristics. Auction dynamics change frequently, so real-time or near-real-time updates are important. Observability is also vital. Analysts must see logs, metrics, or dashboards showing which model set a given bid and why.
Follow-Up Question 1
How do you handle cold-start scenarios for new products or keywords with insufficient historical data?
Answer Explanation
Models rely on historical performance signals. New products have no clicks or conversions. A fallback model might produce a baseline bid (for instance, a category-average-based approach). Another possibility is to cluster products by similar attributes or predicted popularity, then use aggregated historical data from those clusters. A bandit-based approach that systematically tries uncertain arms speeds up the learning. Over time, new items accumulate enough data for more specialized models.
Follow-Up Question 2
How do you run experiments to compare different bidding models without harming overall performance?
Answer Explanation
Experimentation is controlled by the arbitration layer. The system can randomly assign a small percentage of traffic to a candidate model. The rest uses the incumbent approach. Analysts compare metrics such as click-through rate, conversion rate, cost per conversion, and overall ROI. If the new model outperforms the baseline, the system can gradually expand traffic. If performance drops or hits a safeguard threshold, the system reverts to the baseline to mitigate losses.
Follow-Up Question 3
How do you maintain system observability when multiple Single Bid Calculators and fallback rules exist?
Answer Explanation
Each calculator logs its decision path. The arbitration layer also logs which calculator's bid was chosen. Telemetry records final bids, real-time spend, and conversions. A unified dashboard aggregates these metrics by channel, product category, or date range. Engineers can pinpoint anomalies. Historical logs reveal how each model behaved over time and why certain bids were chosen. Continuous monitoring flags deviations from expected performance.
Follow-Up Question 4
What would you do if external ad platform constraints changed? For example, a new vendor requires daily budget caps in a different format.
Answer Explanation
A vendor-mapping step adapts bids and metadata to the external format. If a new vendor enforces daily budgets in a unique structure, engineers update the mapping logic without reworking the core platform. The console can add a parameter for daily budget caps per vendor, hooking into an API call that sets these caps. This separation ensures the core system remains consistent, and only vendor-specific translation layers change.
Follow-Up Question 5
How do you ensure the system remains modular when adding new ML algorithms or rules?
Answer Explanation
Each new approach is a separate Single Bid Calculator. That calculator reads the same standardized features. It calculates a new bid, returning either a numeric value or indicating insufficient data. The arbitration layer processes all returned bids. Because each calculator is a plug-in module, changes do not affect the rest of the pipeline. Observability, data ingestion, and vendor mapping remain consistent.
Follow-Up Question 6
Why might you consider switching from rules-based optimizations to a more automated bandit approach?
Answer Explanation
Manually setting or tuning rules is labor-intensive and might overfit historical patterns. A bandit approach explores unseen conditions and quickly identifies winning strategies. It adapts to real-time signals, making it more reactive to changing user behaviors, product availability, or shifts in competitor bidding. Automated exploration can discover opportunities that a fixed rules-based approach could overlook.
Follow-Up Question 7
How do you handle data latency and synchronization, given that you must update bids frequently?
Answer Explanation
Frequent updates need efficient data aggregation windows (for example, daily or hourly). Real-time streaming might be too costly for every calculation, so a near-real-time approach using micro-batching is typical. The platform uses a fast in-memory store to retrieve current statistics for quick lookups. Larger offline processes compute aggregated metrics. The system merges these pieces to produce stable bids with minimal lag.
Follow-Up Question 8
How would you scale this approach to millions of SKUs while maintaining accuracy and speed?
Answer Explanation
Use distributed data processing frameworks that split the workload across many executors. Each Single Bid Calculator runs independently on each SKU, enabling parallelism. A key-value or columnar store with indexing accelerates lookups. The entire pipeline is orchestrated so transformations and model predictions happen in parallel chunks. Containerization or managed job frameworks can spin up additional nodes for large spikes in SKU volume.
Follow-Up Question 9
What error or cost metrics do you monitor after deployment?
Answer Explanation
Ads cost can spike if bids are too high. Click volume can drop if bids are too low. ROI can degrade if user conversions do not keep pace with ad spend. Observing cost per conversion, overall click volume, conversions, and margins is critical. Significant deviations prompt investigation. The logs and dashboards let you see if a particular model or fallback is systematically bidding incorrectly.
Follow-Up Question 10
If a new acquisition channel emerges with a different bidding mechanism, how can you extend your platform?
Answer Explanation
The platform’s modular design applies. A new Single Bid Calculator can be developed for that channel’s unique data. The new channel also goes through the vendor-mapping step to convert internal identifiers to external IDs or handle unique budget constraints. Arbitration logic can incorporate this channel as an additional participant in the final bid mix. The same console and data pipeline handle configurations unless the new channel requires new features, in which case the pipeline is extended accordingly.