
ML Case-study Interview Question: Style Embeddings for Coherent, Scalable 'Complete the Look' E-commerce Recommendations


Browse all the ML Case-Studies here.
Case-Study question
You are a Senior Data Scientist at a large e-commerce platform tasked with building a system that recommends a set of complementary items to complete an outfit. You must handle product taxonomy, address style coherence, ensure coverage for a massive catalog, and optimize user engagement (clicks, add-to-cart, purchases). How would you design and implement such a “Complete the Look” recommendation system at scale?
Detailed Solution
Candidate Selection
Identify items that pair well with the main product. Use existing complementary item signals (co-purchase, co-view) and cold-start models. Filter candidates by age range, gender, season, and any blacklist criteria.
Look Definition
Group product types into super product types. For instance, group different kinds of jackets into a single super product type. Construct a look by combining 4 to 5 distinct super product types. Adjust super product types using user feedback. If certain super product types lead to low engagement, deprioritize or remove them.
Look Generation
Apply complementary recommendations to populate each component of the look. For an anchor shirt, pick a pair of pants, a jacket, and accessories from the recommended candidates. Each segment is restricted to super product types. If no candidate appears in a required category, fetch items from style embeddings.
Outfit Style Matching
Compute a style embedding for each item so items in an outfit look visually coherent. Train style embeddings with a triplet-learning method:
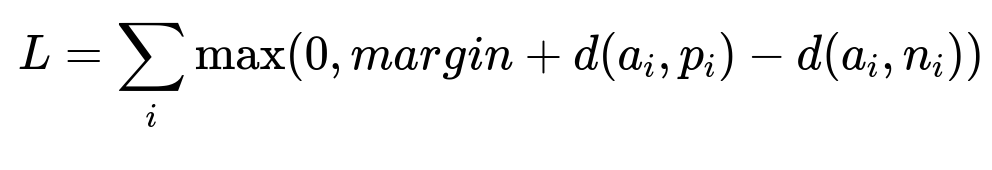
Here, L is total triplet loss, margin is a small constant, a_i is the anchor item, p_i is a positive (compatible) item, n_i is a negative (incompatible) item, and d(x,y) is distance in embedding space. Curate training triplets from merchant-created outfits and real user interactions (clicks, add-to-cart).
Eliminate images with human limbs or unrelated clutter. Use a simple two-step classifier to select “laid-down” images. Example Python snippet:
import torch
import torchvision.transforms as T
from PIL import Image
# Simple pipeline to detect presence of human
model = torch.hub.load('pytorch/vision', 'mobilenet_v2', pretrained=True)
model.eval()
def is_cluttered(img_path):
img = Image.open(img_path).convert('RGB')
transform = T.Compose([T.Resize(224), T.ToTensor()])
tensor_img = transform(img).unsqueeze(0)
with torch.no_grad():
outputs = model(tensor_img)
# Pseudocode: check outputs for presence of arms/legs or multiple items
return some_threshold_check(outputs)
# Then filter out images that fail the criteria
Permute anchor-item positions when building looks. If a pair of jeans anchors one look, flip it so the original anchor shirt becomes a recommended item.
Look Ranking and Variant Expansion
Rank generated outfits with a weighted mix of color compatibility, brand affinity, and price proximity. Expand to other size variants of the same anchor. Reuse the same recommended set for all matching variants.
Coverage Expansion
Search-and-refine approach to replace or replicate items from hand-crafted outfits with visually similar items. Use image embeddings (like CLIP) in a nearest-neighbor index (e.g., Faiss or ScaNN) to find visually matching items. Apply domain checks (e.g., consistent size, age, gender) to ensure coherence.
Potential Follow-Up Questions
How would you handle cold-start items with minimal historical data?
Use metadata-driven recommendations. Train a model to understand product attributes like category, brand, color, and textual features from item descriptions. Combine that with a visual embedding extractor for images. When no interaction data exists, rely on these metadata or image-based signals to place items into appropriate looks.
How do you evaluate the “Complete the Look” recommendations?
Track user engagement signals: impression counts, click-throughs, add-to-cart events, and conversions for recommended sets. Perform online A/B testing with a holdout group to see how the overall revenue or basket size changes. Evaluate offline with curated test sets from stylists, measuring precision and recall of correct complementary items.
How do you address seasonality changes?
Maintain a dynamically updated filter that captures relevant season attributes in each product’s metadata. During colder months, remove or reduce items like tank tops or sandals in the recommended sets. Adjust parameters automatically by monitoring shift in user interaction patterns (e.g., fewer clicks on summer items in winter).
How do you prevent trivial color matching that ignores style diversity?
Enhance embeddings beyond color data by including shape, pattern, brand, price range, and textual features. Use curated fashion-labeled datasets to ensure the style embedding captures more than color similarity. Use attention-based methods on textual descriptions to incorporate brand or style cues into embeddings.
Could you discuss data leakage risks in the training process?
If user interaction data includes time-sensitive or unusual co-purchases, the model might overfit to transient trends. Introduce time splits in training and validation sets to replicate real-world conditions. Apply robust cross-validation, ensuring the model generalizes to newly introduced items rather than memorizing fleeting behaviors.