
ML Case-study Interview Question: Predictive Filtering & Generative AI Checks for Accurate Product Typing at Scale.


Browse all the ML Case-Studies here.
Case-Study question
A large online marketplace manages over 400 million items with a hierarchical categorization system. Each product has a main category (for example, “Toys” → “Outdoor Toys” → “Pool Toys”) and also belongs to a product type hierarchy that describes the product’s intended use. Sometimes items end up in the wrong subcategory due to errors or incomplete information. This leads to poor user experience when browsing or searching for items. You need to design and implement a machine learning solution that identifies correct product types for each category. The solution should combine Predictive AI and Generative AI to reduce misclassifications, handle rarely visited categories, and work at scale for several million <Category, ProductType> mappings. Propose an approach to build, deploy, and maintain such a system that meets a strict service-level agreement of a few milliseconds. Address how you would threshold confidence scores, prevent hallucination, manage caching for fast lookups, handle exceptions, and continually improve model performance.
Provide a detailed plan including:
Your modeling strategies to combine Predictive AI and Generative AI for filtering relevant <Category, ProductType> pairs.
The data structures and caching approach for real-time lookups.
The metrics you would track (precision, recall, TPR, FPR, etc.) and how you set thresholds.
Methods to reduce hallucination in Generative AI outputs.
How you would implement an exception-handling mechanism to correct misclassifications.
Your plan to iterate and maintain the solution over time.
Detailed Solution
Predictive AI models learn from domain-specific signals (for example, item descriptions or shipping attributes). Generative AI models bring strong language understanding. An ensemble approach uses both predictions and generative reasoning to reduce false positives. First, Predictive AI filters out most irrelevant <Category, ProductType> pairs at scale. Then Generative AI inspects the smaller set of pairs to remove subtle mismatches. This lowers the burden on expensive Generative AI inferences. Confidence thresholds for both models decide which pairs to keep.
Predictive AI modeling
Train supervised classifiers using features such as text embeddings from product descriptions, brand names, item attributes, and any domain-specific signals. Fit each model’s hyperparameters by optimizing:
Precision, so fewer false positives occur.
Recall, so fewer correct pairs are missed.
F1, as a harmonic mean of precision and recall.
TPR and FPR, to monitor model sensitivity and the rate of incorrect predictions.
Below are common evaluation metrics:
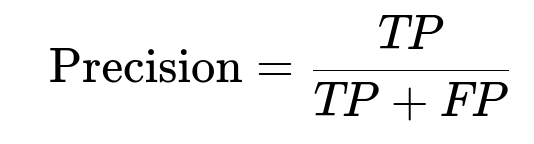


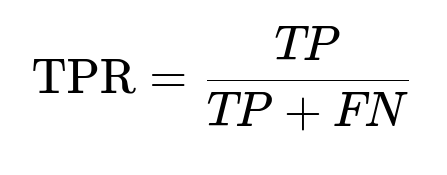
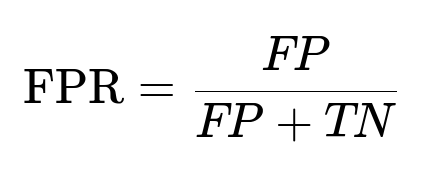
TP is the number of true positives, FP is the number of false positives, FN is the number of false negatives, and TN is the number of true negatives. Configure threshold values for each classifier so that FPR remains low. Retain pairs exceeding that threshold.
Generative AI filtering
Pass the reduced <Category, ProductType> set to a Generative AI system that uses domain context. Symbol tuning can re-weight category paths more heavily at the leaf node. Chain-of-thought prompting guides the Generative model to produce reasoned relevance checks. Hallucination is less problematic because the Generative AI only filters pairs that cleared the Predictive stage. Set a final confidence threshold for the Generative output to remove borderline pairs.
Real-time integration
Offline, process several million <Category, ProductType> mappings to generate a final “allowed list.” Online, respond to user-category queries with a two-tier LRU caching mechanism:
L1 cache stores the most frequently queried <Category, ProductType> sets in a very small, fast area.
L2 cache holds more data but is slightly slower. If the needed data is absent in L1 and L2, fetch from primary storage. This approach meets a few-millisecond response time requirement.
Example Python snippet for caching
class TwoTierCache:
def __init__(self, size_l1, size_l2):
self.l1_size = size_l1
self.l2_size = size_l2
self.l1 = OrderedDict() # {category: set_of_product_types}
self.l2 = OrderedDict()
def get(self, category):
if category in self.l1:
value = self.l1.pop(category)
self.l1[category] = value
return value
elif category in self.l2:
value = self.l2.pop(category)
# Put in L1
if len(self.l1) >= self.l1_size:
self.l1.popitem(last=False)
self.l1[category] = value
return value
return None
def put(self, category, product_types):
if category in self.l1:
self.l1.pop(category)
elif category in self.l2:
self.l2.pop(category)
elif len(self.l2) >= self.l2_size:
self.l2.popitem(last=False)
self.l2[category] = product_types
This outlines the logic for storing or retrieving sets of product types keyed by categories.
Exception-handling
Even with low FPR, misclassifications can appear. Build an exception-handling layer to detect anomalies. Monitor user feedback or run scheduled checks, then retrain or fine-tune models if an item is repeatedly misclassified. Maintain a human review step for complicated cases.
Ongoing improvement
Collect new data from system usage to identify rare product types or newly created categories. Periodically retrain Predictive models. Use symbol tuning with new context strings for Generative AI. Adjust thresholds if usage patterns change. Keep an eye on TPR, FPR, and user satisfaction signals to decide whether to update or roll back a model.
Follow-up question 1
How do you ensure the Predictive AI model remains robust when certain categories have very few labeled samples?
Answer and Explanation Use transfer learning or embed text from categories into a shared representation (for example, a pretrained language model). Fine-tune on the limited labeled samples. Employ data augmentation by synthesizing domain text or item descriptions, then train the classifier. Incorporate advanced regularization, like dropout or L2 penalties, to avoid overfitting on small data. Ensemble different base classifiers, each capturing distinct signals, and combine their outputs via a weighted average or voting scheme to help mitigate sparse data.
Follow-up question 2
How do you pick your threshold for FPR so that your Generative AI stage does not become a bottleneck for large-scale inference?
Answer and Explanation Evaluate the Predictive AI model’s performance at various FPR levels on a validation set. Plot the inference volume (number of candidate pairs) against FPR. Choose an FPR that keeps candidate volume manageable for Generative AI while balancing coverage (recall). This threshold ensures you don’t overburden the Generative stage or discard too many true positives. Confirm it by measuring final ensemble performance on precision, recall, and overall resource usage.
Follow-up question 3
What steps do you take when your Generative AI model starts hallucinating new product types not present in your catalog?
Answer and Explanation Apply chain-of-thought prompting. Instruct the model to reference only known product types from an explicit dictionary or path-based string. Limit the temperature parameter to reduce creative outputs. Maintain a short list of valid product types so the model’s final outputs are compared against it. Any suggestion outside that list is flagged and excluded. Monitoring logs for out-of-vocabulary product types helps detect consistent hallucinations.
Follow-up question 4
How do you handle overhead when storing millions of <Category, ProductType> mappings in your caches?
Answer and Explanation Keep only the most-queried <Category, ProductType> sets in L1, and moderately popular sets in L2. The rest remain in primary storage. LRU eviction policies prune items that haven’t been requested recently. Compress large sets (for instance, storing them as hashed bitsets or consolidated lists). If memory is exceeded, shrink cache sizes or re-tune caching strategy. This balances memory usage with query latency.
Follow-up question 5
If the data distribution shifts and the overall recall drops, how do you adapt?
Answer and Explanation Retrain Predictive models with fresh data from new categories or new item descriptions. Adjust thresholds to accommodate the changed distribution. Re-collect labeled samples in underperforming categories. Conduct error analysis to see if new product types or synonyms are missing from the Generative AI prompts. Update chain-of-thought or symbol tuning instructions for the Generative stage. Re-validate performance metrics and confirm that the ensemble solution still meets production standards.