
ML Case-study Interview Question: Scaling Semantic Relevance Classification with Fine-Tuned LLMs in E-commerce Search.


Browse all the ML Case-Studies here.
Case-Study question
You are working at a large online marketplace with a vast product inventory. Your team wants to measure and improve semantic relevance in search results. The goal is to label query-product pairs as one of four categories (Exact, Substitute, Complement, Irrelevant) based on their similarity and functional match. The marketplace deals with open-ended queries, ambiguous buyer intent, and sparse user engagement signals. Propose a solution for automatically classifying semantic relevance for tens of millions of query-product pairs per day, and explain how you would handle the data labeling, model fine-tuning, performance evaluation metrics, and large-scale inference deployment.
Defining semantic relevance
Semantic relevance is broken into four levels: Exact, Substitute, Complement, and Irrelevant. Exact means the product perfectly matches all essential aspects of a query. Substitute means partial match for the same functional need. Complement means items that go with an Exact item but do not fulfill the query. Irrelevant means the item does not meet key aspects of the query. Vague queries (like "bat") can have multiple interpretations, so guidelines are needed to unify labeling.
Acquiring labeled data
Human annotators follow explicit guidelines. This step clarifies edge cases and ensures consistent labeling. A higher volume of labeled data improves model performance. Sparsity of user engagement data (clicks, carts, orders) is not enough because many product-query pairs lack impressions or user feedback.
Model approach
Prompt engineering alone cannot capture nuanced marketplace definitions of relevance. Fine-tuning a Large Language Model (LLM) with labeled data is required. Freezing base weights and adding a lightweight adapter (like LoRA) reduces training cost and speeds up iteration. Smaller model sizes often suffice for specialized tasks.
Training details
Training uses a text completion objective where the model sees a concatenation of query and product attributes and outputs a single relevance label. Minimizing cross-entropy for the target label directs the model to predict the correct category.
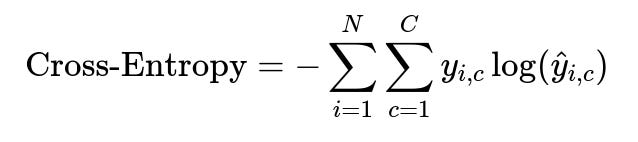
Here, y_{i,c} is 1 if the i-th example’s label is category c, else 0. The model’s predicted probability for category c is denoted by hat{y}_{i,c}. N is the number of training examples, and C is the number of possible classes (4 in this case).
Evaluating performance
Krippendorff’s Alpha measures agreement with human labels across four categories. Scores near 1 indicate near-perfect agreement. F1 Score for exact vs not-exact is also tracked because exact matches have stricter criteria. Models must differentiate between partial matches and exact matches.
Large-scale inference
Self-hosting an open-source model yields lower cost than a third-party API. Batch inference on GPU clusters is crucial to handle tens of millions of daily queries. Techniques include:
Quantizing to 8-bit.
Batching multiple samples per forward pass.
Using optimized inference frameworks and horizontally scaling GPU instances.
Potential Python workflow
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from my_lora_adapter import apply_lora_adapter
model_name = "YourLLMModel"
tokenizer = AutoTokenizer.from_pretrained(model_name)
base_model = AutoModelForCausalLM.from_pretrained(model_name)
lora_model = apply_lora_adapter(base_model)
lora_model.load_state_dict(torch.load("trained_lora_adapter.pth"))
lora_model.eval()
device = "cuda"
lora_model.to(device)
def predict_relevance(query, product_info):
input_text = query + " " + product_info # Concatenate as needed
inputs = tokenizer(input_text, return_tensors="pt").to(device)
with torch.no_grad():
outputs = lora_model.generate(**inputs, max_new_tokens=1)
prediction = tokenizer.decode(outputs[0], skip_special_tokens=True)
return prediction
# Example usage
sample_query = "white ceramic mug 11 oz"
sample_product = "product_name: Modern Ceramic Mug; description: 11 oz, color: white"
pred_label = predict_relevance(sample_query, sample_product)
print("Predicted Relevance:", pred_label)
No real-time serving is shown here. For batch inference, load large sets of query-product pairs, tokenize in batches, and run them through GPUs. A job scheduler (like Airflow or Kubernetes jobs) can coordinate daily labeling pipelines.
Follow-Up Question 1
How would you refine relevance guidelines so different annotators agree consistently?
Answer:
Refining guidelines requires examples and short decision trees. Ambiguous queries (e.g., "chips") need explicit directives on acceptable synonyms (potato chips vs chocolate chips) to avoid confusion. Annotators receive small sets of gold-standard examples, followed by calibration sessions to reinforce the definitions. Incremental updates incorporate feedback from disagreements to reduce subjectivity. Formal decisions on borderline items get documented in a shared reference.
Follow-Up Question 2
How do you handle queries that lack explicit attribute context (e.g., color or size) but might be implied?
Answer:
Conservative assumptions protect relevance quality. For partial or implied attributes, treat them as overshadowed by the main functional aspect unless guidelines state otherwise. If a query states "ceramic bowl" with no size, treat small, medium, and large as valid. If a query states "baseball bat" but doesn’t mention "wood" or "metal," treat any standard baseball bat as Exact. Clear guidelines maintain labeling consistency.
Follow-Up Question 3
Why is Krippendorff’s Alpha preferred over simple accuracy or precision/recall for four-class relevance?
Answer:
Krippendorff’s Alpha accounts for chance agreement and penalizes misclassifications across all categories. Simple accuracy might hide the severity of mistakes if the dataset is imbalanced. Precision/recall for a single class ignores confusion between the other categories (like mixing Substitute and Complement). The Alpha metric ensures the model’s predicted labels match human standards across every relevance category, which better captures semantic differences.
Follow-Up Question 4
How do you extend the approach to multimodal contexts where images matter?
Answer:
A multimodal LLM can incorporate visual representations to capture style or color references missing from text. Fine-tuning uses both textual descriptions and image embeddings. Missing domain context (like brand style or brand product lines) can also be added through retrieval-augmented generation. The inference pipeline merges textual and visual encoders, then outputs a combined embedding for classification. The approach needs more memory and specialized training data with paired images and text.
Follow-Up Question 5
What is the main bottleneck when scaling to tens of millions of daily predictions, and how do you optimize?
Answer:
Inference throughput is the bottleneck. Batching queries efficiently on GPUs is critical. Quantizing model weights (for example, from float16 to 8-bit) can reduce memory bandwidth and speed up the forward pass. Running a fast serving framework, then horizontally scaling GPU pods ensures no single node’s capacity is overwhelmed. Monitoring GPU utilization is key for autoscaling decisions.