
ML Case-study Interview Question: Real-Time Personalized Recommendations at Scale Using Two-Tower Neural Networks.


Browse all the ML Case-Studies here.
Case-Study question
A large platform has diverse content that users interact with daily. They seek a machine learning pipeline to personalize item recommendations in real-time. They have a massive user base, millions of items, and want to minimize latency. They need to ingest streaming data, build user and item representations, and rank items. How would you design an end-to-end system that handles cold starts, ensures model scalability, and improves real-time predictions? How would you evaluate its performance and maintain efficiency in production?
Detailed Solution
Data ingestion
They gather user interactions such as clicks, watch-time, and dwell-time. They store these logs in a streaming pipeline. They separate the data into real-time streams for immediate processing and longer-term storage for offline batch updates. They transform raw interaction events into structured data with user IDs, item IDs, and context features. They store everything in a data lake or warehouse for offline analytics and modeling.
Feature engineering
They create user embedding vectors and item embedding vectors. They start with straightforward features like category, language, or user demographics. They incorporate time-based features like session length and frequency of past activity. They use historical data to refine user preference patterns. They handle cold starts by fallback features (for new users or items) using aggregated popularity or category-level embeddings. They capture session context in a short-term embedding representation.
Model training
They create a two-tower neural network. One tower ingests user features. The other tower ingests item features. They project these towers into low-dimensional embeddings. They generate a matching score by computing the dot product of these embeddings. They train this network on historical interactions.
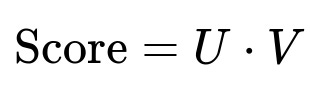
Where U is the user embedding vector of dimension d, and V is the item embedding vector of dimension d. The dot product is the predicted affinity. They optimize a loss function that separates positive from negative examples. For every positive interaction y=1, they sample negative items y=0. They use an optimizer like Adam. They handle large data by distributed training on a cluster.
Real-time ranking
They store item embeddings in a key-value lookup for fast retrieval. They retrieve the top candidates using approximate nearest neighbor search. They apply a secondary ranking model that refines the shortlist with additional context signals. They integrate recency-based signals to capture the latest content. They compute final scores in real-time and select the top N items.
Evaluation strategy
They run offline experiments using metrics like recall at K, mean average precision, and normalized discounted cumulative gain. They run A/B tests in production. They compare engagement uplift against existing baselines. They monitor changes in user retention, time spent, or conversions. They apply an online evaluation framework to track model drift and user segment variations.
Scalability and maintenance
They use a scalable message queue system to handle incoming events. They maintain a streaming cluster that processes raw logs in near-real-time. They orchestrate periodic batch training jobs for major model updates. They push incremental updates to item embeddings or user embeddings as new data flows in. They keep track of concept drift by retraining the model as needed. They use model versioning to safely roll back if performance degrades.
Follow-up question 1
How do you handle items that appear suddenly and gain popularity but have minimal historical data?
Answer and Explanation
They identify new items through real-time ingestion. They assign fallback item representations based on high-level attributes like category or domain. They cluster item embeddings by category or metadata and assign the new item to the closest cluster centroid. They store minimal embeddings derived from that cluster. They update these embeddings quickly once user interactions grow. They track item popularity in streaming updates to adjust item embeddings in near real-time. They incrementally fine-tune the item tower using fresh clicks or impressions from this new item.
Follow-up question 2
How would you handle partial user data gaps and ensure robust user embeddings?
Answer and Explanation
They track data completeness in the feature pipeline. If certain attributes are missing, they impute them from user-level aggregates or similar user clusters. They integrate embedding fallback for sparse user data. They maintain a baseline vector for unknown features. They incorporate session-based embeddings that capture short-term signals. They reduce dimensional instability by normalizing input features and limiting embedding size. They use batch normalization or layer normalization in the user tower. They run frequent data-quality checks to prevent corrupted or incomplete records from harming the embedding process.
Follow-up question 3
Explain how you would monitor this system in production and optimize latency.
Answer and Explanation
They measure average latency through counters at each stage of the recommendation pipeline. They enable internal profiling on the approximate nearest neighbor system and the ranking model calls. They cache frequently accessed user embeddings. They offload heavy computations to a specialized cluster for vector similarity searches. They store precomputed shortlists of items for hot segments. They use asynchronous updates to refresh embeddings outside the main serving path. They keep a strict Service Level Agreement to ensure the retrieval and ranking steps stay within a few milliseconds. They continuously analyze load patterns to autoscale infrastructure up or down.
Follow-up question 4
How would you improve your model or pipeline if engagement metrics plateau?
Answer and Explanation
They revisit feature engineering by integrating richer contextual features, such as location or device type. They add user feedback signals like explicit thumbs-up or skip actions to fine-tune item embeddings. They experiment with ensemble approaches, combining the two-tower model with a gradient-boosted tree ranker. They explore advanced sequential models that leverage transformer-based architectures for session modeling. They re-check hyperparameters and optimizer settings for better convergence. They refine the negative sampling strategy to provide more difficult examples. They run targeted experiments with small user cohorts to confirm gains.
Follow-up question 5
How would you incorporate interpretability into these deep models for item recommendations?
Answer and Explanation
They use feature importance analysis on user and item representations by systematically altering inputs and observing the impact on the score. They train a surrogate model like SHAP or LIME on top of the neural net. They examine the embedding dimensions to see how specific attributes (categories or tags) affect final similarity. They present partial user-level explanations, such as highlighting top contributing features to item selection. They store model outputs in a database with user-context logs for debugging. They implement explainable re-ranking modules that show the main reasons why certain items were ranked higher.
Follow-up question 6
How would you confirm reliability in edge cases like sudden user growth or item surges?
Answer and Explanation
They stress-test the pipeline with synthetic traffic spikes to confirm that it can handle large surges. They run real-time anomaly detection to flag outliers. They maintain separate queues for high-priority events. They provide circuit breakers to degrade gracefully if latency thresholds exceed safe levels. They keep fallback solutions like precomputed top-popular items if the main system is overloaded. They confirm that new user embeddings or item embeddings are created fast enough to not produce stale recommendations for an extended period. They frequently measure throughput and memory usage to ensure no single component is a bottleneck.
Follow-up question 7
Explain how you would approach personalization beyond item embeddings.
Answer and Explanation
They incorporate contextual bandits for personalized exploration-exploitation. They track immediate rewards from user clicks or watch-time. They feed features about user session context into the bandit model to choose items for each request. They also test multi-armed bandits on top of the final ranking. They record reward signals (like dwell time) to quickly tune exploration. They compare bandit-based approaches with the standard offline-trained models in an online A/B test. They measure improvement in user retention or new content discovery. They refine the reward function to reflect short-term user satisfaction and long-term engagement. They frequently update the context features to ensure the bandit has accurate states for better decision-making.