
ML Case-study Interview Question: Maximizing Cross-Selling Revenue: Deep Learning with a Custom Profit-Driven Loss Function.


Browse all the ML Case-Studies here.
Case-Study question
A large online payment platform wants to improve cross-selling of its financial products to merchant customers. The Sales team can only reach a limited subset of these customers, and each outreach has a cost. The business wants a machine learning solution that prioritizes high-value leads while controlling outreach costs, to maximize total revenue. Design a data science strategy and a deep learning based solution that addresses these constraints. Propose the model architecture, the custom loss function, and how you would train and evaluate this solution.
Detailed Solution
Problem Understanding
Sales outreach has a cost. Only a limited number of customers can be contacted. Prior solutions used a binary classification approach with the usual binary cross-entropy objective. That approach maximizes classification accuracy but does not consider deal size or outreach cost. A new loss function is needed to emphasize higher sales gain and cost trade-offs.
Classic Binary Cross-Entropy
Standard binary classification learns to separate positive cases (likely responders) from negative ones (unlikely responders). The default loss function is:
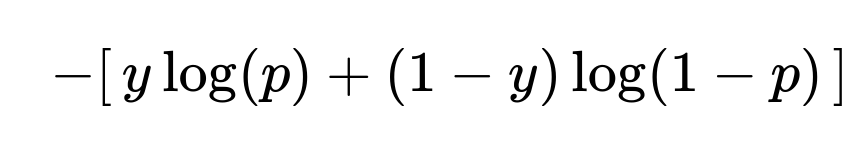
y is the true label (0 or 1). p is the predicted probability between 0 and 1. This loss treats all positive cases the same and does not factor in potential revenue or cost.
Custom Loss Function
Model training should focus on expected sales gain. If a merchant can potentially bring high revenue r, we want to avoid missing that opportunity. If outreach has cost c, we want to avoid overspending on low-value leads. A deep neural network can integrate a custom objective:
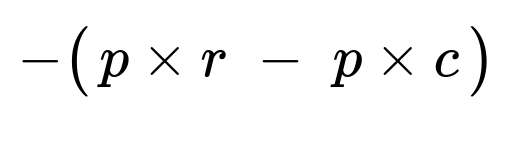
p is the output of the neural network. A higher p means the model suggests outreach. When p is high, the expected payoff is p * r - p * c, which is p(r - c). Multiplying by -1 transforms it into a loss. This penalizes missing large deals more heavily, because ignoring a potentially big sale yields no gain. It also accounts for cost so that the model does not suggest outreach when expected profits are slim.
Model Architecture
A feedforward neural network with several hidden layers handles categorical and numerical inputs. Input features include merchant attributes, transaction history, prior product usage, and more. The final output layer has a single unit with a sigmoid activation for p. Use backpropagation to minimize the custom loss.
Training Details
Prepare training data with each merchant’s historical behavior. Label those who adopted the product (label = 1) or not (label = 0), along with each merchant’s potential sales r (estimated from past transaction volumes or business size) and outreach cost c. Define the optimizer (Adam or similar). Replace the standard binary cross-entropy with the new custom function. Monitor convergence and verify stability by looking at how predicted probabilities concentrate around high-value, low-cost leads.
Evaluation
Use a holdout set and compare the total predicted gains with the cost-adjusted metric. Measure how many high-value deals were correctly reached. Compare to a baseline classifier trained under standard cross-entropy. Expect that the new model might have slightly lower recall for all potential positives but substantially higher overall revenue.
Implementation Example in Python
import torch
import torch.nn as nn
import torch.optim as optim
class CrossSellModel(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(CrossSellModel, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, 1)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.sigmoid(self.fc3(x))
return x
def custom_loss(pred, target, revenue, cost):
# pred: predicted probability p
# target: true label y (0 or 1)
# revenue: potential sales r for each merchant
# cost: outreach cost c for each merchant
# Loss = - [ p(r - c) ] in a batch sense
# Negative sign to turn it into a minimization objective
expected_gain = pred * (revenue - cost)
return -torch.mean(expected_gain)
# Example usage
model = CrossSellModel(input_dim=20, hidden_dim=64)
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(num_epochs):
for batch_x, batch_y, batch_r, batch_c in train_loader:
optimizer.zero_grad()
outputs = model(batch_x)
loss = custom_loss(outputs, batch_y, batch_r, batch_c)
loss.backward()
optimizer.step()
Network size, optimizer choice, and hyperparameters depend on the dataset scale and complexity. Proper regularization and hyperparameter tuning can significantly impact performance.
Possible Follow-up Questions
How do you handle the risk of oversampling high-value merchants at the expense of mid-tier ones?
Look at performance across multiple customer segments. We can impose constraints to ensure a minimum coverage for mid-tier merchants or weight the loss function to reflect strategic goals. Another approach is imposing a cost budget in the objective, so the model does not over-allocate outreach just because of a few extreme high-value cases.
What if a merchant is predicted to have high sales potential but a very low probability of deal acceptance?
Setting p high for that merchant is not beneficial if the outreach probability of success is too small to offset the cost. The custom loss function helps because it multiplies revenue by p. If p is small, the expected payoff is small, so the network lowers the chance of outreach for that merchant.
How can you handle class imbalance in the training data?
Class imbalance usually requires techniques like oversampling positives or undersampling negatives, or using class weights. In this scenario, positives are not uniform. We can weight each sample by its potential revenue or cost to reflect its relative importance. This aligns with the custom loss approach, making each training point matter in proportion to its economic impact.
How do you validate that the new model outperforms a standard classification approach?
Compare the total revenue captured when contacting the top predicted merchants at a given coverage rate. Measure actual conversions to see if predicted high-value leads translate to higher total sales. Track conversion rates, profit, and recall. Use an unbiased holdout group or A/B test for real-world validation.
What if your custom loss leads to lower recall, yet higher total profit?
That trade-off might be acceptable if the business goal is maximizing overall profits. Traditional recall tries to detect as many positive responders as possible, but not all positives have the same economic value. The custom loss focuses on dollars rather than pure counts. Lower recall might be acceptable if it brings a larger net return.
How can this framework extend to fraud detection?
Consider cost from false declines (lost legitimate transactions) and cost from fraud losses. The custom loss can incorporate the monetary impact of each transaction. Denying a fraudulent transaction saves a potential loss but denying a good transaction hurts customer experience and business revenue. A custom function balancing those costs yields a more business-aligned fraud model.
When would you still prefer binary cross-entropy?
If the main objective is simply distinguishing positives from negatives without differing economic values, standard cross-entropy is efficient. It is straightforward, well-optimized in most libraries, and does not require custom code. If the stakes for each classification are the same, standard cross-entropy is enough.
No additional statements beyond this point.