
ML Case-study Interview Question: Natural Language to SQL with Vector Embeddings and LLMs for Large Warehouses.


Browse all the ML Case-Studies here.
Case-Study question
You are given a large data warehouse with hundreds of thousands of tables, and users who write SQL queries on a daily basis for analytics. The challenge is helping these users quickly transform their natural language questions into correct, optimized SQL queries. Users often do not know which tables to query. Propose a system that takes a plain-text analytical question as input, then finds the best tables to use, and generates a valid SQL query. Explain how you would design each system component (including table retrieval, prompt construction, and SQL generation). Propose how you would handle edge cases like missing table documentation or large schemas. Show how you would evaluate your solution for accuracy and performance.
Detailed Solution
Overall Architecture
Implement a multi-stage pipeline. First, retrieve relevant tables using a vector-based search on table embeddings. Next, confirm or revise the suggested tables. Finally, generate the SQL query with an LLM, passing the user question plus the table schemas in the prompt.
Table Retrieval with Vector Embeddings
Create an offline job that summarizes each table and stores embeddings in a vector index. Summaries describe the table contents, typical usage patterns, and schema details. When a user poses a question, convert it into embeddings and run a similarity search in the index. Give heavier weight to textual metadata and apply a scoring strategy to rank tables.
When computing similarity between the query vector q and table vector t, a common approach is cosine similarity:
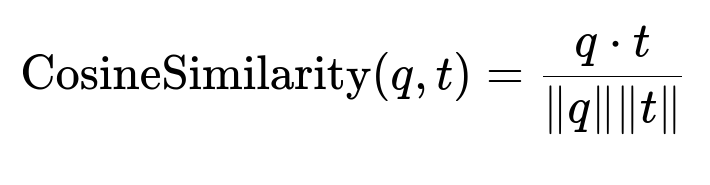
q and t are high-dimensional embeddings. q . t represents the dot product. |q| and |t| are the Euclidean norms.
After retrieving the top tables, re-check them using an LLM prompt that includes the table summaries and the user’s question. Include the best few tables in the final selection.
SQL Generation
Gather table schemas, including column names and data types. Include low-cardinality column values so that the model does not produce incorrect filter conditions (for example, using "web" instead of the actual "WEB"). Prompt the LLM with the question plus the confirmed table schemas and ask it to produce SQL for a specific SQL dialect. Return the result as a streaming response to avoid making the user wait for a fully formed result.
Metadata and Index Maintenance
Maintain the vector index with scheduled or on-demand updates whenever new tables or queries are created. Summarize fresh tables and queries, then generate embeddings and add them to the index.
Validation
Return the generated SQL directly to the user or optionally run a quick syntax check before that. If advanced checks are needed, consider a constrained beam search or a separate layer that tests whether each table and column exists. Surface any failures or ambiguous columns to the user for correction.
Observed Benefits
Many data users complete SQL tasks faster by skipping manual table discovery and direct query writing. Acceptance rates rise once they become more familiar with the feature. Productivity gains can be measured with controlled experiments, such as time-to-completion comparisons.
Next Improvements
Add real-time updates to the index to accommodate newly added tables. Enhance scoring to weigh domain-specific tags. Implement an interface for user feedback on both table suggestions and query correctness.
Possible Follow-Up Questions
1) How do you measure the success of a text-to-SQL system in production?
Success can be measured by user acceptance rate of generated queries, time saved per query, and accuracy of final SQL. Track how often users submit queries with minimal modifications and how quickly they complete tasks. Compare groups with and without text-to-SQL assistance to quantify improvements in efficiency. Log error rates (such as syntax errors or incorrect results) and check how often users override table suggestions.
2) Why is it important to combine table retrieval with user confirmation before SQL generation?
Table retrieval alone might propose tables that only partially match the user’s intention, especially with vague questions or insufficient metadata. User confirmation ensures you avoid generating SQL based on irrelevant or incomplete tables. This step also reduces hallucinations where an LLM references columns that do not exist.
3) How would you handle tables that have no documentation?
If a table has no documentation, you can derive partial metadata from its column names and from any queries that have used it in the past. Summaries can be constructed by extracting typical joins or filter conditions from sample queries. If the table truly lacks context, the retrieval process might rely on column name similarity alone, potentially ranking it lower unless it strongly matches the user’s query terms.
4) Why is column pruning important in this design?
Including every column for extremely wide tables can exceed LLM context windows. Pruning removes columns that are rarely used or flagged as less relevant. This keeps prompts manageable and avoids pushing crucial details out of the LLM’s context window. Pruning is guided by metadata tags or usage frequency in historical queries.
5) What if the LLM produces a WHERE clause that references invalid field values?
To mitigate that, feed low-cardinality column values into the prompt so the LLM knows the actual possible values. If the user tries to filter on a value not in that set, the system can either auto-correct or flag it. If mistakes persist, add query validation to reject or fix ill-formed conditions.
6) What techniques could be used to further validate generated queries?
A syntax check ensures the query is parseable. A constraints check ensures references to columns, tables, or enumerated column values are valid. A limited query-run in a safe environment might confirm the query compiles and returns results. Constrained beam search is another strategy, where only valid tokens and table references are allowed.
7) How would you prioritize adding metadata or tags to tables?
Focus on high-usage tables first, since improving metadata for frequently queried datasets yields the biggest impact. Capture domain ownership, typical query patterns, data refresh intervals, and user feedback. Store these as structured tags so that your retrieval engine can leverage them.
8) What trade-offs appear when deciding how many tables to pass to the LLM?
Passing more tables can help if the user question might relate to rarely used tables. But overloading the prompt with many tables risks overshadowing relevant schema details. Prompt length can impact cost and latency. If the user’s question typically matches only a small subset of high-tier tables, it is better to keep the set limited.
9) How would you implement user feedback for continuous improvement?
Give the user a quick mechanism to confirm or reject suggested tables and to rate the final SQL query. Store these signals and re-run offline processes to update embeddings or fine-tune future retrieval. Increase table ranking for those with positive feedback and lower ranking for repeated negative feedback. Data can also guide which columns are critical to include in the prompt.
10) How do you ensure your system’s architecture remains extensible for future updates?
Separate the core retrieval logic, the summarization component, and the LLM prompting. Keep embeddings in a modular store so you can swap models or scoring strategies. Allow flexible prompt templates so you can easily adapt to new LLMs or additional context fields. This design approach avoids tying the entire pipeline to a single embedding model or LLM provider.