
ML Case-study Interview Question: Automated Floor Plan Generation using Object Detection on 360° Indoor Panoramas.


Browse all the ML Case-Studies here.
Case-Study question
You have access to a stream of indoor 360-degree panoramas of residential rooms. Your goal is to generate a 2D floor plan for each home, showing walls, doors, windows, and openings. You need a method to detect and localize windows, doors, and openings using bounding boxes on these 360 panoramas. These bounding boxes will then be projected onto the floor plan. The panoramas are leveled and presented through equirectangular projection, so vertical lines remain vertical. The bounding box widths (left and right edges) must be precise, but top and bottom edges can be looser because of horizontal distortions.
You must define how to collect and label data, how to decide on the bounding box annotations, and how to handle open or closed doors. You must outline your architecture choice for object detection: either (1) extracting perspective crops and running a standard object detector or (2) directly training the detector on full 360 equirectangular images. You must also propose a method to measure success, including which metrics to track, and how you would verify that the model’s performance meets or surpasses an acceptable threshold compared to human annotators.
Detailed Solution
Defining Classes and Annotation Strategy
The business objective is to place windows, doors, and openings onto a floor plan. The bounding boxes must align well with actual wall boundaries so that their bottom edge coincides with the floor plane. This requirement shapes how each class is defined. A door is any functional separation between two spaces that can be opened or closed. An opening is any door-like separation without an actual door or door frame. A window is any open wall space that cannot be crossed. These definitions avoid confusion about partial doors or whether a door is physically present. Human labelers often disagree on ambiguous cases (like shower doors or mirrored walls), so clear instructions are crucial. The team reviews many sample images, highlights corner cases, and documents these guidelines. Frequent communication with labelers fosters consistent annotations.
Data Collection
The primary data source is a set of leveled, 360-degree indoor panoramas. Each image is stored in an equirectangular projection, which can show distortions near the edges. The annotated bounding boxes capture the left and right boundaries carefully. The top and bottom edges are looser because major wall boundaries are determined by the left and right edges intersecting the floor plane.
Two Possible Detection Approaches
One route (Route 1) uses perspective crops. Each panoramic image is split into multiple smaller segments with a standard field of view. These segments feed into a conventional object detector, such as a Single Shot Multibox Detector (SSD) or Faster R-CNN, which is accustomed to nondistorted images. The bounding boxes are then fused back onto the full panorama. This can be effective but adds more steps and increases inference time, since each panorama must be broken into many cropped images.
Another route (Route 2) trains the detector directly on the panoramic image. One approach ignores spherical geometry and simply treats the equirectangular image as “flat.” Another approach modifies the convolution layers to account for spherical distortion. Since most modern networks can learn to handle moderate distortion when trained with enough data, the simplest sub-route is to feed the equirectangular image to an off-the-shelf detector like Faster R-CNN without altering its architecture.
Model Training
Training includes standard data augmentation (random horizontal flips, brightness adjustments, etc.). If using perspective crops, training is straightforward because standard object detection tools expect conventional images. If training directly on panoramas, the bounding boxes must be carefully mapped into the equirectangular coordinate system.
A Faster R-CNN or SSD pipeline is typically set up with a base convolutional backbone (such as ResNet) pre-trained on large datasets. The final detection layer is fine-tuned on labeled 360 panoramas. The system learns to predict bounding boxes for doors, windows, or openings.
Model Evaluation
Average Precision (AP) is the primary success metric, which integrates precision and recall across multiple confidence thresholds. The PASCAL VOC style AP can be expressed as:
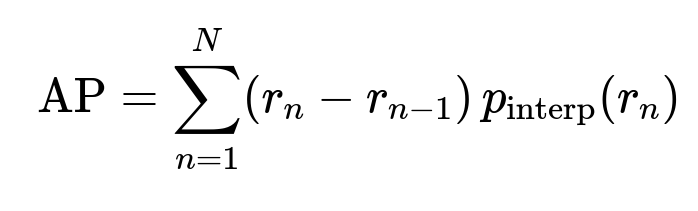
where r_n is the recall at the nth threshold, r_{n-1} is the recall at the previous threshold, p_interp(r_n) is the interpolated precision at recall r_n, and N is the number of sampled points on the precision-recall curve.
Human-level performance sets a practical upper bound. Even trained labelers make mistakes or disagree on ambiguous scenes. Evaluating each annotator against a “ground-truth” reference reveals that perfect precision or recall is rarely achieved. Models can then be compared to the inter-annotator scores to see if the model’s AP is approaching human consistency.
Inference and Pipeline Integration
After obtaining bounding boxes, the left and right edges are intersected with the floor plane to localize the WDO positions. This mapping populates the floor plan with window, door, and opening placements. The entire pipeline, from loading images to generating final bounding boxes, can be deployed on a cloud platform or an on-premise server. Faster R-CNN often yields higher accuracy, while SSD can achieve lower latency. The decision depends on business constraints.
Follow-Up Questions
1) How would you refine your annotation definitions to handle partial occlusions or mirrored objects?
Occlusions and mirror reflections can produce ambiguous bounding boxes. Some labelers include mirrored windows or partial frames hidden behind furniture. Others might ignore them. Standardize the approach by defining a rule for partial objects (e.g., label occluded objects if at least 30% is visible). Mirrors should not be labeled unless they reveal the full geometry of a second window or door, which typically they do not.
2) Why can human-level performance be important, and how do you establish a ground-truth reference?
Human-level performance is a practical yardstick that reveals the noise floor in annotations. Compare multiple annotators on the same image set. Designate one annotation set as the reference. Compute precision and recall for the others. The resulting inter-annotator agreement defines a realistic upper limit.
3) What are the trade-offs of the perspective crop approach (Route 1) versus the direct panorama approach (Route 2)?
Route 1 can reduce distortion, making the training phase more stable if the detector is built for standard images. However, it creates extra overhead: each panorama is split, processed, then re-fused. Route 2 is simpler at inference time and leverages the model’s capacity to learn distortions from data, though it can be trickier if the panoramic distortions are extreme or the dataset is small. A large, well-annotated dataset can tip the balance toward direct panorama training.
4) What factors do you consider when choosing a one-stage model (SSD) vs. a two-stage model (Faster R-CNN)?
One-stage detectors run quickly and have simpler pipelines, which can be vital for real-time or large-scale inference. Two-stage detectors often produce more accurate bounding boxes and class predictions but are slower. Business goals determine which trade-off is acceptable. If pinpointing bounding-box edges precisely is critical, a two-stage approach might be better.
5) How would you handle ambiguous bounding boxes at the boundary of the equirectangular image?
In an equirectangular projection, pixels at the far left and right edges actually wrap around to the same real-world boundary. Either replicate a small slice at the edges for training or keep boxes that straddle the boundary as a single detection with a wrap-around coordinate system. This ensures that windows or doors near the seam are handled consistently.
6) How would you adapt your solution if you needed to distinguish exterior doors/windows from interior ones?
Add a second classification stage or a specialized attribute classifier. Label each bounding box as interior or exterior if that data is available. Possibly incorporate sensor data (GPS or known home geometry) to guess if a door or window is on an outer wall. Provide consistent labels during training and feed that information back into the floor plan generation.
7) How do you maintain consistent labeling guidelines across large annotation teams in a fast-paced environment?
Provide a rulebook with explicit examples. Conduct frequent reviews and clarifications, especially early on. Create a shared communication channel for edge cases. Periodically audit annotations by randomly sampling the labeled data. Use feedback loops to correct or refine ambiguous guidelines.