
ML Case-study Interview Question: LLM & Knowledge Graph Enhanced Search for Complex Attribute Queries.


Browse all the ML Case-Studies here.
Case-Study question
A large online platform serves users searching for various items in retail and food categories. The platform’s existing system uses a combination of keyword-based retrieval and embedding-based approaches, but faces challenges when users enter complex queries with multiple attributes (like “vegan chicken sandwich” or “small no-milk vanilla ice cream”). The system sometimes fails to retrieve the correct items due to incomplete query understanding and difficulty enforcing crucial must-have attributes (such as dietary restrictions). The platform’s knowledge graph contains metadata for items (attributes like product category, flavor, dietary preferences) that could improve retrieval precision. Design a solution to overhaul the entire query-processing pipeline to ensure users get precise search results. Suggest how to use large language models for query segmentation and entity linking, incorporate the knowledge graph, handle potential model hallucinations, balance recall and precision, and measure success.
Proposed in-depth solution
A large language model (LLM) can parse queries into meaningful chunks and map those chunks to the knowledge graph’s vocabulary. The system tags attributes like dietary preferences or flavors so the retrieval engine knows which attributes must be included. This avoids retrieving items that only partially match important constraints.
Query segmentation with LLM
Segment the query into interpretable parts. Provide the LLM with a prompt that includes the taxonomy structure. Enforce controlled outputs by restricting potential segments to known taxonomy fields. For “small no-milk vanilla ice cream,” map “small” to Quantity, “no-milk” to Dietary_Preference, “vanilla” to Flavor, and “ice cream” to Product_Category. This ensures the LLM remains consistent with real metadata fields.
Entity linking
Use approximate nearest neighbor (ANN) search to retrieve candidate entities from the knowledge graph for each query segment. Present the LLM with these candidates so it selects the correct concept rather than inventing a label. “no-milk” is mapped to “dairy-free,” for example. This method reduces hallucinations by keeping the output within known concepts.
Hybrid retrieval
Combine keyword-based retrieval for exact matches with embedding-based retrieval for semantic matches. Enforce must-have attributes such as dietary restrictions. The system forms a structured query that states: must contain “Dairy-Free” attribute, should have “Vanilla” flavor, and product category = “Ice cream.” Items satisfying must-haves rank higher. Items missing optional attributes may still appear, but lower in rank.
Embedding retrieval scoring
Compute similarity with the text embeddings of query and document. A common measure:
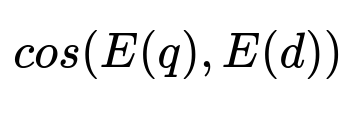
q represents the query, d represents the document, E() represents the embedding function. The cosine similarity returns a high score for documents semantically similar to the query.
Use these scores as part of the ranking pipeline, blended with keyword matching signals.
Handling hallucinations
Apply post-processing steps. Validate that the mapped entity actually exists in the knowledge graph. If the LLM’s output is invalid, drop or correct it by fallback logic or a simpler rule-based approach. Periodically audit a batch of results with human annotations to measure precision and refine prompts.
Balancing memorization and generalization
Batch processing queries with LLMs can be precise, but it does not scale well. Real-time inference must handle novel or long-tail queries. Use a hybrid solution: precompute segmentations for frequent queries, fall back to embedding-based or rule-based systems for unseen queries. This combination ensures coverage across the entire query space.
Integration with rankers
Make new attributes available to rankers. Retrain rankers with more precise user-engagement data. As retrieval improves, user clicks and orders increase. Updated training data reflect these behavioral changes, further improving ranking performance.
Measurement
Track metrics like whole-page relevance (WPR), which represents overall relevance of retrieved items, same-day conversions, and user engagement. Compare to baseline retrieval. If attribute-based searches show higher engagement and conversion, consider it a success. Reassess regularly with A/B tests.
Example code snippet for ANN-based entity linking explanation
import faiss
import numpy as np
# Suppose 'concept_embeddings' is a numpy array [num_concepts x embedding_dim]
# 'query_embedding' is the embedding for our query segment
index = faiss.IndexFlatIP(embedding_dim) # Inner product index
index.add(concept_embeddings)
# Retrieve top_k candidates
scores, ids = index.search(query_embedding.reshape(1, -1), top_k)
# 'ids' now contains the nearest taxonomy concepts.
# LLM picks the best among these based on the context.
Explain to the interviewer that each query segment is embedded, candidates are retrieved, and the LLM decides which concept best matches user intent.
What if the model segments a query incorrectly?
Use a fallback. For instance, if the LLM misidentifies “cranberry sauce” as “cranberry” + “sauce” when we need them combined, rerun the segmentation with a different prompt. Or apply heuristic checks to see if splitting a phrase breaks known collocations in the taxonomy.
How do you ensure must-have attributes are respected in retrieval?
Make must-have attributes part of a Boolean “must” clause. For example, if the user specifies a dietary restriction, items lacking that restriction attribute are excluded. Flavors or optional keywords can remain as “should” clauses, allowing partial matches.
Why is a hybrid approach better than pure LLM or pure keyword-based retrieval?
Pure LLM may hallucinate or fail on new queries. Pure keyword-based retrieval misses semantic meaning. Combining them allows robust coverage, ensuring that crucial constraints are met while still capturing items with semantically related descriptors.
How do you decide on the ranking scores for final ordering?
Use learned rankers that incorporate both textual similarity (like cos(E(q), E(d))) and user feedback signals (clicks, orders). Weight each factor, train on historical user interaction data, and compare performance through A/B testing.
How do you handle stale data in the knowledge graph?
Regularly re-ingest new items or attributes. Maintain incremental updates so that changes to the product catalog reflect quickly in the index. Retrain embeddings if distribution shifts in naming or product offerings occur.
How do you detect and fix LLM hallucinations for rare queries?
Log the queries flagged by heuristics or user feedback. Inspect them manually. If the LLM mapped them to non-existent entities, refine the prompt with stricter instructions or add them to a domain-specific lexicon so the LLM is guided by known references.
How would you adapt this pipeline to multiple languages?
Extend the taxonomy with multilingual labels. Train or fine-tune an LLM that understands multiple languages. Generate embeddings in a language-agnostic way. Restrict entity linking outputs to valid translations in the knowledge graph.
What if you must re-rank results in real-time for large volumes of queries?
Distribute the ranker across multiple nodes. Use approximate methods for embedding search and maintain efficient caching. If the system architecture supports microservices, isolate the embedding-based retrieval and ranking into separate services that scale horizontally.
Use these principles to build a robust retrieval pipeline that comprehensively segments queries, links them to known attributes, and enforces critical constraints.