
ML Case-study Interview Question: Retail Autocomplete: Multi-Objective Ranking and Semantic Matching for Enhanced Product Search


Browse all the ML Case-Studies here.
Case-Study question
A large online retail Company wants to build a machine learning-driven autocomplete system for its product search. They must handle user input prefix matching, correct common misspellings, boost popular and high-converting queries, and guide users to explore more products. They have a vast product catalog from multiple partner retailers. Some retailers are new or small, and they see a cold start problem. The Company seeks a solution that ranks autocomplete suggestions in a way that drives user engagement and maximizes cart additions, while also ensuring low latency. Explain your approach for end-to-end design, covering data collection, filtering, semantically deduplicating queries, handling new retailers with limited traffic, and building a multi-objective ranking algorithm for relevance and cart additions. Propose specific strategies, code snippets, and best practices for large-scale production deployment.
Detailed solution
Data Collection and Preparation
Historical logs of past user searches are used to build a corpus of candidate autocomplete terms. Lower-traffic searches are filtered. Offensive terms and words not relevant to the Company’s domain are removed. Out-of-vocabulary terms are removed, and duplicate forms like “egg” and “eggs” are consolidated into the most popular version. The result is a robust set of candidate query suggestions.
Fuzzy Matching for Typos
Users often type misspelled prefixes. Misspelled queries like “avacado” can still result in successful conversions for “avocado.” A fuzzy matching approach returns suggestions with a small edit distance from the user’s prefix. A discount factor is applied for approximate matches so that a correctly spelled candidate with high organic popularity outranks the misspelled candidate.
Semantic Deduplication
Semantic duplicates such as “fresh bananas” and “bananas fresh” appear when they share nearly the same meaning. Pre-trained query embeddings identify duplicates by comparing vector similarity. Terms with a similarity score above a threshold are merged, keeping the higher-traffic candidate. This reduces clutter and boosts variety in top results.
Cold Start Handling
Smaller or new retailers can lack sufficient query traffic. A standardized central catalog is used to generate query suggestions shared across retailers. Users at a new retailer searching for “bananas” still see that query, even if the retailer traffic is low, because “bananas” is in the unified catalog. This approach increases coverage for stores with sparse logs.
Ranking Model
Initial ranking by query popularity is quick but ignores contextual features. A lightweight classification model is trained on autocomplete impressions. Positive examples are suggestions that were clicked, and negative examples are skipped suggestions. The model includes features like prefix-match patterns, skip rate, presence of a thumbnail, and fuzzy match indicators.
Multi-Objective Ranking
Driving cart additions becomes critical. A model for add-to-cart probability is combined with the autocomplete click probability. The ranking function orders suggestions to maximize engagement and subsequent conversions.
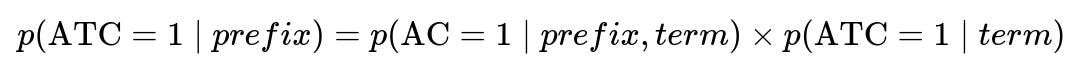
p(ATC=1 | prefix) is the overall probability of a cart addition given the user’s current prefix. p(AC=1 | prefix, term) is the probability that the user clicks on the suggested term for that prefix. p(ATC=1 | term) is the probability of a cart addition given that search term.
The combined model re-ranks suggestions based on the product of these probabilities, adjusting for any independence assumptions.
Example Python Snippet for Ranking
import numpy as np
def rank_suggestions(prefix, candidate_terms, ac_model, atc_model):
# ac_model(prefix, term) -> probability of autocomplete click
# atc_model(term) -> probability of add-to-cart
ranked = []
for term in candidate_terms:
p_ac = ac_model(prefix, term)
p_atc = atc_model(term)
score = p_ac * p_atc
ranked.append((term, score))
ranked.sort(key=lambda x: x[1], reverse=True)
return [term for term, _ in ranked]
This simple approach merges the two objectives into a single ranking score.
Latency Considerations
Autocomplete must be fast. Precomputed features are stored in low-latency data stores. Feature extraction is done offline. Models are optimized for minimal overhead. The final inference pipeline is designed to scale efficiently under high concurrency.
What if the interviewer asks:
How to measure the effectiveness of the autocomplete system?
Measuring effectiveness involves tracking autocomplete click-through rate, average prefix length, user conversion rate, and gross transaction value. A high autocomplete click-through means relevant suggestions. A low average prefix length implies users type less. A higher user conversion rate reflects more successful searches. Gross transaction value indicates overall business impact.
Why not only rely on popularity-based ranking?
Popularity-based ranking displays frequently typed queries but might ignore user context and lead to mismatched suggestions. This fails to surface long-tail queries or personalized needs. Popular terms also might not always yield high conversions. A multi-objective ranking balances popularity, relevance, and add-to-cart probability.
How to handle synonyms and overlapping words?
Query embedding similarity scores or domain-specific ontologies can detect synonyms like “mayo” and “mayonnaise.” Similarities beyond exact string matches ensure the system captures intent. The Company merges terms with high overlap to reduce redundancy. This helps the user see a succinct set of suggestions.
What if the user’s prefix is ambiguous?
A minimal set of high-probability matches appears. The model decides which suggestions best match the user’s historical behavior and broader popularity. Fuzzy and semantic signals are used to handle ambiguous prefixes like “appl,” which may match “apple,” “appliances,” and “apple sauce.” Scoring and partial matching thresholds help narrow down the top suggestions.
Can personalization improve results?
Yes. Personalization can re-rank suggestions based on a user’s search history, most frequently bought items, local shopping trends, or current cart items. This approach further refines the multi-objective ranking model to maximize user satisfaction and business metrics.
How to maintain low-latency performance?
Trie-based prefix matching or efficient data structures quickly retrieve candidate terms. Caching frequent results is key. Precomputed similarity lookups accelerate fuzzy matching. Lightweight inference is implemented, potentially using compact gradient-boosted trees or simplified neural networks. Auto-scaling ensures no overload.
How to extend this approach to new languages or locales?
A multilingual search pipeline is needed. The system trains separate embeddings and tokenizers for each language. The filtering steps are repeated for each target language. The cold start strategy still applies, but the shared catalog becomes language-specific. Synonym detection uses local language knowledge bases. Ranking features remain similar but adapt to the local user base.
Could re-ranking conflict with brand partnerships or sponsored listings?
Sponsored listings might override certain ranks. The multi-objective model can incorporate an additional factor for sponsored terms. The system places them strategically without undermining user satisfaction and engagement. Weighted scoring or business rules ensure brand objectives remain balanced with user relevance.
How to update these models regularly?
The pipeline refreshes offline features daily or weekly. Real-time logs continually feed into data stores. The Company sets up periodic retraining, validating metrics like recall, precision, and overall cart additions. A reliable CI/CD pipeline manages versioning and rollback if a new model worsens metrics.
How to ensure no duplication of results in production?
Semantic deduplication merges near-identical terms. The system might store synonyms and canonical forms. The final ranking step filters out duplicates again, keeping the highest-ranked version. Logging and incremental updates keep the index clean over time.
How to handle seasonal spikes or trending items?
A trending or seasonal factor can boost queries like “pumpkin spice” during fall or “chocolate bunnies” before certain holidays. Time-decay weighting tracks queries that spike. The multi-objective model includes a trending score that decays when interest subsides.
How to validate offline metrics versus live performance?
Offline experiments compute metrics like recall and MRR (Mean Reciprocal Rank). Online experimentation through A/B tests compares key performance indicators. The system is updated based on real-world user interactions. Both phases are critical for robust evaluation.
How to integrate partial personalization without fully changing the ranking pipeline?
A hybrid approach merges global ranking signals with user-specific re-ranking. The base model produces a broad set of suggestions. A separate lightweight model or rule-based approach reorders them based on personal factors like user history, location, or time. This keeps the system modular and easier to maintain.