
ML Case-study Interview Question: Unified Real-Time Recommendations Using Sequence Modeling and Temporally-Masked Encoders


Browse all the ML Case-Studies here.
Case-Study question
You work at a subscription-based online retailer that recommends items to clients worldwide. The system currently has different models for different regions and product lines. These models are trained separately, with many ad hoc features that are only relevant for one region or product line. The maintenance load is high, and improvements in one model do not easily transfer to other regions or lines. You need a single sequence-based model that captures changing client preferences over time, uses the same unified representation across all lines, and instantly adapts to new events. How would you build this unified system to generate purchase probability scores for any item from any product line and region, ensuring real-time updates and accurate predictions?
Proposed Detailed Solution
The model maintains an evolving client state in the form of a hidden embedding. The item side is captured by an embedding that depends on raw item features. Each new client interaction (for instance, a purchase or profile update) arrives as a timestamped event that refines the client state. The inference step uses the client’s latest hidden embedding and the item embedding to generate the probability of a purchase. A gating mechanism adds recurrent behavior, while a specialized encoder structure processes batches of events in parallel. Data from multiple channels are fed into the same client embedding to ensure a single model can handle many regions and lines. The approach avoids complex feature engineering because raw features can be passed in as events, which ensures updates appear instantly in recommendations.
Time-Safe Sequence Processing
Each client interaction is treated as an update. The model is time-safe because it processes events in chronological order, so future updates cannot influence earlier states. The model uses a Temporally-Masked Encoder (TME) that performs a weighted aggregation of batch updates in a triangular (strictly backward) fashion. The aggregator output, combined with a recurrent gating scheme, updates the client embedding. The gating scheme resembles a Gated Recurrent Unit (GRU) approach, which helps manage state transitions. The TME’s design improves parallelization compared to a standard Transformer while retaining many benefits of attention-based weighting.
Client Embedding
A single client embedding is learned. It captures the entire range of shopping contexts for that client. In practice, the model learns a separate feed-forward transformation of this client embedding for each specific domain (such as “Fix-like purchase scenario” vs. “direct shopping scenario”), if needed. This allows a single unified representation without losing domain specificity.
Item Embedding
Items are embedded through an EmbeddingBag approach that sums learned vectors for each raw item feature (for example, brand category, color code, style label). This technique allows quick generalization to new items because it reuses known feature embeddings. The same item embedding is applied across all domains.
Multi-Target Outputs
Multiple targets (such as “probability of purchase in a subscription box” or “probability of purchase when directly listed on a website”) are trained in one model by comparing predicted probabilities to actual outcomes using a chosen loss function, often binary cross entropy. Each target uses the latest client embedding and the relevant item embedding at the time of the event.
Instant Updates
When new interactions occur, a lightweight update pipeline generates a small number of embeddings from the raw event data. The sequence-based framework folds in these events to refresh the client state. This ensures immediate reflection of client feedback in every recommendation channel.
Core Formula for Probability of Purchase
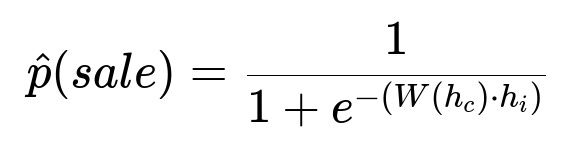
Here, h_{c} is the current client hidden embedding, h_{i} is the item embedding, W is a learned feed-forward mapping from the client state to the item embedding space, and “·” denotes the dot product. The logistic (expit) function transforms the dot product of the mapped client embedding and the item embedding into a probability.
Example Code Snippet
A simplified training loop in Python might begin by processing a batch of events in chronological order, embedding them, and passing them to a TME block. Each processed event then uses a GRU-like update to modify the client hidden state. The final line might compute purchase probability for a target event:
import torch
import torch.nn as nn
class TemporallyMaskedEncoder(nn.Module):
def __init__(self, input_dim, hidden_dim):
super().__init__()
self.feedforward = nn.Sequential(
nn.Linear(input_dim + hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
def forward(self, updates, client_state):
# updates shape: (batch_size, max_events, input_dim)
# client_state shape: (batch_size, hidden_dim)
# Example forward pass: concatenation + feed-forward
# Return processed_updates and attention_weights
pass
class ClientStateModel(nn.Module):
def __init__(self, hidden_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.encoder = TemporallyMaskedEncoder(input_dim=64, hidden_dim=hidden_dim)
self.gating = nn.GRUCell(hidden_dim, hidden_dim)
self.prediction_head = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1)
)
def forward(self, updates, initial_state):
# Pass updates to TME, then recurrently update the state
processed_updates, weights = self.encoder(updates, initial_state)
new_state = self.gating(processed_updates, initial_state)
return new_state
def predict_purchase(self, client_state, item_embedding):
# Dot product after feed-forward on client_state
transformed_state = self.prediction_head[:-1](client_state)
logits = (transformed_state * item_embedding).sum(dim=1, keepdim=True)
return torch.sigmoid(logits)
Updates pass into the TemporallyMaskedEncoder, which returns processed updates for each event plus attention weights. The Gated Recurrent Unit cell merges the previous client state with the new information. The final state feeds into a feed-forward head for item scoring.
Follow-Up Question: How to Handle Missing Updates or Sparse Events?
Any client with fewer updates still has a hidden embedding. Early in training, the model receives fewer events for that client. The TME gracefully handles sparse sequences by applying time masking, so no future event information seeps backward. The gating mechanism can keep the client state stable if no new updates arrive.
Follow-Up Question: Why Not Use a Standard Transformer Instead of the Temporally-Masked Encoder?
Standard Transformers compute attention over every token for each token. This can become slow for large sequences. The Temporally-Masked Encoder computes a single set of attention weights and then applies a triangular mask, which reduces computation and enforces a strict backward look. This approach trains faster and yielded better performance in tests. The partial parallelization is preserved, so it runs more efficiently than a fully recurrent method.
Follow-Up Question: How to Ensure Real-Time Inference?
Only new events that happened since the last model training need encoding. The TME does not require reprocessing the entire client history from scratch. Real-time inference pipelines embed the few new interactions, update the client state, and retrieve a recommendation. This keeps inference fast, even for clients with long histories.
Follow-Up Question: How to Scale Across Regions and Product Lines?
A single model architecture covers all regions and product lines because the client and item embeddings accommodate region-specific signals in the same hidden space. The only difference is the domain-specific transformations that map the client state to the correct prediction context. This eliminates separate model forks for each new business scenario. The system reuses any learned feature embeddings across domains.
Follow-Up Question: How to Validate the Model’s Effectiveness?
Run region-by-region and line-by-line holdout sets. Evaluate metrics such as Key Performance Index (KPI) lifts, purchase rates, user retention, and average order size. A/B test the new model in production across different regions, compare the results with legacy models, and check for consistent improvement. Watch resource usage in training and inference clusters to confirm reduced maintenance costs.
Follow-Up Question: How to Extend this Approach to Other Use Cases?
Define new target events for other desired outcomes, such as click probability on item images or churn probability. Add these events to the training pipeline as new labeled targets. The shared client embedding and item embedding remain the same, but the new target modules learn to map the shared hidden space to each outcome. This modular setup speeds up development of additional objectives without rewriting the entire system.