
ML Case-study Interview Question: End-to-End Deep Learning System for Real-Time E-commerce Product Ranking.


Browse all the ML Case-Studies here.
Case-Study question
A large e-commerce platform with millions of users seeks to improve its product ranking system to increase click-through rates and customer engagement. The team wants to design an end-to-end Machine Learning solution that ingests user interaction data, product metadata, and contextual information in real time. The goal is to produce highly relevant product rankings for each user. Senior Data Scientists are asked to propose a detailed approach that addresses data pipelines, feature engineering, model architecture, training strategies, evaluation metrics, and production deployment.
Proposed Solution
Building this ranking system requires careful handling of data flows, model development, and real-time deployment.
Data is sourced from user clicks, searches, and product attributes stored in distributed databases and streaming systems. Data passes through an ETL (Extract, Transform, Load) pipeline that unifies and cleans it. Engineers gather user behavior logs, session metadata, and historical click-through data. Transform steps include session segmentation and joining user events with product features.
Training data is created by extracting positive user signals (clicked or purchased items) and negative signals (impressions not clicked). This data is split into training, validation, and test sets by time windows to reduce data leakage.
Feature Engineering
Models learn user preference patterns from historical interaction sequences, user demographic attributes, and product metadata. Simple transformations produce numeric or categorical features. Complex transformations produce embedding vectors for textual attributes (such as product descriptions). These embeddings capture semantic relationships among items, leading to better representation.
Model Architecture
The solution uses a deep neural network for ranking. Training a neural network for binary classification often involves cross-entropy loss. The formula for cross-entropy loss is:
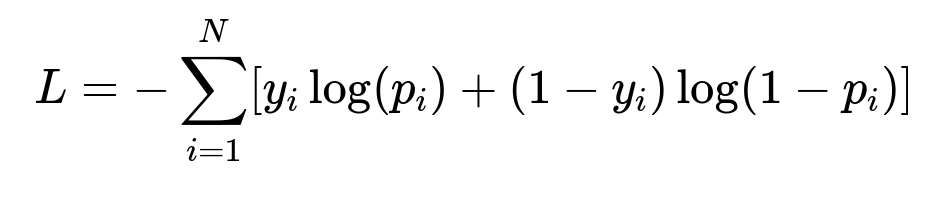
N is the total number of samples. y_i is the ground truth label indicating if the item was clicked for the i-th sample. p_i is the model's predicted probability of the item being clicked.
Layers in the network include embedding layers to handle sparse product categories and user attributes, dense layers for user behavioral statistics, and attention mechanisms to capture relevant items from recent sessions. Regularization uses dropout and batch normalization. Training uses gradient-based optimization with mini-batches.
Evaluation
Offline evaluation measures include AUC (Area Under the ROC Curve) and Precision@k. These metrics verify how well the model ranks clicked items over non-clicked ones. Online evaluation uses A/B tests to compare user engagement with the new model against existing systems, ensuring real gains in click-through rates and revenue.
Deployment
Serving the model requires low-latency inference. Engineers integrate a fast inference engine with a microservice that looks up user features in memory and runs neural network computations on optimized hardware. Monitoring collects metrics on response times, throughput, and user satisfaction. Continuous retraining is scheduled to keep the model updated.
Example Code Snippet
import tensorflow as tf
def create_model():
inputs = {
'user_id': tf.keras.Input(shape=(1,), dtype=tf.int32),
'product_features': tf.keras.Input(shape=(128,), dtype=tf.float32),
}
user_embed = tf.keras.layers.Embedding(input_dim=1000000, output_dim=32)(inputs['user_id'])
user_vec = tf.keras.layers.Flatten()(user_embed)
concatenated = tf.keras.layers.Concatenate()([user_vec, inputs['product_features']])
dense_1 = tf.keras.layers.Dense(64, activation='relu')(concatenated)
dropout_1 = tf.keras.layers.Dropout(0.2)(dense_1)
dense_2 = tf.keras.layers.Dense(32, activation='relu')(dropout_1)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(dense_2)
return tf.keras.Model(inputs=inputs, outputs=outputs)
model = create_model()
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['AUC'])
The code shows a simple neural network that merges user embeddings with product features. Extra transformations can be included for advanced feature combinations.
How would you ensure model stability and handle data drift?
Model stability relies on consistent data representations. Changes in input distributions can degrade performance. Continuous monitoring tracks input statistics for shifts. Whenever statistical drifts or changes in user behavior are detected, new data is sampled to retrain the model. Incremental training pipelines update parameters based on fresh data without fully retraining from scratch.
How do you tune hyperparameters and regularize the model?
Hyperparameters are adjusted using grid search or Bayesian optimization. Researchers test different learning rates, batch sizes, and neural architecture widths. Overfitting is mitigated by dropout, early stopping, and weight decay. Validation loss or validation AUC indicates whether the model generalizes. Large models sometimes need more dropout to prevent memorization of training examples.
Why do you need offline metrics and online A/B tests?
Offline metrics like AUC verify the model in a controlled setup, ensuring consistent performance gains. User behavior is complex. Live A/B tests capture dynamic interactions, platform constraints, and real-time feedback. Different user segments may respond differently to model changes, so online tests confirm genuine improvements in engagement and revenue.
How do you handle cold-start issues?
New users and products have little to no historical interaction. The model uses product metadata embeddings and basic user demographics or geolocation to approximate preferences. Item-based or user-based nearest-neighbor approaches can provide fallback recommendations. Models get more accurate after collecting a few interactions for each user or product.
How would you scale this system?
Scaling involves distributed computing, sharded data storage, and high-throughput inference pipelines. Training on large-scale data uses hardware accelerators (GPUs or TPUs). Offline data transformations run on cluster computing frameworks. Real-time predictions require load balancers and caching layers. Monitoring ensures stable throughput and fast response times.
What if new product categories appear?
Unseen categories raise issues during inference. Tokenization or hashing strategies can place unknown categories into a special bucket or extend the embedding layer dynamically if system constraints allow. Model retraining with updated vocabulary or category embeddings improves performance over time.
How do you handle interpretability?
Deep neural networks can be opaque. Techniques like SHAP or LIME approximate local feature contributions. Engineers interpret model outputs for compliance or user trust. Human-readable explanations are especially relevant in regulated domains.
How do you prove ROI to leadership?
Post-deployment analysis checks incremental gains in click-through rates, order values, or user retention. Financial metrics like incremental revenue or average basket size demonstrate tangible business improvements. Comparisons against baseline confirm if the costs of maintaining and upgrading the system are outweighed by increases in revenue or user engagement.
How do you integrate this pipeline within existing systems?
Engineers expose a REST or gRPC interface for model predictions, referencing feature stores for user context. Existing systems route user requests to this ranking service. Monitoring dashboards track latency and success rates in real time. Automated rollbacks revert to a previous stable model version if anomalies occur.
Final Thoughts
Applying advanced AI for product ranking involves robust data engineering, neural architectures, and real-world evaluation. Testing across offline metrics and online experiments ensures the system meets business objectives. Data drift, cold-start, and interpretability challenges are managed with continuous monitoring and retraining. This approach unlocks scalable and revenue-impacting product recommendations.